นักการตลาดกับ AI: Confusion Matrix และหลักการประเมินประสิทธิภาพ ML Model

สวัสดีค่ะทุกท่าน (^∀^●)ノシ เมื่อสัปดาห์ที่แล้ว นิกได้มีโอกาสไปเล่าเรื่องเกี่ยวกับการใช้ Machine Learning (ML) Model ให้วิศวกร และ Domain Expert ด้านอื่นๆ ฟัง เพื่อหาแนวทางร่วมกันในการทำ CRM ให้ตอบโจทย์ความต้องการของลูกค้า,,,,ผลปรากกฏว่า มีหัวข้อหนึ่งที่สร้างความมึนงงมากๆ ให้กับผู้ฟัง นั่นคือเรื่องของหลักการประเมินประสิทธิภาพของ ML Model ด้วย Confusion Matrix,,,,ซึ่งก็ตามชื่อค่ะ Confuse จริงๆ
นิกเลยคิดว่าน่าจะเป็นประโยชน์กับเพื่อนๆ นักการตลาดในยุคปัจจุบัน ซึ่งถือเป็น Domain Expert ด้าน Marketing ที่มีการใช้ ML Model ในการวิเคราะห์ และสนับสนุนการตลาด Digital Marketing หลากหลายรูปแบบ เช่น ใช้ในการประเมินลูกค้า, จัดกลุ่มลูกค้า, หาความสัมพันธ์ของพฤติกรรมการบริโภคกับปัจจัยอื่นๆ หรือการออกแบบแคมเปญ เป็นต้น ซึ่งแน่นอนว่า นอกจากเราจะต้องมีความเข้าใจเบื้องต้นในเรื่องของการเลือก ML Model ให้เหมาะสมกับชุดข้อมูลแล้ว สิ่งสำคัญอีกประการหนึ่งก็คือหลักการประเมินประสิทธิภาพของ ML Model ที่เราเลือกใช้งาน ซึ่งเพื่อนๆ จะได้อ่านกันในบทความนี้นั่นเองค่ะ 🧐🔎
Confusion Matrix คืออะไร?
นิยามของคำว่า Matrix
ก่อนจะพูดถึง Confusion Matrix นิกขอพาเพื่อนๆ ย้อนกลับไปในตอนที่เราเรียนคณิตศาสตร์ ม.ปลาย ในเรื่องของ Matrix กันค่ะ (づ ̄ 3 ̄)づ โดยเมทริกซ์เป็นอาร์เรย์หลายมิติ ที่สามารถมีได้ตั้งแต่ 2 มิติหรือมากกว่านั้น ซึ่งปกติจะถูกเรียงในรูปแบบของตาราง 2 มิติที่มีแถว (row) และหลัก (column) และแต่ละองค์ประกอบในเมทริกซ์จะต้องเป็นจำนวนจริง (จำนวนจริงหรือ Real number สามารถเป็นได้ทั้งจำนวนเต็ม และทศนิยม) หรืออาจเป็นตัวเลขใด ๆ ที่สามารถใช้ในการดำเนินการทางคณิตศาสตร์ได้ ซึ่งเมทริกซ์ A ที่มีขนาด m x n จะถูกแสดงด้วยสัญลักษณ์ A = [ ]m x n ตามภาพค่ะ
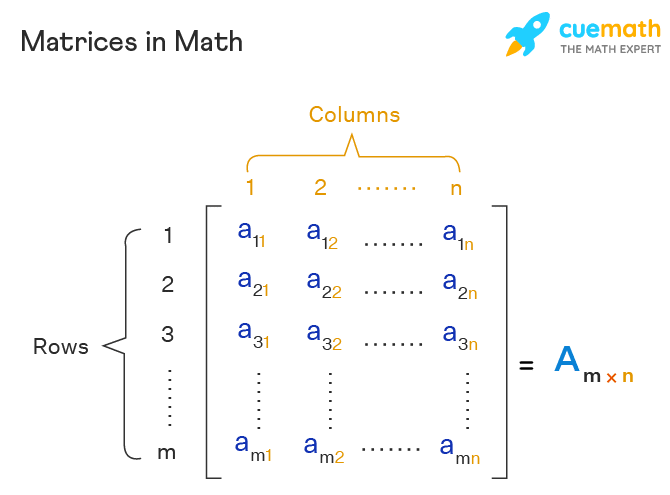
ซึ่งหน้าตาของ Confusion matrix ที่เรากำลังจะพูดถึงก็จะมีโครงสร้างเช่นเดียวกับเมทริกซ์ทางคณิตศาสตร์ ที่มีขนาดหรือมิติเท่ากับ 2X2 และมักถูกเขียนให้อยู่ในรูปแบบของตารางค่ะ^^
องค์ประกอบในตาราง Confusion matrix
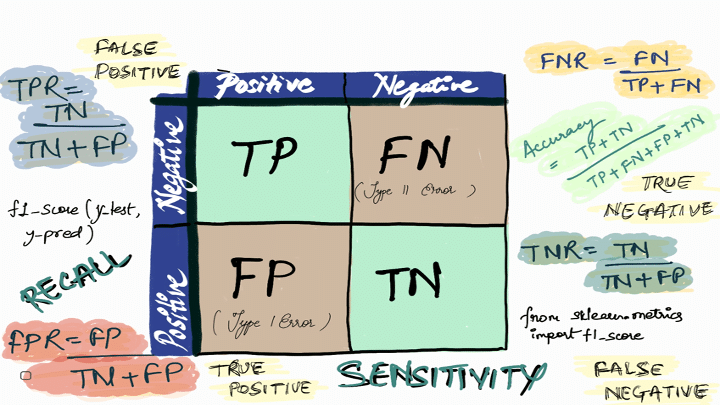
เราจึงสามารถสรุปได้ว่า Confusion matrix คือตารางที่ใช้ประเมินประสิทธิภาพของ Classification ML รูปแบบต่างๆ ร่วมกับชุดข้อมูลทดสอบที่เราทราบค่าหรือผลลัพธ์ที่แท้จริงแล้ว ด้วยการประเมินค่าจริง (Actual value) เทียบกับค่าที่ได้จากผลลัพธ์ของ ML model หรือค่าที่คาดการณ์ไว้ (Predicted Value) แล้วสรุปค่าออกมาในรูปแบบของตารางเมทริกซ์ที่ประกอบด้วยค่า True negative (TN). False positive (FP), False negative (FN) และ True positive (TP) ซึ่งแต่ละค่ามีความหมายดังนี้ค่ะ 😃🚀
- True Positives (TP): คือจำนวนข้อมูลที่ถูกจำแนกได้อย่างถูกต้องในกลุ่มของประเภทที่พวกเราต้องการ (Positive class) หรือกลุ่มที่เราสนใจ ในกรณีนี้คือข้อมูลที่ถูกทำนายว่าเป็น Positive หรือเป็นแบบนี้จริง และข้อมูลจริงก็เป็นแบบนี้จริงๆ ด้วย หรือก็คือการทำนายถูกต้องว่าสิ่งที่เราประเมินไว้จะเกิดขึ้นค่ะ
- True Negatives (TN): คือจำนวนข้อมูลที่ถูกจำแนกถูกต้องในกลุ่มของประเภทที่ไม่ใช่เป้าหมาย (Negative class) หรือกลุ่มที่เราไม่สนใจ ในกรณีนี้คือข้อมูลที่ถูกทำนายว่าเป็น Negative และข้อมูลจริงก็เป็น Negative นั่นคือการทำนายถูกต้องว่าไม่เป็นสิ่งที่เราประเมินไว้
- False Positives (FP): คือจำนวนข้อมูลที่ถูกทำนายผิดในกลุ่มของประเภทที่เราสนใจ ในกรณีนี้คือข้อมูลที่ถูกทำนายว่าเป็น Positive แต่ข้อมูลจริงกลับเป็น Negative นั่นคือการทำนายผิดว่าเป็นสิ่งที่เราทำการประเมินไว้ หรือ False นั่นเองค่ะ
- False Negatives (FN): คือจำนวนข้อมูลที่ถูกจำแนกผิดในกลุ่มของประเภทที่เราไม่สนใจ ในกรณีนี้คือข้อมูลที่ถูกทำนายว่าเป็น Negative แต่ข้อมูลจริงกลับเป็น Positive นั่นคือการทำนายผิดว่าไม่เป็นสิ่งที่เราประเมินไว้ค่ะ
เป็นอย่างไรกันบ้างคะ,,,,อ่านแล้วก็ Confuse ตามชื่อแน่ๆ เลย 😂😂 เพราะฉะนั้นนิกให้ทริคง่ายๆ ค่ะว่า คำว่า True หรือ False ที่อยู่ข้างหน้าเป็นการบอกว่าสิ่งที่ ML Model ของเราประเมินไว้ถูกหรือผิดเมื่อเทียบกับข้อมูลจริง ส่วนคำว่า Positive หรือ Negative หมายถึงผลลัพธ์ที่ได้จาก ML Model ค่ะ
ชนิดของ Error: Type1 (FP) และ Type2 (FN)
โดยสิ่งที่เราชาวนักการตลาดต้องเข้าใจเพิ่มเติม เพื่อการสื่อสารที่ถูกต้องกับคนที่ทำ ML Model ให้เราหรือทีม Data Analyst ก็คือเรื่องชนิดของ Error ที่แบ่งเป็น 2 ประเภทคือ Type1 Error (False Positive – FP) และ Type2 Error (False Negative – FN) ซึ่งมีรายละเอียดดังต่อไปนี้ค่ะ
- Type 1 Error (False Positive – FP):
- Type 1 Error จะเกิดขึ้นก็ต่อเมื่อ ML Model ทำการ Predict ว่าลูกค้า หรือกลุ่มเป้าหมายของการตลาดนั้นเป็นกลุ่มเป้าหมายที่เราต้องการ (Positive) แต่ในความจริงแล้วลูกค้ากลุ่มนี้กลับไม่ได้เป็นกลุ่มเป้าหมาย ซึ่งหมายความว่าจะเกิดความผิดพลาด เมื่อเราตัดสินใจว่าลูกค้ากลุ่มนั้นมีความสนใจ หรือจะตอบสนองต่อแคมเปญ แต่ลูกค้ากลับไม่สนใจ เพราะเราส่งแคมเปญไม่ถูกกลุ่ม
- ยกตัวอย่างเช่น การส่งอีเมลโปรโมชันหรือแคมเปญไปยังลูกค้า ที่ ML Model ทำการ Predict ไว้ว่าลูกค้าจะตอบสนอง แต่กลับไม่ได้รับความสนใจจากลูกค้าดังกล่าว ซึ่งผลลัพธ์ในลักษณะนี้จะถือเป็น Type1 Error ที่ทำให้เราเสียเวลา และทรัพยากรในการติดต่อเพื่อส่งแคมเปญอย่างสูญเปล่าค่ะ
- Type 2 Error (False Negative – FN):
- Type 2 Error จะเกิดขึ้นก็ต่อเมื่อ ML Model ทำการ Predict ว่าลูกค้า หรือกลุ่มเป้าหมายของการตลาดนั้นไม่ใช่กลุ่มเป้าหมายที่เราต้องการ (Negative) แต่ในความจริงแล้วลูกค้ากลุ่มนี้เป็นกลุ่มเป้าหมายที่เรากำลังสนใจอยู่
- ยกตัวอย่างเช่น การที่ Model บอกว่าลูกค้ากลุ่มนี้ไม่ใช่กลุ่มเป้าหมายนะ แต่แท้จริงแล้วพวกเขากลับมีแนวโน้มที่จะตอบรับกับแคมเปญ หรือซื้อสินค้าเพิ่มเติม ซึ่งสิ่งนี้เองที่ส่งผลให้เราไม่ได้ทำการตลาดที่เหมาะสม หรือเสนอแคมเปญที่ดีเพียงพอให้กับกลุ่มนี้ ทำให้เสียโอกาสในการเพิ่มยอดขาย และการตลาด
การประเมินประสิทธิภาพของ ML Model ด้วย Confusion Matrix
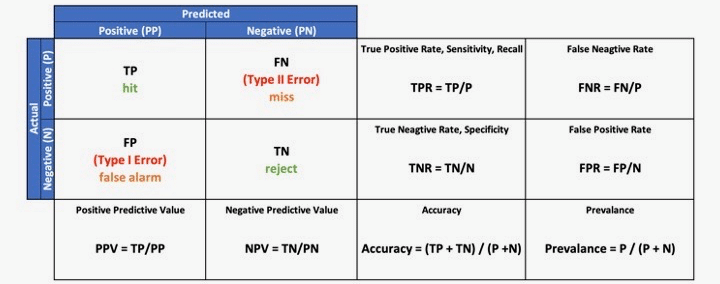
ทีนี้ก็มาถึงส่วนสำคัญของบทความค่ะ นั่นคือเรื่องของการนำค่าที่อยู่ในตาราง Confusion Matrix ไปใช้ประเมินประสิทธิภาพของ ML Model ผ่านการคำนวณค่าพารามิเตอร์ที่ใช้ประเมิน 4 ค่าได้แก่ ความแม่นยำ (Accuracy), ความแม่นยำในการทำนายในกลุ่มเป้าหมาย (Precision), ความสามารถในการตรวจจับเหตุการณ์ที่เราสนใจ (Recall), และค่า F1-Score โดยการคำนวณมีสมการที่ใช้ดังต่อไปนี้ค่ะ

Accuracy: ความแม่นยำ
ค่า Accuracy คือค่าความแม่นยำเป็นสัดส่วนของข้อมูลทั้งหมดที่ถูกจำแนกถูกต้องโดยระบบ ซึ่งคำนวณได้จาก
จำนวน (True Positives (TP) + True Negatives (TN))/ จำนวนทั้งหมด
ซึ่งค่า Accuracy จะใช้บอกถึงความสามารถของ Model โดยร่วมในการ Predict ทั้งในกรณี positive และ negative
Precision: ความแม่นยำในการประเมินในกลุ่มเป้าหมาย
Precision คือค่าความแม่นยำในการทำนายในกลุ่มเป้าหมายหรือพิจารณาเฉพาะที่เป็น True Positives (TP) โดยสามารถคำนวณได้จาก
จำนวน True Positives (TP)/ จำนวน (True Positives (TP) + False Positives (FP))
ซึ่งค่า Precision จะใช้พิจารณาถึงความสามารถของระบบในการทำนาย positive โดยเฉพาะค่ะ
Recall: ความสามารถในการตรวจจับเหตุการณ์ที่เราสนใจ
Recall คือความสามารถของ Model ในการ Predict หรือระบุสิ่งที่เราสนใจ ซึ่งคือสัดส่วนของ True Positives (TP) กับข้อมูลที่จริงๆ เป็น Positive ทั้งหมด โดยสามารถคำนวณได้จาก
จำนวน True Positives (TP)/ จำนวน (True Positives (TP) + False Negative (FN))
โดยที่ Recall จะใช้ประเมินความประสิทธิภาพในการ Predict ของโมเดลในการประเมินผล Positive ในกรณีที่มี Positive จริง
F1-Score: ความสมดุลระหว่างความแม่นยำในการทำนายในกลุ่มเป้าหมาย
F1-Score คือค่าความสมดุลระหว่างความแม่นยำในการทำนายในกลุ่มเป้าหมาย (Precision) และความสามารถในการตรวจจับเหตุการณ์ที่เราสนใจ (Recall) โดยสามารถคำนวณได้จาก
2x(PrecisionxRecall)/ 2x(Precision + Recall)
โดยที่ค่า F1-Score มีค่าสูงเมื่อทั้งความแม่นยำในการ Predict กลุ่มเป้าหมาย และความสามารถในการประเมิน Positive มีค่าสูงพร้อมกัน ซึ่งเป็นสิ่งที่แสดงถึงประสิทธิภาพโดยรวมของ ML Model
ป.ล. นิกขอแถมภาพด้านล่าง เพื่อให้เพื่อนๆ เห็นภาพในการคำนวณค่าต่างๆ ข้างต้นด้วยสมการได้อย่างชัดเจนยิ่งขึ้นค่ะ โดยภาพนี้เป็นตัวอย่างของการประเมินว่าภาพใดเป็นแมว (แมวเป็น Positive และเจ้าตูบเป็น Negative ค่ะ)
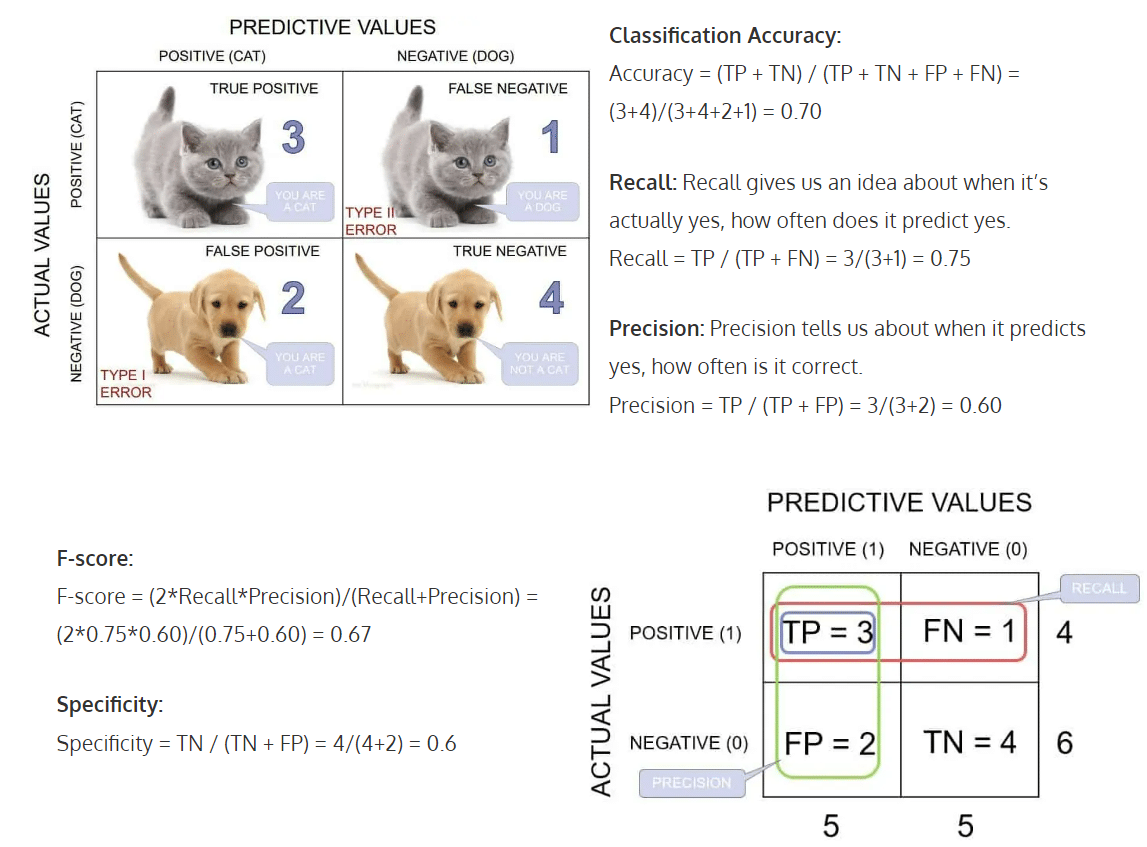
ตัวอย่างการใช้ Confusion Matrix กับการประเมินประสิทธิภาพ ML Model ทางการตลาด
ซึ่งเมื่อเพื่อนๆ มีความเข้าใจในเรื่องของการคำนวณค่าที่ใช้ประเมินความแม่นยำของ ML โมเดลด้วย Confusion Matrix แล้ว พาร์ทสุดท้ายนี้นิกขออนุญาตยกตัวอย่างงานด้านการตลาดที่มีการใช้ ML Model ในการวิเคราะห์ลูกค้าที่มีแนวโน้มจะยกเลิกการใช้บริการ (Churn) ซึ่งเป็นกลุ่ม Critical เพื่อมาทดลองใช้หลักการประเมินประสิทธิภาพดังกล่าวกันค่ะ^^
โดยการใช้ Confusion matrix เพื่อประเมินผลการ Predict ของโมเดลว่าลูกค้าคนไหน อาจจะยกเลิกการใช้บริการ/ไม่ซื้อสินค้าของเราในอนาคต ใช้ในการตอบโจทย์/ยืนยันให้ได้ว่าหากโมเดลแม่นยำ และผลการ Predict ถูกต้องแล้ว พวกเราก็ควรจัดกิจกรรม CRM ที่เหมาะสมเพิ่มความพึงพอใจ และลดความเสี่ยงให้กับลูกค้าที่มีแนวโน้มจะ Churn ได้อย่างมีประสิทธิภาพต่อไป,,,,, ว่าแล้วก็มาลองดูตัวอย่างนี้กันค่ะ (∩^o^)⊃━☆
เริ่มจากการนับจำนวนค่าใน Confusion Matrix ทั้ง 4 ค่าดังนี้
- True Positives (TP): คือจำนวนของลูกค้าที่ถูก Predict ว่าจะ Churn และเขาก็ Churn จริง ๆ และจากการที่เราสามารถระบุลูกค้าที่จะ Churn ได้ทำให้เราสามารถหา CRM ที่เหมาะสมเพื่อรักษาความพึงพอใจ หรือลดความเสี่ยงของลูกค้าในกลุ่มนี้ได้ค่ะ
- True Negatives (TN): คือจำนวนของลูกค้าที่ถูก Predict ว่าจะไม่ Churn และเขาก็ไม่ Churn จริงๆ ซึ่งคือลูกค้าที่ยังคงใช้บริการอย่างปกติ
- False Positives (FP): คือจำนวนของลูกค้าที่ถูก Predict ว่าจะ Churn แต่จริง ๆ แล้วไม่ Churn ซึ่งนี่เป็นความผิดพลาดของ ML Model ซึ่งส่วนนี้มีผลเสียที่ อาจก่อให้เกิดค่าใช้จ่ายที่ไม่จำเป็นในการรักษาลูกค้ากลุ่มนี้เอาไว้ค่ะ
- False Negatives (FN): คือจำนวนของลูกค้าที่ถูก Predict ว่าจะไม่ Churn แต่จริง ๆ แล้ว Churn ซึ่งส่วนตัวนิกมองว่านี่เป็นความผิดพลาดของโมเดลที่ร้ายแรงที่สุด เพราะทำให้เราพลาดโอกาสที่จะจัดแคมเปญ หรือโปรโมชันเพื่อรักษาลูกค้ากลุ่มนี้เอาไว้
และหลังจากที่เราได้ค่า TP TN FP และ FN มาครบถ้วนแล้ว เราก็จะมาเข้าสู่การคำนวณ Accuracy, Presision, Recall และ F1-score กันต่อสมการในพาร์ทก่อนหน้า และเมื่อได้ค่าออกมาแล้ว แต่ละค่าสามารถตีความได้ดังนี้ค่ะ
- Accuracy: ค่า Accuracy สูงหมายความว่าตัวโมเดลมีประสิทธิภาพในการ Predict โดยรวมค่อนข้างดี ทั้งกรณี Churn และไม่ Churn
- Precision (ความแม่นยำของการทำนาย Churn): ค่า Precision สูงแสดงว่าตัว ML Model มีความแม่นยำในการ Predict ในกรณีที่จะเกิด Churn ค่อนข้างสูง
- Recall (ความสามารถในการตรวจจับ Churn): ค่า recall สูงแสดงว่าระบบมีความสามารถในการตรวจจับลูกค้าที่จะ Churn และ Churn จริงๆ ได้ดี
- F1-Score (ค่า F1): เป็นค่าความสมดุลระหว่าง precision และ recall ซึ่งหมายความว่าหากค่า F1 มีค่าสูง ทั้ง precision และ recall มีค่าสูงพร้อมกันหรือมีความสมดุลนั่นเองค่ะ^^

Last but not Least…
เพื่อนๆ จะเห็นว่าจากเดิมที่หากเราพูดถึงการประเมินความแม่นยำของ ML Model เราจะใช้เพียงคำว่า Accuracy แต่ตอนนี้เราสามารถวิเคราะห์เพิ่มเติมด้วยค่าที่คำนวณ จากการใช้ Confusion Matrix ซึ่งแต่ละค่าท้้ง Accuracy, Presision, Recall และ F1-score ล้วนมีความเหมาะสมแตกต่างกันออกไป ขึ้นอยู่กับ Case ของลูกค้าที่เราต้องการประเมิน เช่นการประเมินลูกค้าที่จะ Churn หรือการทำ Segment ของลูกค้าที่เหมาะสมกับแคมเปญต่างๆ ซึ่งจากเราเข้าในเรื่องการประเมินประสิทธิภาพของ ML Model จะทำให้เราสามารถปรับปรุงประสิทธิภาพของโมเดลในทิศทางที่ถูกต้องได้ และสามารถสื่อสารกับส่วนที่เกี่ยวข้องได้อย่างชัดเจนยิ่งขึ้นแน่นอนค่ะ (☞゚ヮ゚)☞ แล้วพบกันใหม่ในบทความต่อไปนะคะ^^



{kind=link}