ประเมินโอกาสสูญเสียลูกค้า: Churn Prediction ด้วยข้อมูลและการใช้งานจริง

สวัสดีค่ะเพื่อนๆ (*^▽^*) จากบทความในเมื่อสัปดาห์ที่แล้ว ในเรื่อง นักการตลาดกับ AI: Confusion Matrix และหลักการประเมินประสิทธิภาพ ML ที่ได้มีการยกตัวอย่างในเรื่องของการประเมินประสิทธิภาพ ML Model ที่ใช้ Predict Churn หรือโอกาสในการที่ลูกค้าจะเลิกใช้งาน หรือไม่ซื้อสินค้าของเราต่อ พบว่ามีหลายท่านที่หลังไมค์เข้ามาสอบถามว่า แล้วการประเมิน Churn เนี่ย มีหลักการอย่างไร และข้อมูลที่เขามีอยู่เพียงพอที่จะนำมาวิเคราะห์ และประเมินได้หรือไม่?
เลยเป็นที่มีของบทความนี้ค่ะ ที่นิกจะพาทุกท่านไปลองใช้ข้อมูลจากธุรกิจค้าปลีก ในการประเมินโอกาสที่เกิดการสูญเสียลูกค้าขึ้น ซึ่งที่เลือกใช้ธุรกิจค้าปลีก หรือ Retail เป็นตัวอย่างเพราะว่าธุรกิจนี้ น่าจะเป็นหนึ่งในอุตสาหกรรมที่มีความใกล้ชิดกับทุกคน และสามารถทำให้เห็นภาพ ตลอดจนสามารถนำไปประยุกต์ใช้ในธุรกิจอื่นๆ ได้ง่ายค่ะ,,,, Let’s go (☞゚ヮ゚)☞
Churn คืออะไร? ทำไมถึงสำคัญ?
คำว่า “Churn” ในบริบททางธุรกิจและในสิ่งที่บทความนี้ Focus จะหมายถึง การสูญเสียลูกค้าหรือการที่ลูกค้ายกเลิกใช้บริการหรือไม่ซื้อผลิตภัณฑ์ของแบรนด์นั้นต่อ ซึ่งรวมถึงการที่ลูกค้าเหล่าที่ Churn ไปแล้วจะไม่มีการติดต่อ ตลอดจนไม่ทำธุรกิจกับแบรนด์ หรือบริษัทนั้นอีกต่อไป ซึ่งเหตุการณ์นี้สามารถเกิดขึ้นได้จากเหตุผลหลายประการด้วยกันค่ะ ยกตัวอย่างเช่น Services หรือผลิตภัณฑ์ของแบรนด์ไม่สามารถตอบสนองความต้องการของลูกค้าได้อย่างเหมาะสมอีกต่อไป หรือการที่มีราคาสูงเกินคุณค่าที่ส่งมอบให้ลูกค้า หรือการมีคุณภาพที่ไม่เหมาะสมกับราคา รวมถึง Services ที่ไม่ตอบโจทย์ หรือมีสาเหตุมาจากปัจจัยภายนอก เช่น การแข่งขันในเรื่องราคา และคุณภาพจากคู่แข่ง
การสูญเสียลูกค้า (Churn) นี้ถือว่าเป็นสิ่งที่มีผลกระทบอย่างมากต่อธุรกิจ เนื่องจากการสร้างและรักษาลูกค้าใหม่มักต้องใช้งบประมาณและทรัพยากรมากกว่าการรักษาลูกค้าที่มีอยู่แล้ว การวิเคราะห์และการจัดการกับการสูญเสียลูกค้าจึงเป็นสิ่งสำคัญในธุรกิจและแบรนด์ โดยวิธีการลดอัตราการสูญเสียลูกค้า สามารถเริ่มต้นด้วยการทำความเข้าใจสาเหตุ และพัฒนากลยุทธ์เพื่อปรับปรุงคุณภาพและบริการที่มีอยู่ และรักษาลูกค้าให้อยู่ต่อไป ด้วยการนำเสนอ Promotion หรือแคมเปญที่เหมาะสม

หลักการและขั้นตอนของ Churn Prediction
- การกำหนดโครงสร้างการสร้างแบบจำลอง หรือ ML Model
- พิจารณาข้อมูล (Input Dataset) ที่ต้องมีข้อมูลทั้ง Dependent และ Independent หรือพูดง่ายๆ ต้องมี Features ที่จำเป็นครบถ้วน และมี Label เพื่อใช้สร้างโมเดลค่ะ
- การเลือก Classification Model ที่เหมาะสมกับ Dataset ของเรา
- ประเมินผลโมเดล (ซึ่งส่วนนี้เพื่อนๆ สามารถอ่านได้เพิ่มเติมจากบทความที่นิกพูดถึงในบทนำนะคะ ^^)
เมื่อเพื่อนๆ เห็นภาพรวมของที่มาที่ไป ความสำคัญ และภาพรวมของขั้นตอนการประเมินโอกาสสูญเสียลูกค้ากันแล้ว,, เราก็มาเริ่มทำไปพร้อมกันเลยดีกว่าค่ะ 📈🧐
ซึ่งหลักกการในการทำประเมินโอกาสสูญเสียลูกค้า สามารถทำได้หลายวิธีด้วย และหนึ่งในนั้นก็คือการใช้ ML Model หรือการทำ Predictive analytics และเมื่อเพื่อนๆ เห็นภาพรวมกันแล้ว เรามาดูวิธีเคราะห์โอกาสสูญเสียลูกค้าไปพร้อมๆ กัน ซึ่งสามาถทำได้ตามขั้นตอนดังต่อไปนี้ค่ะ^^
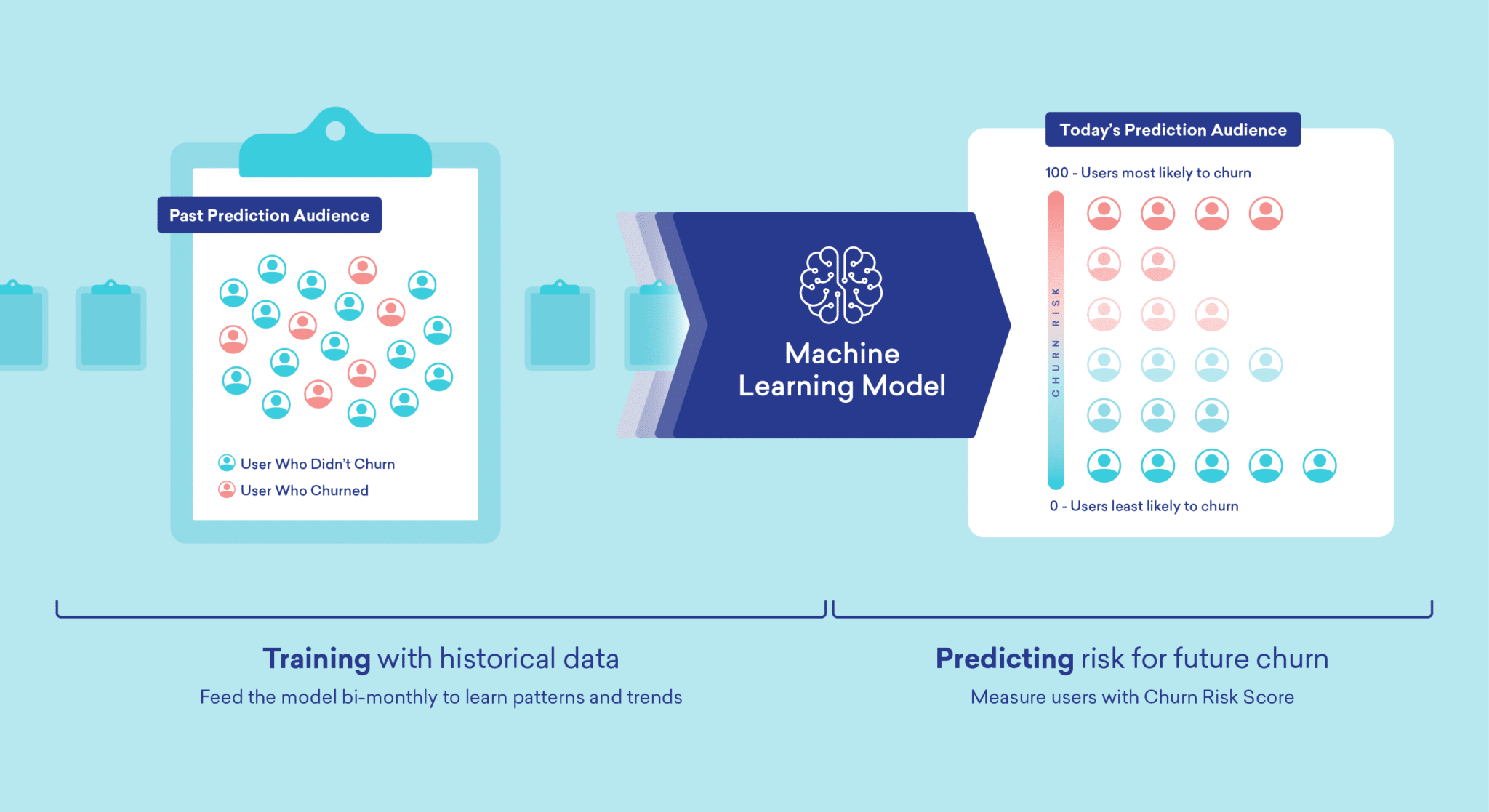
#1 การกำหนดโครงสร้างการสร้างแบบจำลอง หรือ ML Model
ขั้นตอนนี้ ถือเป็นขั้นตอนที่สำคัญมากในการสร้าง Predictive Model โดยวิเคราะห์และเลือกใช้ Model ที่เหมาะสม ซึ่งจะต้องใช้ความเข้าใจในแต่ละโมเดล และลักษณะโครงสร้างของข้อมูลร่วมด้วย ทั้งนี้หากเพื่อนต้องการทำความเข้าใจเพิ่มเติมในการวิเคราะห์ และเตรียมข้อมูลสามารถอ่านเพิ่มเติมได้จากบทความนี้ค่ะ: CPVAI Model – Data Marketing Framework โดยการตลาดวันละตอน และแอบกระซิบว่า สำหรับนิกเอง ขั้นตอนในส่วนของการทำ Data Preparation ถือเป็นหนึ่งในขั้นตอนที่ใช้เวลานานที่สุดขั้นตอนหนึ่งเลยค่ะ 55+ ที่นี้เรามาลองมาทำความเข้าใจในรายละเอียดเพิ่มเติมกันจากข้อมูลธุรกิจค้าปลีกที่เรานำมาทำเป็นตัวอย่างในบทความนี้กัน^^
จากข้อมูลธุรกิจค้าปลีก Example Retail Dataset เราต้องตั้งคำถาม และตอบคำถามต่อไปนี้จากข้อมูลที่เรามีให้ได้ซึ่งหลักการตั้งคำถาม และกำหนดคำจำกัดความมีดังนี้ค่ะ
- เราจะแยกหรือกำหนดประเภทของลูกค้าสำหรับกรณีของเราอย่างไร: ยกตัวอย่างเช่น ลูกค้าเหล่านี้อาจเป็นลูกค้าที่ทำธุรกรรม หรือมีการซื้อสินค้าของธุรกิจ Retail ของเราในช่วง
- เดือนปัจจุบัน หรือ
- 2 เดือนที่ผ่านมา หรือ
- 1 ปีที่ผ่านมา หรือ
- อาจเป็นเงื่อนไขที่ซับซ้อนกว่านั้น เช่น ลูกค้าที่มีการซื้อสินค้าอย่างน้อย 3 เดือนในช่วง 1 ปีที่ผ่านมา =>> นึกภาพออกไหมคะเพื่อนๆ^^
- กำหนดคำจำกัดความของ Churn ที่เราต้องการ Predict: ยกตัวอย่างเช่น ลูกค้าที่มีโอกาสที่เราจะสูญเสียไป คือลูกค้าที่
- จะไม่ทำธุรกรรมใดๆ ใน 1 เดือนถัดไป หรือ
- จะไม่ทำธุรกรรมใดๆ ใน 2 เดือนถัดไป เป็นต้น
ซึ่งขั้นตอนนี้เป็นขั้นตอนที่สำคัญในการสร้างโมเดลการประเมินโอกาสสูญเสียลูกค้า ซึ่งเราควรใช้เวลา และความละเอียดในการทำอย่างถี่ถ้วนค่ะ😎🤓
#2 พิจารณาข้อมูล (Input Dataset)
จาก Dataset นี้ที่มีข้อมูลระหว่างเดือนตุลาคม 2022 – ธันวาคมในปีเดียวกัน ซึ่ง Dataset ที่เรามีคือชุดข้อมูลของการทำธุรกรรมของลูกค้า ซึ่งเราจะนำข้อมูลมาแบ่งเป็น Training Dataset และ Prediction Dataset โดยในแต่ละชุดข้อมูลจะประกอบไปด้วย Features ได้แก่ CustomerID และแบ่งตัวแปรออกเป็น 2 ประเภทหลักคือ Dependent Variable ซึ่งในที่นี้ก็คือ Label ที่เราพิจารณาว่าลูกค้ามีการทำธุรกรรม หรือซื้อสินค้าในส่วนเดือนกันยายน – ตุลาคมหรือไม่ ถ้ามีการซื้อให้เป็น 0 แต่ถ้ามีไม่มีการซื้อให้เป็น 1 (ที่เรากำหนดแบบนี้เพราะว่า เราพิจารณาที่ Churn เป็น Case positive — สำหรับเพื่อนๆ ที่งง ให้กลับไปอ่าน นักการตลาดกับ AI: Confusion Matrix และหลักการประเมินประสิทธิภาพ ML ที่อธิบายเรื่อง Case positive-negative เอาไว้นะคะ^^) และกำหนด Features Independent Variables ตามรายละเอียดของข้อมูลธุรกรรม ได้แก่ ลูกค้าซื้อสินค้าอะไรไปบ้าง, ความถี่ในการซื้อ (Frequency), ระยะเวลาล่าสุดที่ซื้อนับจากวันที่ปัจจุบัน (Recency), ลักษณะการชำระเงิน เป็นต้น ซึ่งในส่วนของ Indepentdent Variable ใช้ข้อมูลในช่วงเดือนกรกฎาคม – สิงหาคม ซึ่งถือเป็นการเอาข้อมูลที่มีการจัดเก็บเอาไว้ มากทำ Prediction โอกาสการเกิดเหตุการณ์สูญเสียลูกค้าค่ะ

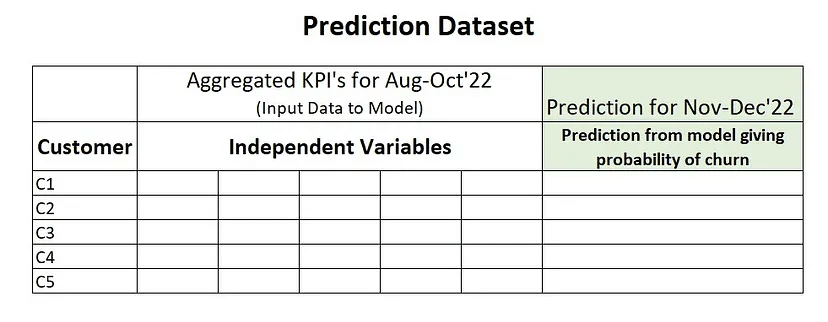
โดยหน้าตาของผลลัพธ์การประเมินโอกาสสูญเสียลูกค้าที่ได้ออกมา จะอยู่ในรูปของความน่าจะเป็นในโอกาสของการเกิด Churn ของลูกค้าแต่ละรายที่แสดงเป็น Customer ID ตามภาพด้านล่างนี้ค่ะ

#3 การเลือก Classification Model ที่เหมาะสมกับ Dataset ของเราในการทำ Churn Prediction
แล้วเราก็มาถึงขั้นตอน(เกือบ)สุดท้ายของการทำ Churn Prediction นั่นคือการเลือก ML Model ให้เหมาะสมกับชุดข้อมูลที่เรามีค่ะ 🧐😎
ซึ่งเราอาจคุณเคยกับการทำ Regression แบบต่างๆ ตลอดจนการทำ Clustering จากบทความก่อนหน้าของการตลาดวันละตอน เพราะฉะนั้นในบทความนี้ นิกเลยอยากแนะนำเพื่อนๆ ให้รู้จักกับโมเดลใหม่ ได้แก่ Decision Tree, Random Forest และ XGBoost ซึ่งสามารถทำงานได้ดีสำหรับชุดข้อมูลที่หลากหลาย โดยแต่ละโมเลมีรายละเอียดดังนี้ค่ะ
- Random Forest: เป็นอัลกอริธึมแบบ Tree ที่ทำงานโดยการสร้างต้นไม้ตัดสินใจจำนวนมาก จากนั้นจึงทำการเฉลี่ยการคาดการณ์ของต้นไม้เหล่านั้น ซึ่งจากการทำแบบนี้มีข้อดีคือสามารถช่วยลดโอกาสการเกิด Overfitting และช่วยเพิ่ม Accuracy โดยรวมของโมเดลได้ค่ะ
- XGBoost: ถือเป็นขั้นกว่าของการทำ Random Forest ที่อาศัยการบูสต์แบบเกรเดียนต์ (Gredient Boost –ไว้จะอธิบาบรายละเอียดในบทความต่อไปนะคะ^^) เพื่อปรับปรุงความแม่นยำของตัวโมเดล
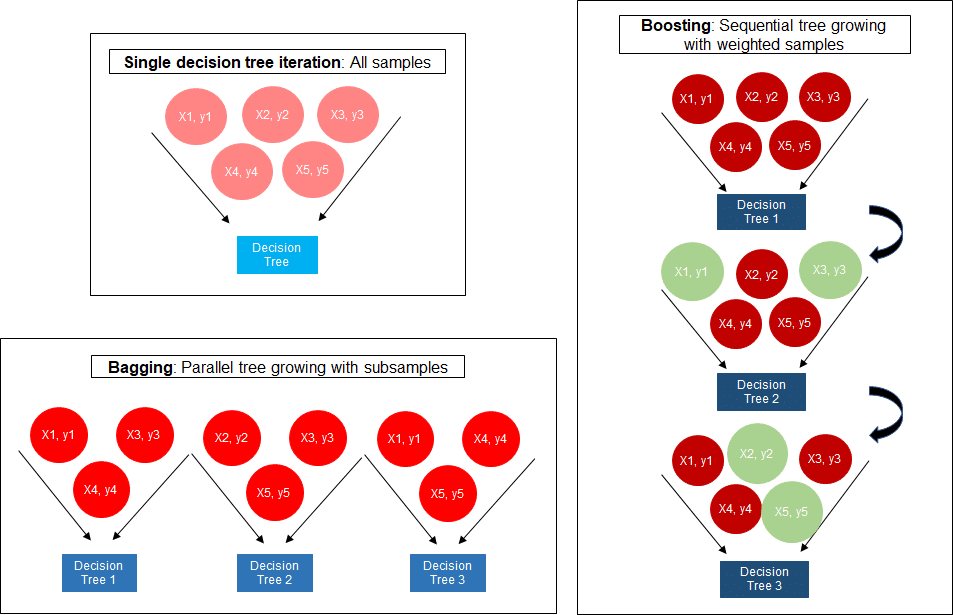
ซึ่งจากตัวโมเดลทั้ง 2 แบบ มีสิ่งที่ต้องระมัดระวังเพิ่มเติมในเรื่องของ “ชุดข้อมูลไม่สมดุล” ซึ่งเกิดจากสิ่งที่เราต้องการพิจารณาคือโอกาสที่ลูกค้าจะ Churn ที่ถือว่ามีปริมาณน้อยมากๆ เมื่อเทียบกับชุดข้อมูลทั้งหมด ทำให้เราต้องมีการจัดการกับ Imbalance พวกนี้ด้วยการทำ Over sampling หรือ Under Sampling เป็นต้นค่ะ (☞゚ヮ゚)☞
#4 ประเมินผลโมเดล: Model Evaluation
และแล้วก็มาถึงในขั้นตอนสุดท้ายซึ่งคือการทำ Model Evaluation กันค่ะ โดย Step แรกที่นิกจะทำก็คือ Cross-validation โดยในส่วนนี้เราทำเพื่อดูว่าโมเดลของเราไม่ได้ Overfiting เป็นอันดับแรก และพิจารณา ROC Curve เพื่อดูประสิทธิภาพโดยรวมของโมเดล และต่อมาเราถึงใช้ Confusion Matrics ในการประเมิน Accuracy, Precision, Recall และ F1-score โดยละเอียดอีกครั้งค่ะ นอกจากนี้วิธีอื่นๆ ที่ได้รับความนิยมเช่นเดียวกัน ได้แก่ Gain Charts และ Lift Charts เป็นเทคนิคที่ค่อนข้างเหมาะสมในการประเมินประสิทธิภาพของ Churn Prediction Model เนื่องจากทั้ง 2 เทคนิคนี้สามารถช่วยให้พวกเราเราเข้าใจว่าโมเดลสามารถคัดเลือกกลุ่มลูกค้าที่มีความเสี่ยงสูงในการลาออกได้ดีเพียงใด (รายละเอียดจะถูกกล่าวถึงในบทความภาคต่อนะคะ 😊💡)


Last but not Least…
จากบทความนี้ คิดว่าเพื่อนๆ นักวิเคราะห์ข้อมูล และนักการตลาดน่าจะเข้าใจถึงหลักการการสร้าง ML Model เพื่อทำการประเมินโอกาสสูญเสียลูกค้า: Churn Prediction ได้ ทั้งในส่วนของท่านที่ทำธุรกิจประเภท Retail อยู่แล้ว รวมถึงธุรกิจประเภทอื่นๆ โดยสามารถเริ่มได้จากการพิจารณาข้อมูล วิเคราะห์หาว่าข้อมูลเราเหมาะกับโมเดลไหน ตลอดจนการทำ Model Evaluation และสำหรับเพื่อนท่านไหนที่ต้องการอ่านเรื่องการทำ Model Evaluation เพิ่มเติมสามารถอ่านได้จากบทความนี้ค่ะ =>



{kind=link}