Linear Algebra คืออะไร นักการตลาดต้องรู้ไหม => Let’s go Data driven

สวัสดีค่ะทุกท่าน บทความนี้เป็นหนึ่งในหัวข้อที่นิกอยากเขียน และชั่งใจ บวก ลบ คูณ หาร มานานมากๆ ว่าจะเขียนดีไหม เพราะค่อนข้างเป็นเนื้อหาที่เกี่ยวข้องกับ Math แบบค่อนข้างจริงจัง แต่หลังจากที่พบว่าช่วงหลังนี้มีการเทรนด์การเข้ามาของ Generative AI ทำให้นักการตลาดอย่างพวกเรามีความเกี่ยวข้อง และจำเป็นต้องมีองค์ความรู้ในเรื่องที่เกี่ยวกับ AI และ Machine Learning เชิงลึกมากยิ่งขึ้นอย่างหลีกเลี่ยงไม่ได้ อย่างน้อยก็เพื่อให้ใช้งาน Gen AI เหล่านั้นได้อย่างเต็มประสิทธิภาพมากยิ่งขึ้น หรือสื่อสารกับ ML Engineer/ Data Analyst ได้อย่างตรงจุดตรงประเด็นมากขึ้น =>> เกริ่นมาซะยาวเลย^^ บทความนี้นิกเลยขอแนะนำให้ทุกท่านรู้จักกับ Linear Algebra คณิตศาสตร์ที่(คิดว่า)พวกเราควรรู้ เพื่อให้การใช้งานทุก ML Model เป็นไปอย่างที่เราต้องการ โดยเฉพาะอย่างยิ่ง ในงานด้านการตลาดค่ะ,, Let’s go (☞゚ヮ゚)☞
Linear Algebra คืออะไร?
Linear Algebra หรือ “พีชคณิตเชิงเส้น” ถือเป็นรากฐานและพื้นฐานในการสร้างและพัฒนา ML Model ในงานด้านการวิเคราะห์ข้อมูล หรือ “Data Science” โดยเฉพาะการวิเคราะห์ข้อมูลที่มีความหลากหลาย เช่น ข้อมูลของลูกค้า และ Transaction ต่างๆ ในการซื้อขาย หรือการใช้งานแพลตฟอร์ม เพราะในโลกของการทำ Data driven marketing มีแนวคิดที่ทำให้โมเดล Machine Learning สามารถวิเคราะห์ และนำเสนอข้อสรุปของข้อมูลได้อย่างมีประสิทธิภาพ
พีชคณิตเชิงเส้น เป็นสาขาของคณิตศาสตร์ที่ศึกษาเรื่องของเวกเตอร์, สเปซเวกเตอร์ และเมทริกซ์ (อย่าพึ่งตกในกันนะคะ,,,, คำศัพท์ประหลาดพวกนี้ไม่ยากอย่างที่คิดค่ะ) ซึ่งพีชคณิตเชิงเส้นเป็นเครื่องมือที่มีความสำคัญสำหรับงานในหลายสาขาของวิทยาศาสตร์ เช่น ฟิสิกส์, วิศวกรรม รวมถึงงานด้าน Data Science
ซึ่งทั้งการคำนวณเรื่อง เวกเตอร์, สเปซเวกเตอร์ และเมทริกซ์ ที่อยู่ใน “พีชคณิตเชิงเส้น” จะถูกนำมาใช้เมื่อเราต้องการจัดการกับข้อมูลที่มีคุณสมบัติหรือ Feature เป็นจำนวนมาก เช่นข้อมูล Transaction ของลูกค้าที่มี Features ทั้ง ชื่อ อายุ เวลาการซื้อ ราคา จำนวนชิ้นที่ซื้อ และอื่นๆ อีกมากมายตามแต่เราจะเก็บข้อมูลมา (ซึ่งเพื่อนๆ ลองนึกภาพตามนะคะว่า เราไม่สามารถพล๊อตกราฟลงแกน X, Y ตามปกติได้แน่ๆ)
และจากการที่มี Features จำนวนมาในข้อมูลนี่เอง ที่ทำให้การแสดงผล และการตัดสินใจด้วยตาเปล่าๆ ของเราเป็นไปได้ยาก หรือเป็นไปไม่ได้เลย เพราะเราอาจเข้าใจง่ายเมื่อเห็นข้อมูลในรูปแบบ 2 หรือ 3 มิติ แต่ข้อมูลในโลกจริงมีมิติมากมาย และยากต่อการแสดงผล
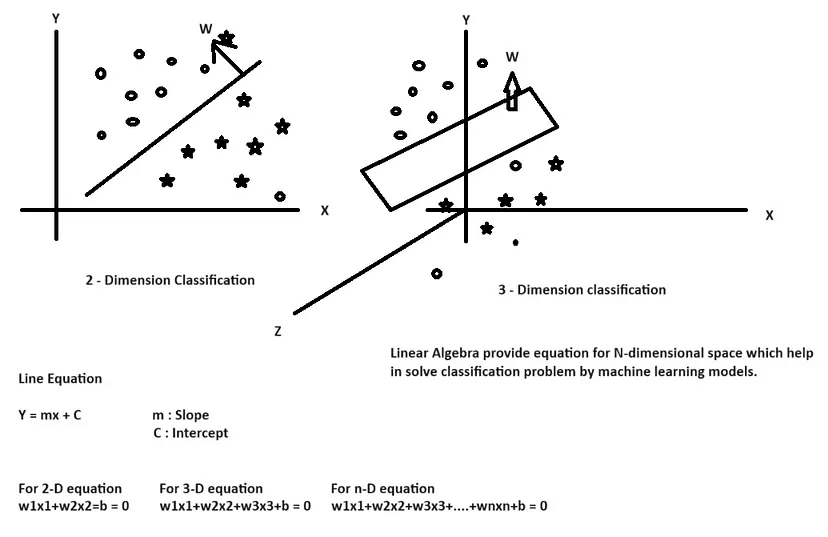
เราจึงต้องนำ Linear Algebra เข้ามาใช้ เพื่อช่วยให้เราสามารถสร้างเส้นแบ่ง หรือพื้นที่ตัดสินใจในข้อมูลมิติสูงได้ ซึ่งส่วนนี้เองที่จะช่วยให้การแยกหรือวิเคราะห์ข้อมูลมีความแม่นยำมากยิ่งขึ้น
ยกตัวอย่างจากงานด้านการตลาด เช่น,,,,
เมื่อบริษัท Retail Market รายหนึ่งต้องการวิเคราะห์พฤติกรรมการซื้อของลูกค้าจากข้อมูลต่างๆ เช่น อายุ, เพศ, รายได้, การซื้อในอดีต และอื่นๆ มีมิติ (Features) จำนวนทั้งหมด 50 มิติ การใช้ Linear Algebra จะช่วยให้เราสามารถสร้างแบบจำลองที่สามารถคาดการณ์แนวโน้มการซื้อของลูกค้าแต่ละคนได้ โดยไม่ต้องเห็นข้อมูลทั้งหมดในรูปแบบที่ซับซ้อน =>> คือพูดง่ายๆ ค่ะว่า เราไม่ต้องสร้างกราฟที่มีจำนวน 50 แกนออกมา (ซึ่งเอาจริงๆ ก็เป็นไปไม่ได้หรอกค่ะ 🤣🤣)
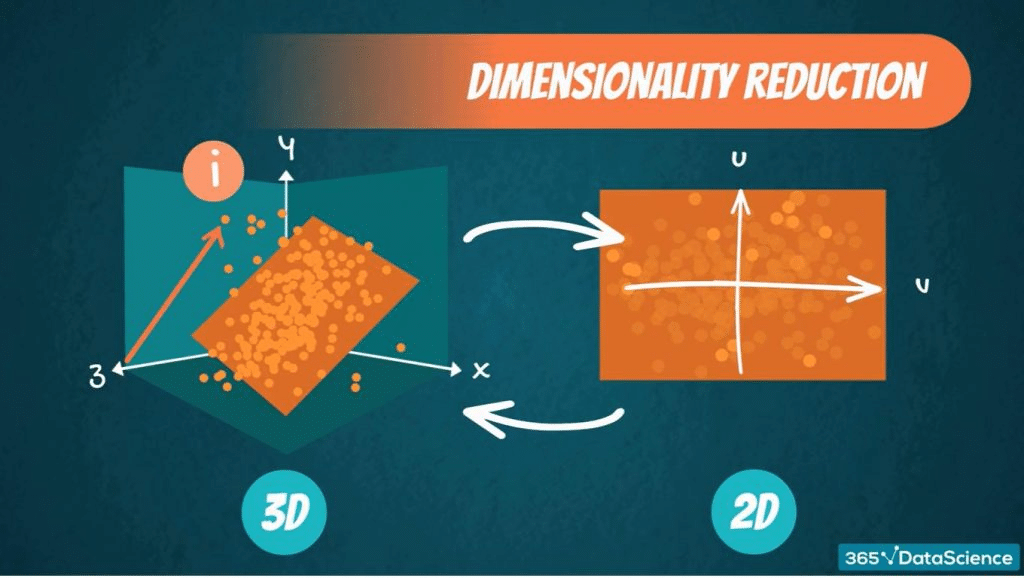
โดยหน้าตาของสิ่งที่ พีชคณิตเชิงเส้น จะทำ และมองเห็นเป็นดังภาพด้านล่างนี้ค่ะ

ซึ่งก็นั่นแหละค่ะทุกท่าน,,,, ตาเปล่าของเราไม่สามารถวิเคราะห์สิ่งนี้ได้แน่ๆ เราจึงต้องใช้ เวกเตอร์, สเปซเวกเตอร์ และเมทริกซ์ ของพีชคณิตเชิงเส้นมาช่วยตามขั้นตอนต่างๆ ของการวิเคราะห์ข้อมูล ดังนี้ค่ะ
Linear Algebra ในการทำ Data Representation
ในส่วนนี้คือการใช้พีชคณิตเชิงเส้นในการทำ Representation หรือการแทนที่ข้อมูลที่เข้าใจยากๆ โดยให้เขียนแทนข้อมูลในรูปแบบทางคณิตศาสตร์ ผ่านการแปลงข้อมูลเป็นเวกเตอร์และเมทริกซ์ ซึ่งทำให้เราสามารถจัดการ และดำเนินการกับข้อมูลได้อย่างมีประสิทธิภาพ และเข้าใจง่ายมากยิ่งขึ้น
เช่น เมื่อเราต้องการวิเคราะห์ข้อมูลลูกค้าจากหลายแหล่ง เช่น จากข้อมูลการซื้อ, ข้อมูลการค้นหา และการเข้าถึงเว็บไซต์ต่างๆ ของลูกค้า เป็นต้น
โดยหลักการของพีชคณิตเชิงเส้นที่เราจะนำมาใช้ “แทน” ข้อมูลดั้งเดิม มีดังต่อไปนี้ค่ะ
- เวกเตอร์ – ใช้แทนจุดของข้อมูลเดียว เช่น การซื้อสินค้าของลูกค้าคนหนึ่งในวันนั้น
- เมทริกซ์ – ใช้แทนข้อมูลทั้งหมดของลูกค้า เช่น การซื้อ, การค้นหา, และการเข้าถึงเว็บไซต์ ซึ่งสิ่งนี้ที่พวกเราเรียกว่า Dataset นั่นเองค่ะ
- การดำเนินการเมทริกซ์ (Matrix Operation) – ช่วยในการแปลงข้อมูล หรือสร้างแบบจำลองข้อมูล
- การทรานส์โพสเมทริกซ์ (Matrix Transpose,, คณิตศาสตร์ ม.4 กลับมาอีกแล้ว🤣🤣) – สลับแถวกับคอลัมน์ ซึ่งมีประโยชน์เมื่อต้องการวิเคราะห์ข้อมูลในมุมต่างๆ
- เมทริกซ์แบบ Sparse – ใช้แทนการวิเคราะห์ข้อความ หรือข้อมูลที่มีค่าส่วนใหญ่เป็นศูนย์ เช่น การวิเคราะห์รีวิวสินค้าจากลูกค้า
- เมทริกซ์แบบ Dense – ใช้แทนเมื่อข้อมูลมีค่าที่หลากหลาย และเน้นความเร็วในการประมวลผล
- เมทริกซ์แบบ Singular – ใช้เมื่อเราต้องการเมทริกซ์ที่ไม่สามารถหาค่าย้อนกลับได้ มีผลต่อการแก้ปัญหาบางรูปแบบในการวิเคราะห์ข้อมูล

Linear Algebra ในการทำ Data Preprocessing (ขั้นตอนการเตรียมข้อมูล)
ขั้นตอนนี้จะเป็นการใช้พีชคณิตเชิงเส้นในการปรับเปลี่ยนการดำเนินการต่างๆ กับข้อมูลดิบ (Raw data) เพื่อให้ข้อมูลนั้นเหมาะสมกับการวิเคราะห์ หรือการสร้างแบบจำลองทางคณิตศาสตร์ หรือการใช้งานอื่นๆ ต่อ โดยการดำเนินการดังต่อไปนี้ค่ะ
- การปรับมาตราส่วนข้อมูล (Data Scaling) – ทำให้ข้อมูลที่เราได้มาอยู่ในมาตราส่วนเดียวกัน และสามารถวิเคราะห์หรือสร้างแบบจำลองได้ เช่น เวลาที่เราได้ข้อมูลอายุ ร่วมกับข้อมูลของรายได้ของลูกค้ามา เพื่อนๆ จะสังเกตุเห็นไหมคะว่า ค่าของตัวเลขทั้ง 2 ชุด ห่างกันมาก กล่าวคือ อายุเป็นตัวเลขน้อยๆ ส่วนรายได้มีค่ามากกว่าหลายเท่า ซึ่งในส่วนนี้เองค่ะ ที่จะทำให้การวิเคราะห์ หรือสร้าง ML Model ต่อเพื้ยนได้ เราจึงต้องทำ Data Scaling ก่อนนั่นเองค่ะ ╰(*°▽°*)╯
- การปรับปรุงข้อมูล (Normalization) – ปรับข้อมูลให้อยู่ในช่วง 0 ถึง 1 เพื่อทำให้เปรียบเทียบได้ง่ายขึ้น
- การปรับมาตรฐานข้อมูล (Standardization) – ปรับข้อมูลให้มีค่าเฉลี่ยเป็น 0 และส่วนเบี่ยงเบนมาตรฐานเป็น 1 ทำให้ข้อมูลมีการกระจายอยู่ในรูปแบบเดียวกัน
- การปรับข้อมูลแบบ Robust Scaling – ปรับข้อมูลโดยใช้ค่ามัธยฐาน และช่วงระหว่างควอไทล์ เน้นที่ความไม่ไวต่อข้อมูลที่เป็น outliers หรือหมายถึงการที่มีข้อมูลที่อยู่ดีๆ ก็มีค่ากระโดดไปจากเพื่อนๆ นั่นเองค่ะ

*ค่ามัธยฐาน คือค่าที่อยู่กึ่งกลางของข้อมูลนะคะ
การใช้ “พีชคณิตเชิงเส้น” ในการทำ Feature Engineering
ส่วนต่อมาคือการสร้างคุณสมบัติใหม่ (สร้าง Features ใหม่) หรือการเปลี่ยนแปลงคุณสมบัติเดิมเพื่อเพิ่มประสิทธิภาพการทำงานของ AI หรือ ML Model ซึ่งมีรายละเอียดการใช้งานในรูปแบบการวิเคราะห์และการจัดทำ Data driven Marketing ดังนี้ค่ะ (^∀^●)ノシ
- การเปลี่ยนแปลงคุณสมบัติ (Feature Transformation) – เช่น การใช้รากที่สองหรือ Logarithm ของยอดขายเพื่อทำให้ข้อมูลกระจายตัวในรูปแบบ Normal Distribution ซึ่งสามารถช่วยเพิ่มประสิทธิภาพในการทำ Prediction ของ ML โมเดลได้
- การทำ Feature Cross-Products – เช่น สร้างคุณสมบัติใหม่โดยการคูณข้อมูลยอดขายกับจำนวนสินค้าที่ซื้อเข้ามา ซึ่งวิธีนี้ช่วยในการเน้นความสัมพันธ์ระหว่างข้อมูลให้สามารถนำไปสร้างแบบจำลองต่อได้ง่ายขึ้น
- การทำ Feature Selection – เช่น การเลือกเฉพาะคุณสมบัติที่มีผลต่อการทำนายของแบบจำลองมากที่สุด เพื่อทำให้แบบจำลองมีประสิทธิภาพมากขึ้น
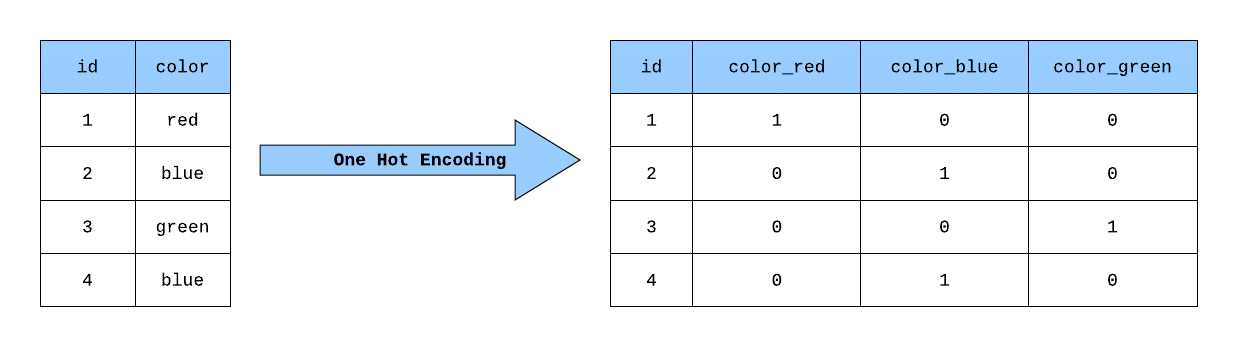
- การเข้ารหัสตัวแปร (Encoding Categorical Variables) – เช่น การแปลงประเภทของสินค้าแต่ละประเภท (เสื้อผ้า, เครื่องใช้ไฟฟ้า) เป็น binary vectors ด้วยวิธี one-hot encoding เพื่อที่ ML Model จะสามารถทำนายได้อย่างถูกต้องแม่นยำมากยิ่งขึ้น
Linear Algebra ในการจัดการข้อมูลด้วย Machine Learning
เข้าสู่ด้านเทคนิคกันมากขึ้นที่ขั้นตอนนี้ค่ะ เพราะพีชคณิตเชิงเส้น เป็นฐานความรู้ทางคณิตศาสตร์ที่สำคัญสำหรับหลายๆ อัลกอริทึมของ Machine Learning โดยนิกขอยกตัวอย่างที่ให้เห็นภาพการใช้งานร่วมกับข้อมูลด้านการตลาด ในการคำนวณที่เป็นส่วนประกอบของ ML Model ดังนี้ค่ะ
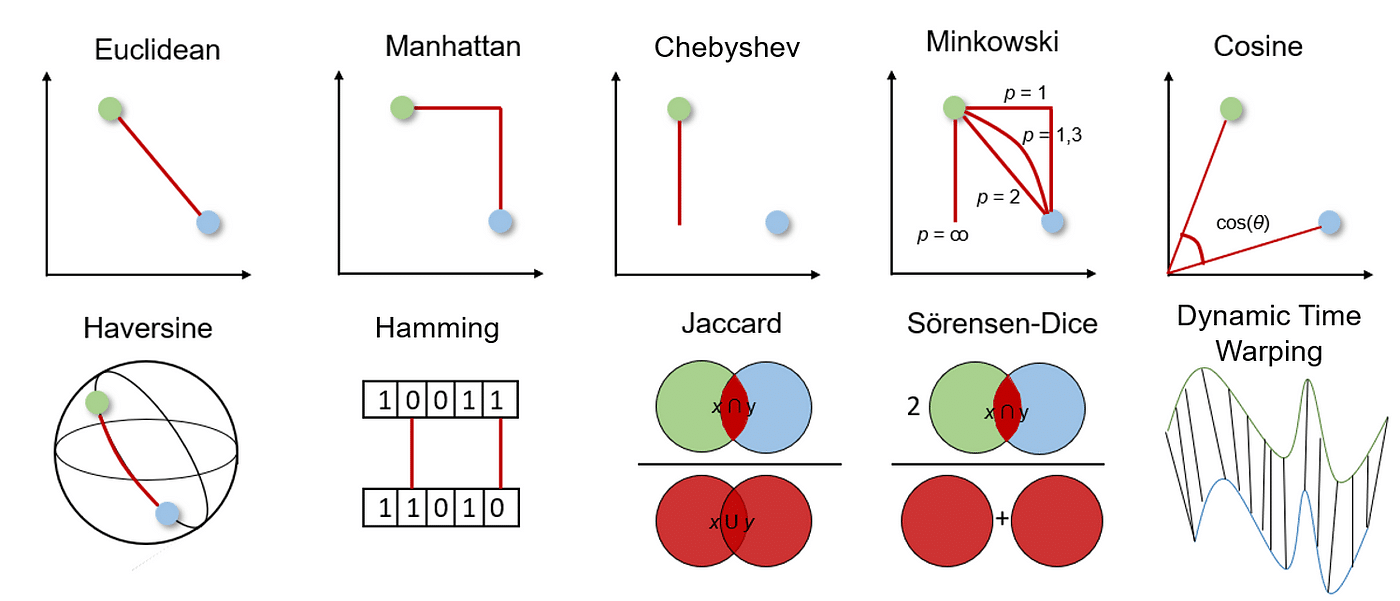
- Euclidean Distance: คือวัดระยะทางระหว่างสองจุด เช่น ในการค้นหาลูกค้าที่มีพฤติกรรมคล้ายกันในระบบ K-NN (K-Nearest Neighbors) เพื่อแนะนำสินค้าหรือโปรโมชั่นที่เหมาะสม
- Manhattan Distance: ช่วยเราวัดระยะทางในระบบที่มีเส้นทางแบบกริด เช่น วิเคราะห์การเดินทางของลูกค้าในห้างสรรพสินค้า
- Unit Vector: ใน Support Vector Machine (SVM) ซึ่งเป็นวิธีการแบ่งกลุ่มข้อมูล การมี vector ที่มี magnitude เป็น 1 ช่วยให้การคำนวณง่ายและมีประสิทธิภาพขึ้น
- Distance From point to plane: ในการวิเคราะห์ Logistic Regression หรือ SVM เราต้องการรู้ว่าข้อมูล (หรือลูกค้า) อยู่ฝั่งใดของ decision boundary หรือเส้นแบ่ง
- Kernel function: ช่วยในการแปลงข้อมูลให้อยู่ในรูปแบบที่แบบจำลองสามารถทำงานได้ดีขึ้น เช่น การแปลงข้อมูลที่ไม่เป็นเส้นตรงให้สามารถจำแนกได้ด้วย SVM
พีชคณิตเชิงเส้นสำหรับการทำ Recommendation System
และก็มาถึงในส่วนที่(น่าจะ)เป็นประโยชน์ และเป็นบทสรุปของการนำความเข้าในด้าน Linear Algebra ไปใช้ในงานด้านการตลาด หรือการทำ Data driven marketing นั่นคือการทำระบบ Recommendation System ที่ถูกออกแบบมาเพื่อแนะนำสินค้าต่างๆ ให้กับกลุ่มลูกค้าของเราได้ตามความเหมาะสม เพื่อผลลัพธ์ทางการตลาดที่ดี ซึ่งมีรายละเอียดการคำนวณด้วยกระบวนการดังต่อไปนี้ค่ะ
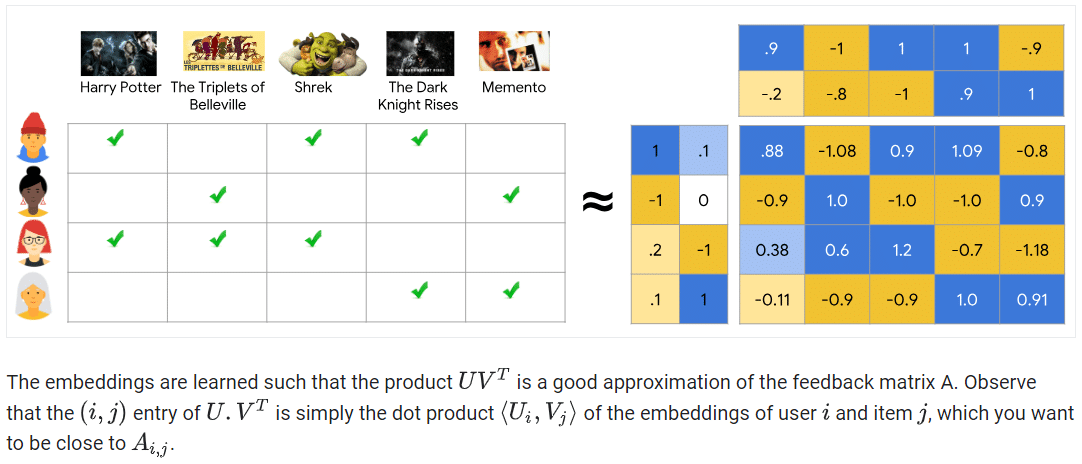
- Matrix Factorization: กล่าวคือถ้าเรามีเมทริกซ์ที่บ่งบอกถึงความสัมพันธ์ระหว่างผู้บริโภคกับสินค้าที่ซื้อ ตัว Matrix Factorization จะมาช่วยแยกหรือจำแนกสิ่งที่เป็น “ปัจจัยซ่อนเร้น” ที่เชื่อมโยงหรือมีความสัมพันธ์ ระหว่างผู้บริโภคของเราและตัวสินค้า หรืออีกตัวอย่างหนึ่ง คือ การให้คะแนนของผู้ใช้ต่อภาพยนตร์ โดยวิธีต่างๆ เช่น SVD, NMF ช่วยในการหา “ปัจจัยซ่อนเร้น” ของผู้ใช้และรายการหรือวิดีโอที่รับชมได้
- User-Item Interaction Matrix: ช่วยเราเก็บข้อมูลเกี่ยวกับสิ่งที่ผู้ใช้ชอบหรือไม่ชอบ หรือผลตอบรับของผู้ใช้ต่อสินค้าต่างๆ
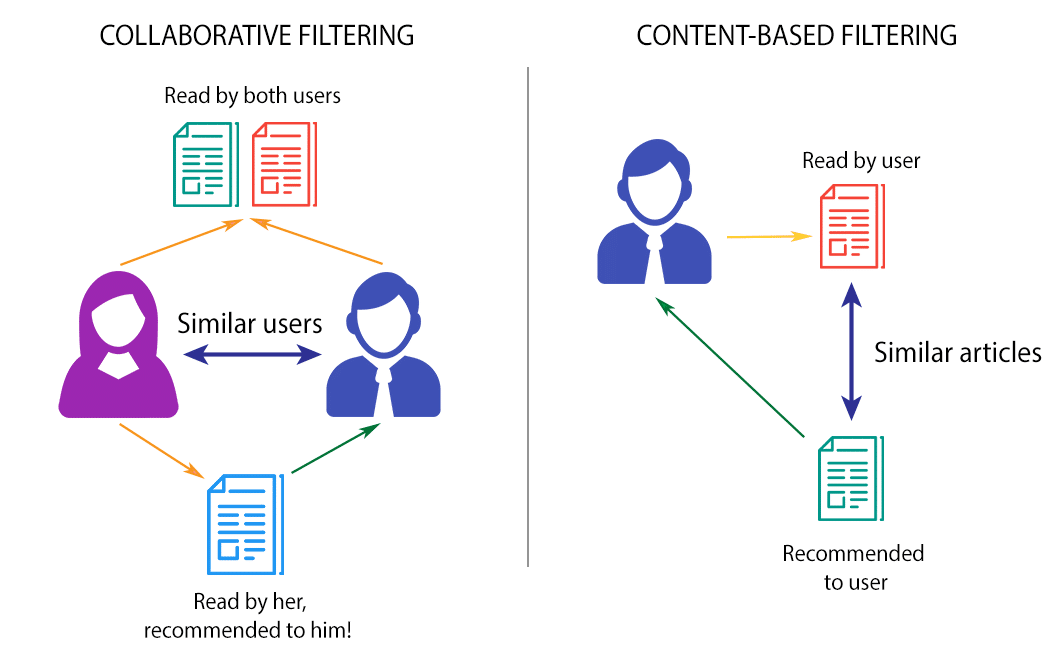
- Content-Based Filtering: ถ้าลูกค้า A ชอบสินค้าหรือ Content ที่มีลักษณะเฉพาะอย่าง ระบบจะแนะนำสินค้าที่มีลักษณะคล้ายคลึงกับสิ่งที่ A ชอบ ซึ่งเป็นพื้นฐานของการทำ Personalization ต่างๆ ค่ะ
- Collaborative Filtering: ถ้าลูกค้า A และ B มีความสนใจ และพฤติกรรมการซื้อสินค้า/ความสนใจ Content ที่คล้ายคลึงกัน สิ่งที่ B ชอบอาจถูกแนะนำให้กับ A ด้วยเป็นต้น
- Cosine Similarity: เป็นวิธีวัดความคล้ายคลึงระหว่างเวกเตอร์ 2 Vectors ซึ่งสามารถช่วยตรวจสอบว่าสินค้า/Contents มีความคล้ายคลึงกันยังไง หรือ User ทั้ง 2 คนมีความสนใจที่คล้ายคลึงกันอย่างไร (โดยในส่วนนี้จะเป็นการพิจารณาที่ไม่สนใจขนาด หรือ Magnitude ค่ะ)

สรุปแล้ว Linear Algebra หรือพีชคณิตเชิงเส้น เป็นพื้นฐานทางคณิตศาสตร์ที่เป็นหลักสำคัญของการวิเคราะห์ข้อมูล ทั้งในการจัดการ/แปลงข้อมูล จนถึงการตีความหมายของรูปแบบต่างๆ ของ ML Model ด้วยความเข้าใจในหลักการของเมทริกซ์, เวกเตอร์, ค่าลักษณะเฉพาะ ที่จะช่วยให้เราสามารถประมวลผล วิเคราะห์ และสกัดสาระจากชุดข้อมูลที่ซับซ้อนได้อย่างมีประสิทธิภาพนั่นเองค่ะ
ป.ล. สำหรับเพื่อนๆ ที่ต้องการไปศึกษา In deep details ต่อ นิกขออนุญาตให้ Keywords ดังนี้ค่ะ matrices, vectors, eigenvalues และ eigenvectors ヾ(^▽^*)))
หวังเป็นอย่างยิ่งว่าทุกท่านจะ Enjoy กับคณิตศาสตร์ฉบับนักการตลาดในบทความนี้นะคะ,,,, แล้วพบกันในบทความต่อไปค่ะ (^U^)ノ~YO



{kind=link}