Google’s Gemini คืออะไร และต่างจาก LLMs อื่นเช่น GPT-4 อย่างไรบ้าง

เมื่อต้นเดือนธันวาคม 2023 ที่ผ่านมา Google ได้เปิดตัว LLMs ตัวใหม่ที่ชื่อ Gemini ให้พวกเราได้ตื่นเต้น และติดตามทดลองใช้กันอีกแล้วค่ะ,,,, ซึ่งถึงแม้ว่านิกอยากจะบอกนักพัฒนาว่า พักบ้างอะไรบ้าง User ตามไม่ทันแล้ว,, แต่ก็นั่นแหละค่ะ หยุดไม่ได้หรอก 55+ ก็ต้องตามอยู่ดีว่าเจ้า Gemini นี่คืออะไร มีความพิเศษอย่างไร ทั้งในด้านของ LLM และด้านอื่นๆ เลยเป็นที่มาของบทความนี้ ที่จะมาชวนทุกท่านมาแชร์ และติดตามกันค่ะว่าของเล่นใหม่แห่งวงการ Generative AI ตัวนี้แตกต่าง หรือล้ำขึ้นอย่างไรบ้าง => ว่าแล้วก็,, Let’s go (☞゚ヮ゚)☞
ซึ่งอย่างที่เราทราบกันดีค่ะว่าโลก LLMs มีการแข่งขันที่ดุเดือด โดยเฉพราะในผู้เล่นสำคัญอย่าง Google, OpenAI และ Meta Llama (หรือ Facebook) พี่ใหญ่ด้านเทคโนโลยีเหล่านี้ ที่กำลังพัฒนาเพื่อสร้าง LLMs ที่มีความเหมือนมนุษย์ หรือ “เนียน” ออกมาให้ได้มากที่สุด
โดย Google ที่พวกเราคงคุ้นเคยกันในมุมมองที่เป็น Search engine ได้ก้าวเข้าสู่โดเมนอย่างจริงจังด้วยการพัฒนาและปล่อย Gemini โดยส่วนตัวนิกคิดว่า Google ต้องการพัฒนาให้เป็น LLM ที่มีความหลากหลายและทรงพลัง รองรับงานซับซ้อนต่างๆ เพื่อแข่งขันกับโมเดลกลุ่ม GPT ซีรีส์ต่างๆ ของค่าย OpenAI ซึ่งต้องยอมรับค่ะว่า Chatbot ที่ขับเคลื่อนด้วยโมเดลนั้นอย่าง ChatGPT นับเป็นตัวแปรที่ปฏิวัติวงการ Generative AI ในแง่ของการสนทนาด้วยความซับซ้อน และค่อนข้างเนียนได้
ถ้าอย่างนั้น Gemini ที่ Google พัฒนาขึ้นมามีความต่างอย่างไรบ้าง เรามาดูไปพร้อมๆ กันเลยค่ะ^^
Google Gemini คืออะไร?
โมเดล LLM Gemini ถูกสร้างขึ้นมาบนพื้นฐานของ Transformer decoders ที่ได้รับการปรับปรุงโครงสร้าง และการปรับแต่งโมเดลให้ดียิ่งขึ้น เพื่อให้รองรับการ Train ข้อมูลขนาดใหญ่ได้อย่างเสถียรและปรับ Inference ให้เหมาะสมบนหน่วยประมวลผล Tensor Processing Units ของ Google
โดยโมเดลเหล่านี้ได้รับการ Train เพื่อรองรับความข้อความที่มีความยาวบริบท 32,000 ตัวอักษร โดยใช้กลไกการจับสัญญาณที่มีประสิทธิภาพ เช่น multi-query attention โดยรุ่นแรกที่ถูกพัฒนาขึ้นมาคือ Gemini 1.0 ที่มีการแบ่งเป็น 3 ประเภท เพื่อรองรับการใช้งานที่หลากหลาย ซึ่งแต่ละประเภทมีรายละเอียดดังนี้ค่ะ
- Ultra เป็น โมเดลที่มีประสิทธิภาพสูงสุด ที่มี state-of-the-art ที่ซับซ้อนหลากหลาย รวมถึงการใช้เหตุผลและการทำงานแบบหลายมิติ แต่เหมาะสำหรับการใช้งานบนระบบที่ Based-on TPU เนื่องจากเป็นโครงสร้างของ Gemini ที่มีความซับซ้อนมาก
- Pro เป็น รุ่นที่ถูกปรับให้มีความสมดุลระหว่างประสิทธิภาพ ค่าใช้จ่าย และความล่าช้า (คือพูดง่ายๆ ค่ะว่าไม่อืด) ซึ่งก็มีประสิทธิภาพที่ค่อนข้างดีในงานที่หลากหลาย สามารถรองรับการใช้งานกว้างๆ หลายประเภท
- Nano เป็น โมเดลรุ่นที่รองรับการทำงานบนอุปกรณ์ต่างๆ เช่น Smartphone ซึ่งตัว Nano จะมี 2 รุ่น ตามจำนวนของพารามิเตอร์ได้แก่รุ่น 1.8B (Nano-1) และ 3.25B (Nano-2) เพื่อรองรับอุปกรณ์ที่มีหน่วยความจำต่ำ และสูงตามลำดับ โดยมีการปรับให้เป็น 4 บิตสำหรับการใช้งานจริง

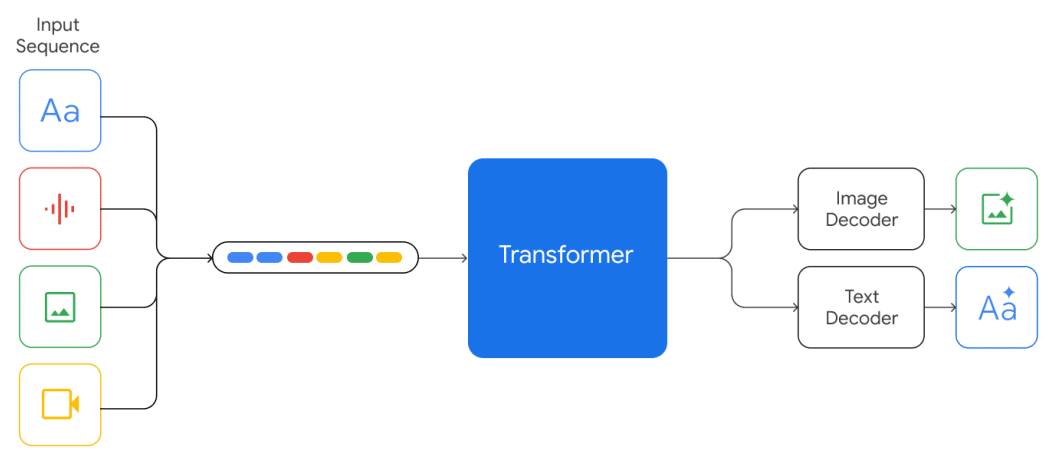
โดยโมเดลนี้มีความพิเศษตรงที่ ตัวโมเดลถูกออกแบบมาให้มีความสามารถในการย่อยข้อมูลหลากมิติ ทั้งข้อความ ภาพ เสียง และวิดีโอ ผสานเข้ากันอย่างราบรื่น ซึ่งหมายความว่า Input สามารถเป็นได้ทั้งภาพธรรมชาติ แผนภูมิ ภาพหน้าจอ PDF หรือแม้กระทั่งวิดีโอ o(^▽^)o และโมเดลก็ตอบกลับได้ทั้งเป็นข้อความและภาพ คือพูดง่ายๆ ค่ะว่ารับได้ทุกสิ่ง และเป็นให้เธอทุกอย่าง 55+
ซึ่งเจ้าเทคนิคการเข้ารหัสภาพของนี้ได้รับแรงบันดาลใจจากงานวิจัยของ Flamingo, CoCa, และ PaLI ของ Google เอง โดยสิ่งที่พิเศษคือโมเดล Gemini นี้ถูกออกแบบมาเพื่อทำงานแบบหลายมิติโดยแท้ตั้งแต่แรกเริ่ม ซึ่งต่างจาก GPT ที่ค่อยๆ พัฒนาและเพิ่ม Features และความสามารถต่างๆ เข้ามาทีหลัง โดยสามารถสร้างภาพได้โดยตรงเลย ผ่านการใช้โทเค็นภาพแยกต่างหาก
นอกจากนี้ยังมีความเข้าใจวิดีโอ โดยหลักการที่ Gemini จะจับภาพวิดีโอเป็นลำดับเฟรม แล้วส่งเข้าไปยัง Large context window ซึ่งเฟรมวิดีโอ หรือภาพสามารถแทรกอยู่ระหว่างข้อความหรือเสียงตามธรรมชาติใน Input เท่านั้นยังไม่พอค่ะ โมเดลนี้ยังสามารถรองรับความละเอียดของอินพุตแบบปรับเปลี่ยนได้ และรองรับลำดับสลับกันของข้อความ ภาพ เสียง และวิดีโอเป็นอินพุต (แสดงด้วยโทเค็นสีต่างกันในลำดับอินพุต) แล้วสร้าง Output เป็นทั้งข้อความ และภาพสลับกันได้ตามใจผู้ใช้งาน
นอกจากนี้ยังสามารถป้อนสัญญาณเสียงโดยตรงที่ความถี่ 16kHz จากฟีเจอร์ Universal Speech Model (USM) ทำให้โมเดลจับเอา Nuances ของเสียงได้ดีกว่าการแปลงเสียงเป็นข้อความแบบเดิมๆ
การกำหนดราคาค่าใช้บริการ
มาสู่เรื่องสำคัญมากๆ เรื่องต่อไปนั่นคือเรื่องของการกำหนดราคาค่ะ เพราะการแข่งขันของ LLM AI ไม่เพียงร้อนแรงที่ตัวโมเดลเท่านนั้น แต่ยังลุกลามไปถึงกลยุทธ์การกำหนดราคาด้วย โดยที่ Google เลือกคิดค่าบริการตามจำนวนตัวอักษร ซึ่งถูกใจผู้ใช้งานในบางภาษา เช่น ไทย (คหสต. นะคะ) ในขณะที่ OpenAI ใช้ระบบ Token ที่จะมีความเหมาะสมกับภาษาอังกฤษมากกว่า ซึ่งภาคธุรกิจหรือผู้ใช้งานทั่วไป จะต้องพิจารณาความต้องการเฉพาะตัวค่ะว่า ลักษณะการใช้งานของเราอยู่ในรูปแบบไหน ร่วมกับคุณลักษณะเฉพาะตัวของบริการจาก AI ของทุกค่าย ตัวอย่างเช่น ความสามารถของโมเดล การผสานเข้ากับระบบเดิมที่มีอยู่แล้วของเรา (โดยเฉพาะอย่างยิ่งกรณีที่เราใช้งานในรูปแบบของ API) และเป้าหมายระยะยาว ไม่ใช่พิจารณาแค่ในส่วนของราคาอย่างเดียว
สรุปแล้ว ทั้ง Google Gemini และ OpenAI ChatGPT-4 ล้วนเป็นก้าวกระโดดที่สำคัญในวงการ AI สร้างสรรค์ การตัดสินใจเลือกขึ้นอยู่กับความต้องการเฉพาะของงาน ปริมาณข้อมูลหรือภาษาที่ใช้ และแผนการใช้ทรัพยากรค่ะ
ประสิทธิภาพของโมเดล Gemini
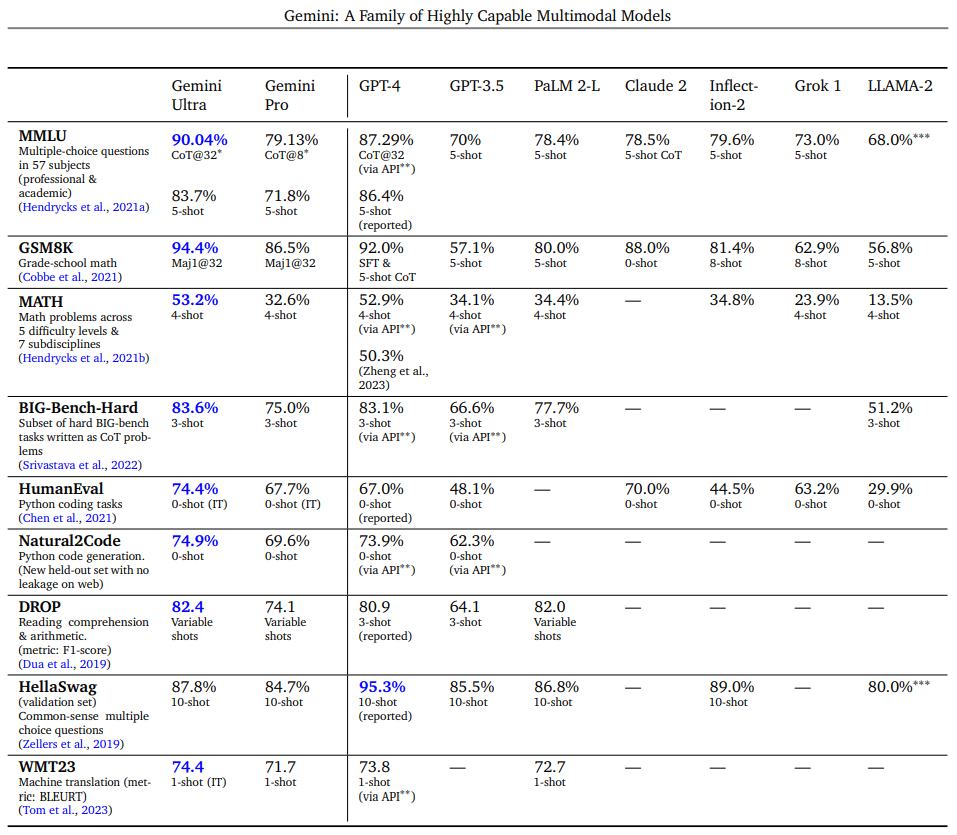
จากการที่ Generative AI ตัวนี้เป็นโมเดลแบบหลายมิติอย่างแท้จริง ที่ได้รับการ Train จากข้อมูลหลายหลายรูปแบบรวมๆ กันทั้งรูปแบบข้อความ ภาพ เสียง และวิดีโอ แต่ก็มีคำถามที่ยังคงเป็นที่ถกเถียงกันอยู่คือการ Train โมเดลจากข้อมูลหลายแบบร่วมกันนี้จะส่งผลให้โมเดลมีความสามารถที่ดีขึ้นในแต่ละโดเมนหรือไม่ แม้แต่เมื่อเปรียบเทียบกับโมเดล และแนวทางที่ออกแบบมาอย่างเฉพาะอย่างสำหรับโดเมนเดียวอย่าง GPT the series แล้วประสิทธิภาพของโมเดลจาก Google ตัวนี้เป็นอย่างไร เพื่อตอบคำถามนั้นนิกจึงของเอาผลงานวิจัยมาเล่าให้ฟังคร่าวๆ ดังนี้ค่ะ
จากผลการวิจัยชี้ให้เห็นว่าโมเดลจากค่าย Google ตัวนี้สามารถทำงานได้อย่างยอดเยี่ยมในทุกโดเมน ซึ่งถือเป็นการสร้างมาตรฐานใหม่ให้กับวงการ Generative AI ที่เกี่ยวข้องกับข้อความ ภาพ เสียง และวิดีโอ เลยก็ว่าได้ โดยรายละเอียดของความสามารถของตัวโมเดลในแต่ละโดเมนสรุปได้ดังนี้
- ข้อความ: สามารถเข้าใจและสร้างข้อความได้อย่างแม่นยำ สามารถตอบคำถามที่ซับซ้อนได้ และสามารถสร้างรูปแบบข้อความสร้างสรรค์ต่างๆ เช่น บทกวี โค้ด สคริปต์ ชิ้นดนตรี อีเมล จดหมาย ฯลฯ ยกตัวอย่างได้จากภาพด้านล่างนี้ ที่มีการใช้งานในด้านการปรึกษาเพื่อทำการบ้านส่งอาจารย์ โดยโจทย์เป็นคำถามด้านฟิสิกส์เลยค่ะ

- ภาพ: ตัวโมเดลนี้สามารถเข้าใจและสร้างภาพได้อย่างแม่นยำ สามารถระบุวัตถุ เหตุการณ์ และอารมณ์ในภาพ และสามารถสร้างภาพใหม่ๆ ได้ ซึ่งถ้าทำได้ตามผลที่ Evaluate ไว้ต้องยอมรับว่า ว้าวมากๆ เลยค่ะ

Multimodal Models, Google DeepMind]
- เสียง: สามารถเข้าใจและสร้างเสียงได้อย่างแม่นยำ สามารถถอดเสียงเสียง และสามารถสร้างเสียงใหม่ๆ ได้ด้วย
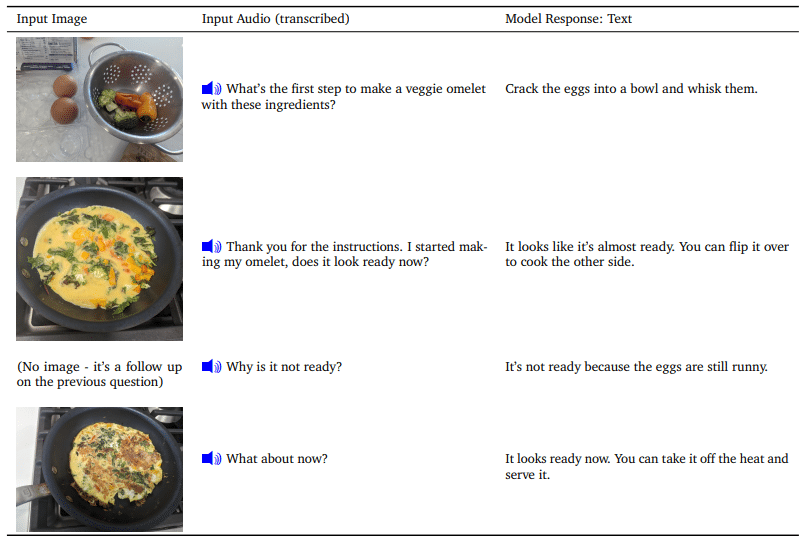
- วิดีโอ: สามารถเข้าใจและสร้างวิดีโอได้อย่างแม่นยำ สามารถระบุวัตถุ เหตุการณ์ และอารมณ์ในวิดีโอ และสามารถสร้างวิดีโอใหม่ๆ ได้
แล้วเราจะทดลองให้งาน Google’s Gemini ได้อย่างไร?
ในปัจจุบันนี้โมเดลนี้พร้อมใช้งานแล้วบ้าง บนผลิตภัณฑ์บางตัวของ Google ในขนาด Nano และ Pro เช่น โทรศัพท์ Pixel 8 และ Google Bard โดย Google มีแผนที่จะผสานรวมโมเดลนี้ เข้ากับผลิตภัณฑ์อื่นๆ ด้วยค่ะ เช่น การค้นหา โฆษณา Chrome, etc. ในอนาคต
สรุปแล้ว,,,,
ถึงแม้ว่า Gemini มีความสามารถน่าประทับใจแค่ไหนก็ตาม แต่ LLM ก็ยังมีข้อจำกัดที่ยังต้องพัฒนาเพิ่มเติม โดยเฉพาะอย่างยิ่งในเทอม AI hallucination และมุ่งเน้นการสร้าง Output ที่เชื่อถือและตรวจสอบได้ แม้จะทำผลงานได้ดีในเกณฑ์มาตรฐานการสอบ LLM ยังคงมีข้อจำกัดในงานที่ต้องการความสามารถในการใช้เหตุผลระดับสูง จึงต้องมีการประเมินที่ท้าทายและสมจริงยิ่งขึ้นเพื่อวัดความเข้าใจที่สามารถที่แท้จริงของโมเดล

Last but not Least
ท้ายที่สุดแล้วโมเดล LLM รุ่นใหม่จาก Google ที่โดดเด่นด้วยความสามารถในการทำงานแบบหลายมิติ ทั้งข้อความ ภาพ เสียง และวิดีโอ อย่าง Gemini ที่นำเสนอในบทความนี้ จะสามารถเปิดโอกาสใหม่มากมายสำหรับงานด้านการตลาด (ในมุมมองของนิกนะคะ) โดยเราสามารถใชง้าน ในด้านการสร้างเนื้อหา เช่น เนื้อหาการเกี่ยวกับตลาดที่หลากหลายและสร้างสรรค์ยิ่งขึ้น ไม่ว่าจะเป็น บทความ วิดีโอ โฆษณา อีเมล ฯลฯ เพราะจากฐานข้อมูลจำนวนมหาศาลที่ Google มีอยู่ทำให้เราสามารถเข้าใจและตอบสนองต่อความต้องการของลูกค้าได้อย่างมีประสิทธิภาพ ทำให้ช่วยสร้างเนื้อหาที่ตรงใจและดึงดูดความสนใจได้มากยิ่งขึ้น o(* ̄▽ ̄*)ブ
หรือจะใช้ในด้านการวิเคราะห์ข้อมูล นิกเชื่อว่าโมเดลตัวนี้ก็สามารถช่วยวิเคราะห์ข้อมูลสำคัญทางการตลาดได้อย่างละเอียดและครอบคลุมยิ่งขึ้น เพราะความสามารถในการเข้าใจข้อมูลเชิงลึกที่ซับซ้อน และยังสร้างโมเดลเชิงปริมาณเพื่ออธิบายความสัมพันธ์ต่างๆ ที่เกิดขึ้น ซึ่งสิ่งนี้เองค่ะที่จะช่วยให้นักการตลาดเข้าใจพฤติกรรมของลูกค้าและตลาดได้อย่างลึกถึง Deep details มากยิ่งกว่าเดิม
และขั้นกว่าคือช่วยในด้านการตัดสินใจ ที่อาจทำให้นักการตลาดตัดสินใจได้อย่างแม่นยำยิ่งขึ้น จากความสามารถในการคาดการณ์แนวโน้มต่างๆ ในตลาด และพฤติกรรมของลูกค้าในอนาคต ซึ่งช่วยให้นักการตลาดสามารถวางแผน และรับมือกับการเปลี่ยนแปลงได้อย่างมีประสิทธิภาพนั่นเองค่ะ 📈🚀
ทั้งนี้เพื่อนๆ สามารถอ่านบทความก่อนหน้าที่เปรียบเทียบความต่างระหว่าง Google Bard และ ChatGPT ได้ตาม Link:



{kind=link}