ทำความรู้จัก ตัวแปร ใน SEM เครื่องมือการวิจัยสุดฮิตในสาย Marketing

สวัสดีครับบทความนี้จะมาพูดถึง Structural Equation Modeling หรือ โมเดลสมการโครงสร้าง ต่อไปนี้ผมจะเรียกชื่อย่อว่า SEM แล้วกันนะครับ ในบทความที่แล้ว เราได้ทำการรู้จัก SEM แบบคร่าว ๆ ไปแล้ว (ถ้าใครยังไม่อ่านอยากให้ลองอ่านก่อนนะครับ จะได้เข้าใจบทความนี้มากยิ่งขึ้น คลิ๊ก เพื่ออ่านได้เลยครับ) มาในบทความนี้เหมือนเป็น Ep.2 ผมอยากจะพาทุกคนมาทำความรู้จักกับ SEM ในแบบที่ละเอียดขึ้นในเรื่องของ ตัวแปร SEM กันครับ
Example Structural Equation Modeling
ก่อนอื่นผมจะพามาทบทวนเล็ก ๆ น้อย ๆ กันก่อนดีกว่าครับว่าวิธีการอ่านโมเดล SEM เค้าอ่านกันยังไง
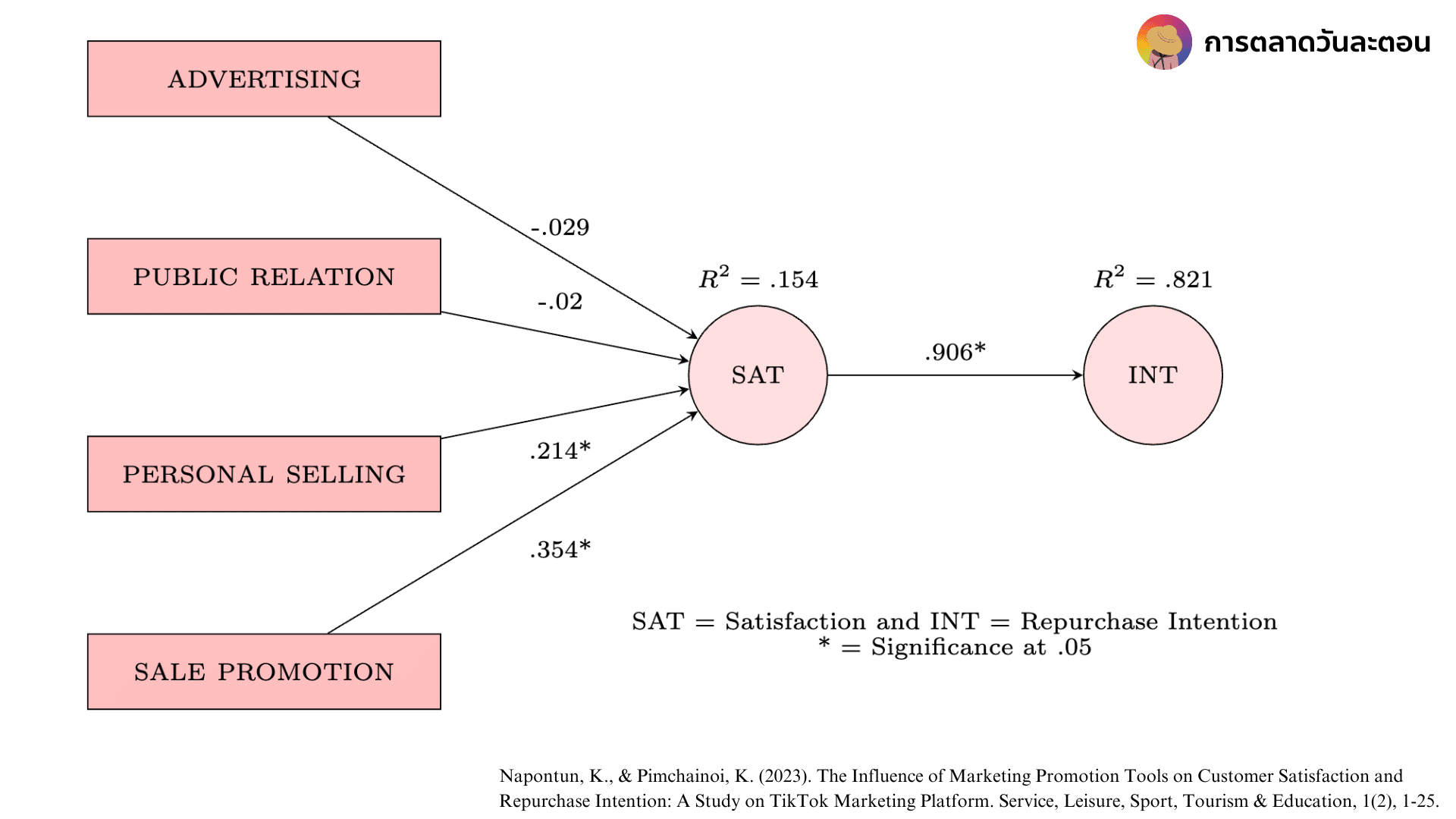
ก้อนวงกลม และก้อนสี่เหลี่ยมจะแทนตัวแปรต่าง ๆ ครับ เช่น พวกก้อนสี่เหลี่ยม Advertising แทนเครื่องมือการโฆษณา, Public Relation แทนเครื่องมือการประชาสัมพันธ์, Personal Selling แทนการใช้พนักงานขาย, Sales Promotion แทนโปรโมชั่นส่งเสริมการขาย
ส่วนวงกลมแทน SAT = Satisfation แทนความพึงพอใจของลูกค้า, และ INT = Repurchase Intention แทนความตั้งใจซื้อซ้ำ การโยงลูกศรระหว่างตัวแปรหมายความว่า ตัวแปรที่ลูกศรวิ่งออกมาจะส่งผลกระทบต่อตัวแปรที่ลูกศรวิ่งเข้าหา เช่นจาก Personal Selling —-> Satisfation หมายความว่า การใช้พนักงานขายมีผลกระทบต่อความพึงพอใจของลูกค้าโดยมีค่าอิทธิพล 0.214 หน่วย (ตัวเลขกำกับเส้น)
ในโมเดลนี้ผลกระทบที่เกิดขึ้นเราจะสังเกตเห็นสัญลักษณ์ “*” และ มีค่าที่ติดลบด้วย อธิบายสั้น ๆ ได้แบบนี้ครับ
สัญลักษณ์ * แทนความสัมพันธ์ที่ Significant หรือเป็นความสัมพันธ์ที่ที่มีนัยยะสำคัญทางสถิติ แต่บางวิจัยอาจจะไม่ใส่ สัญลักษณ์ * แต่มีการเขียนไว้ว่าทุกตัวมีความสัมพันธ์กันอย่างมีนัยยะสำคัญทางสถิติแทนครับ ในโมเดลนี้มีความสัมพันธ์ที่ Significant กันทั้งหมด 3 คู่ครับ Personal Selling —-> Satisfation, Sales Promotion —-> Satisfation และ Satisfation —-> Repurchase Intention ครับ
ต่อไปอธิบายถึงค่าที่ติดลบกันครับ ยกตัวอย่างในโมเดลก็คือ Advertising และ Public Relation ที่ส่งผลไป Satisfation ครับ เครื่องหมายติดลบก็เหมือนกับการแปรผกผันครับ หากเราไปดูแบบความสัมพันธ์ที่เป็นบวกอย่าง Sales Promotion —-> Satisfation สามารถอ่านได้ว่าถ้ามีโปรโมชั่นเกิดขึ้นความพึงพอใจของลูกค้าก็จะเกิดขึ้น
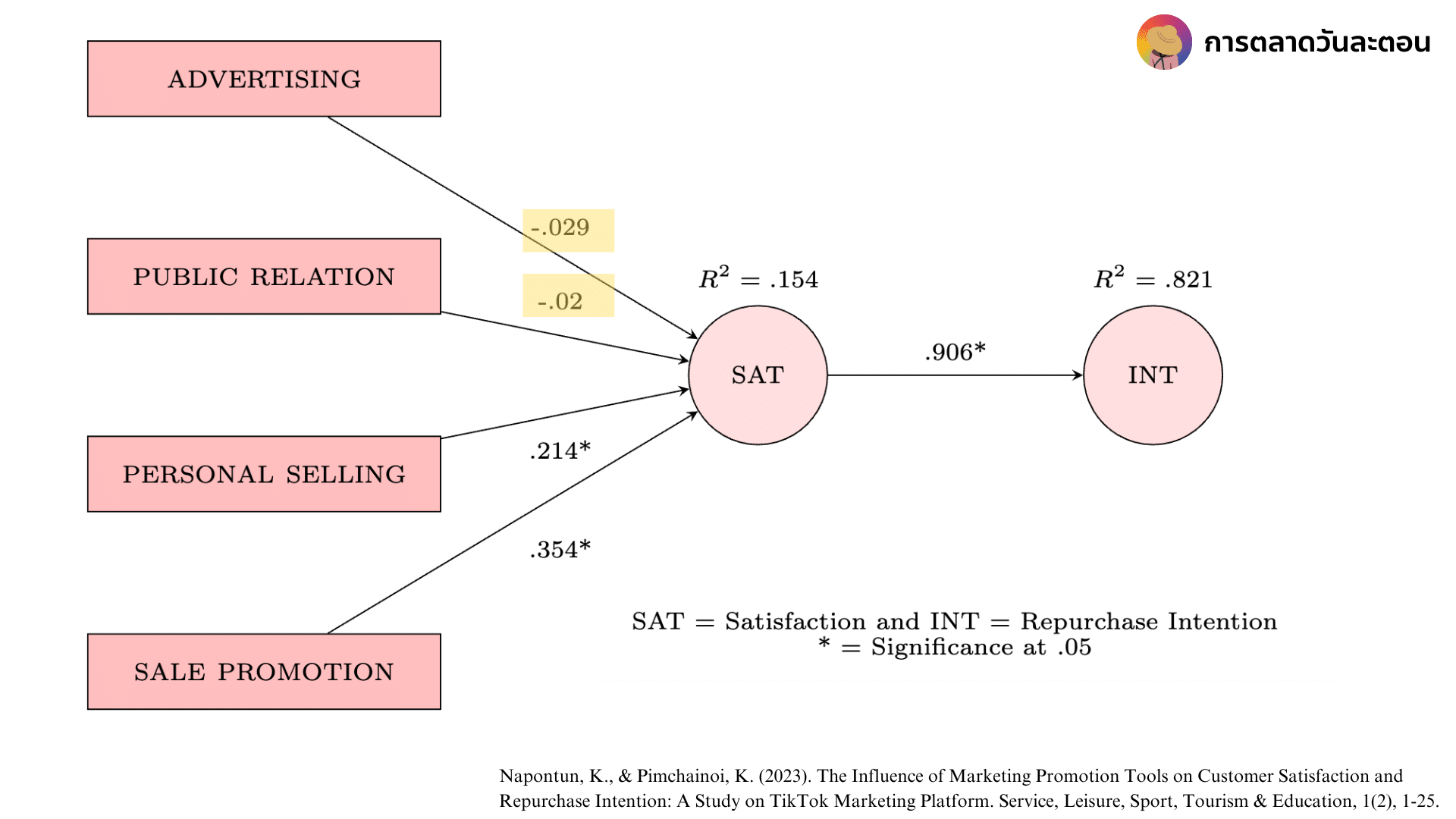
ในทางกลับกัน จากโมเดลที่มีความสัมพันธ์ติดลบอย่าง Advertising —-> Satisfation สามารถอ่านได้ว่าถ้ามีโฆษณาเกิดขึ้นลูกค้าจะไม่เกิดความพึงพอใจ เหตุผลเป็นเพราะลูกค้าอาจจะรำคาญโฆษณาก็ได้ แต่อย่างไรก็ตามในโมเดลนี้ความสัมพันธ์ที่ติดลบไม่มีสัญลักษณ์ * แสดงว่าความสัมพันธ์ดังกล่าวไม่ Significant เพราะฉะนั้นเราจคงสามารถตีความได้ว่าการโฆษณาไม่ได้ทำให้ความพึงพอใจลูกค้าลดลง ในขณะเดียวกันก็ไม่ได้ทำให้เพิ่มขึ้นด้วยครับ
ประเภทของตัวแปร Structural Equation Modeling
ใน SEM เราสามารถแยกตัวแปรออกเป็นสองประเภท นั่นคือ Endogenous Variables และ Exogenous Variables ครับ ความเข้าใจในความแตกต่างระหว่างตัวแปรทั้งสองมีความสำคัญมาก เนื่องจากจะช่วยกำหนดว่าอะไรเป็นสาเหตุและอะไรเป็นผลลัพธ์ นอกจากนี้ยังช่วยให้เราออกแบบการวิจัยและวิเคราะห์ข้อมูลได้อย่างเหมาะสมมากขึ้นครับ
1. Endogenous Variables
Endogenous Variables: เป็นตัวแปรที่ขึ้นอยู่กับปัจจัยอื่น ๆ และแสดงผลลัพธ์ที่ได้รับอิทธิพลจากตัวแปรอื่น พูดอย่างตรงไปตรงมาคล้าย ๆ กับตัวแปรตามครับ หรือเป็นตัวแปรปลายทางที่เราต้องการจะรู้ครับ
- เป็นตัวแปรที่ค่าอาจเปลี่ยนแปลงหรือได้รับผลกระทบจากตัวแปรอื่น ๆ ในโมเดล
- ตัวแปรเหล่านี้มักเป็นตัวแปรที่ถูกอธิบายหรือพยายามทำนายโดยใช้ตัวแปรอื่น ๆ
2. Exogenous Variables
Exogenous Variables: เป็นตัวแปรที่คล้ายกับตัวแปรอิสระที่ถือเป็นสาเหตุหรือปัจจัยที่มีผลกระทบต่อ Endogenous Variables ครับ พูดง่าย ๆ ก็คล้าย ๆ กับตัวแปรต้นครับ
- เป็นตัวแปรที่ค่าไม่ได้รับผลกระทบจากตัวแปรอื่น ๆ ในโมเดล
- ตัวแปรเหล่านี้มักถูกใช้เพื่ออธิบายหรือเป็นตัวแปรที่กำหนดความเปลี่ยนแปลงของ Endogenous Variables
Example
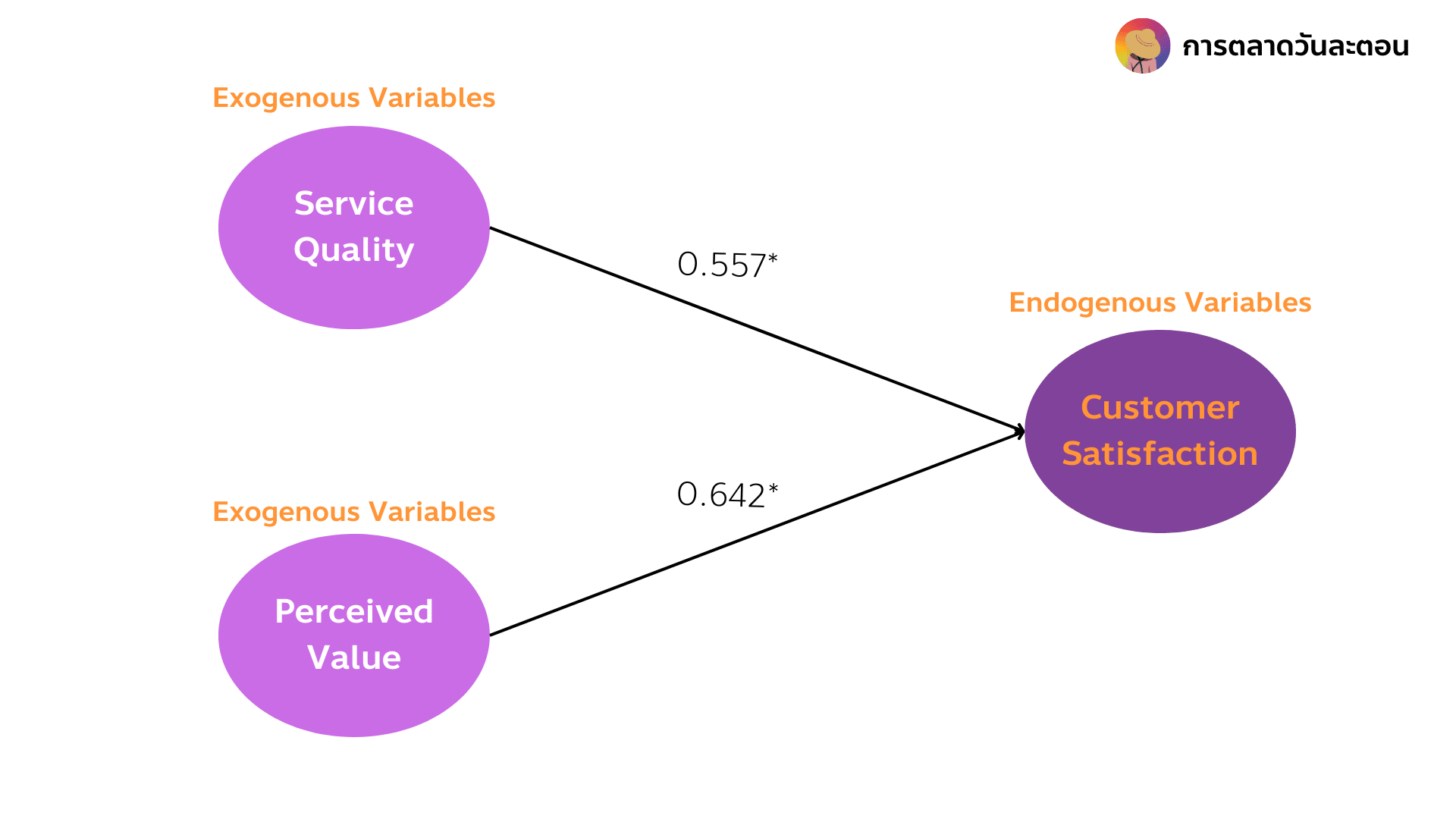
ในภาพนี้สามารถอธิบายได้ว่า Service Quality และ Perceived Value เป็นตัวทำนาย Customer Satisfaction ดังนั้นจึงเรียก Service Quality และ Perceived Value ที่เป็นตัวทำนายว่าเป็น Exogenous Variables และเรียก Customer Satisfaction ที่เป็นตัวถูกทำนายว่าเป็น Endogenous Variables
โครงสร้างของตัวแปร Structural Equation Modeling
ในการแบ่งประเภทโครงสร้างของตัวแปรสามาถแยกออกได้ 2 โครงสร้างใหญ่ ๆ ครับ นั่นคือตัวแปรที่สังเกตได้ และตัวแปรแฝงครับ
ตัวแปรที่สังเกตได้ (Observed Variables):
ตัวแปรที่สังเกตได้คือ ตัวแปรที่สามารถวัดได้โดยตรงและมีข้อมูลที่รวบรวมมาเป็นรูปแบบเชิงตัวเลข โดยทั่วไปแล้วตัวแปรเหล่านี้มาจากการสำรวจแบบสอบถาม การวัดทางกายภาพ หรือการสังเกตโดยตรง ตัวอย่างเช่น
- คะแนนสอบของนักเรียน
- ส่วนสูงและน้ำหนักของบุคคล
- ระยะเวลาในการซื้อสินค้า
ซึ่งตัวแปรที่สังเกตได้เหล่านี้สามารถนำมาใช้ในการวิเคราะห์ข้อมูลโดยตรง ในการทดสอบสมมติฐาน หรือสร้างโมเดลทางสถิติ โดยส่วนใหญ่จะใช้สัญลักษณ์ “สี่เหลี่ยม” แทนตัวแปรที่สังเกตุได้ครับ
ตัวแปรแฝง (Latent Variables):
ตัวแปรแฝง คือ ตัวแปรที่ไม่สามารถวัดได้โดยตรง แต่ถูกสันนิษฐานว่ามีอยู่ครับ ตัวแปรแฝงมักถูกสร้างขึ้นจากตัวแปรที่สังเกตได้หลายตัวที่มีความสัมพันธ์กัน โดยส่วนใหญ่จะใช้สัญลักษณ์ “วงกลม, วงรี” แทนตัวแปรแฝงครับ ยกตัวอย่างเช่น
- ความฉลาด (Intelligence) ปกติความฉลาดเราไม่สามารถวัดได้โดยตรงครับ แตกต่างจากน้ำหนักและส่วนสูง จึงต้องอาศัยตัวแปรที่สังเกตได้หลาย ๆ ตัวร่วมกันวัด เช่น หากเราจะวัดความฉลาดทางภาษา เราอาจจะวัดจากความฉลาดจากภาษาหลักที่นิยมใช้กันครับ เช่น ภาษาอังกฤษ และภาษาจีน ซึ่งความฉลาดจากภาษาอังกฤษและภาษาจีนก็สามารถวัดได้จากคะแนนสอบหลาย ๆ สถาบันซึ่งถือเป็นตัวแปรที่สังเกตได้ครับเพราะสามารถวัดได้ด้วยตัวเลข ซึ่งถ้าหากมีคะแนนสอบที่สูงเราก็สามารถระบุได้ครับว่ามีความฉลาดทางด้านภาษา เพื่อความเข้าใจอยากให้ดูรูปประกอบไปด้วยครับ
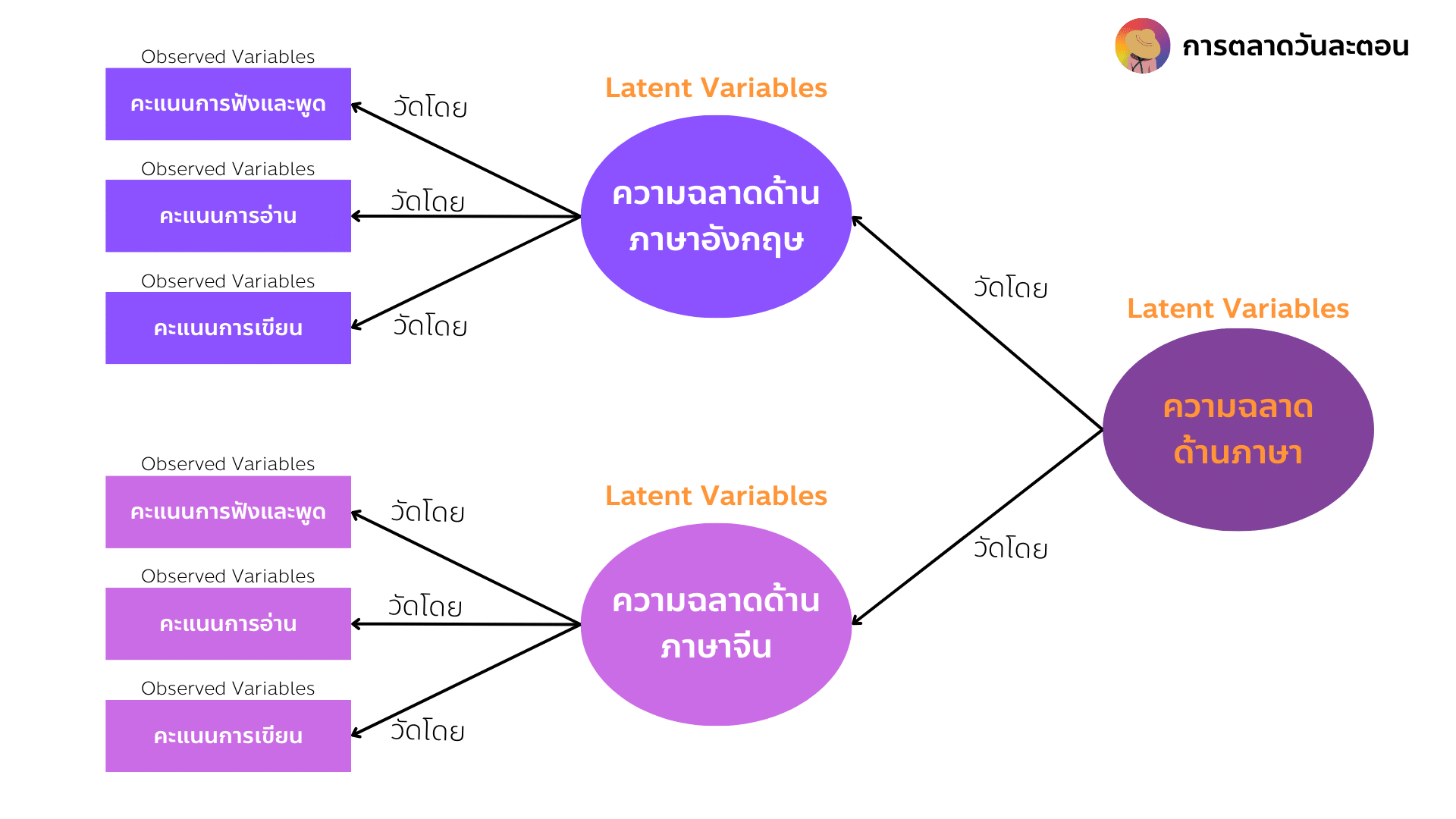
สัญลักษณ์สี่เหลี่ยมแทนตัวแปรที่สังเกตได้ (Observed Variables) ส่วนวงรีใช้เป็นสัญลักษณ์แทนตัวแปรแฝง (Latent Variables) จะเห็นได้ว่าขั้นแรกเราจะวัดความฉลาดทางภาษาอังกฤษ และภาษาจีนซึ่งเป็นตัวแปรแฝง ด้วยตัวแปรที่สังเกตได้ 3 ตัวครับ ได้แก่ คะแนนการฟังและพูด คะแนนการอ่าน และคะแนนการเขียน (ลูกศรในที่นี้คือลูกศรที่ชี้แสดงถึงองค์ประกอบที่เป็นตัวชี้วัด จะแตกต่างจากลูกศรสมมติฐานครับ โดยส่วนใหญ่ลูกศรสมมติฐานหรือลูกศรแสดงความสัมพันธ์ระหว่างตัวแปรจะชี้จากซ้ายไปขวา แต่ลูกศรที่แสดงถึงองค์ประกอบของตัวชี้วัดจะชี้จากขวาไปซ้ายครับ)
เมื่อเราทำการวัดความฉลาดด้านภาษาอังกฤษ และภาษาจีนที่เป็นตัวแปรแฝง โดยใช้ตัวแปรที่สังเกตุได้ 3 ตัวแล้ว ทำให้เราสามารถใช้ตัวแปรความฉลาดด้านภาษาอังกฤษ และภาษาจีน วัดความฉลาดทางภาษาอีกทีหนึ่งได้เป็นอันจบ ใช่ครับเราสามารถใช้ตัวแปรแฝงวัดตัวแปรแฝงได้
SEM มักใช้ตัวแปรแฝงเพื่อสร้างโมเดลที่อธิบายความสัมพันธ์เชิงทฤษฎี และประเมินว่าความสัมพันธ์เหล่านั้นเหมาะสมกับข้อมูลจริงหรือไม่ ยกตัวอย่างตัวแปรแฝงอื่น ๆ เช่น ทัศนคติ ความพึงพอใจ และอื่น ๆ ที่ไม่สามารถสังเกตได้ครับ
เป็นอย่างไรกันบ้างครับสำหรับบทความที่เป็นเหมือน Ep.2 ในเรื่อง ตัวแปร SEM หรือ Structural Equation Modeling เดี๋ยว Ep. ต่อไปผมกะจะเขียนเกี่ยวกับการสร้างโมเดล การอ่านค่าสถิติอย่างละเอียด ถ้าชอบก็อย่าลืมแสดงความคิดเห็นกันเข้ามาเยอะ ๆ นะครับ
Napontun, K., & Pimchainoi, K. (2023). The Influence of Marketing Promotion Tools on Customer Satisfaction and Repurchase Intention: A Study on TikTok Marketing Platform. Service, Leisure, Sport, Tourism & Education, 1(2), 1-25.
บทความที่แนะนำให้อ่านต่อ
อยากแนะนำให้อ่านบทความเริ่มต้นปูพรมพื้นฐานของ Structural Equation Modeling กันครับเพื่อความรู้ที่ครอบคลุมมากยิ่งขึ้น




{kind=link}