สร้างโปรเจค Data Engineer แบบลากวางด้วย Azure Data Factory (พาร์ท1)

จากความเดิมในหลายๆ ตอนที่แล้ว นิกเชื่อว่านักการตลาด และเพื่อนๆ ที่ติดตามการตลาดวันละตอนอย่างต่อเนื่อง น่าจะมีความรู้ความเข้าใจเป็นอย่างยิ่งในการหาประโยชน์จากข้อมูลที่เรามีในมือ ผ่านการทำ Data Analytics และการวิเคราะห์ของมูลหา Insights ของลูกค้าผ่าน Tools ต่างๆ,,,, ในบทความนี้นิกเลยขอแหวกแนวนิดหน่อย ในการมาชวนพวกเราสร้าง Data Engineer Project แบบ Low-code ด้วยการลากวางด้วย Tool เท่ๆ จาก “โรงงานข้อมูล” (อันนี้นิกตั้งชื่อเรียกขำๆ เองนะคะ–เอาไปอ้างอิงทางวิชาการไม่ได้เน้อ~~) Azure Data Factory กันค่ะ
😃📰🚀✨🤗
ซึ่งนิกเชื่อว่าหากทุกท่านมีความเข้าใจเพิ่มเติมในเรื่องของโครงสร้างข้อมูล และการออกแบบโครงสร้างนั้น จะทำให้เราสามารถสร้างโปรเจคการวิเคราะห์ข้อมูล หรือร่วมออกแบบการจัดเก็บข้อมูลที่มีประสิทธิภาพ เหมาะสมกับโจทย์ของเรา และของลูกค้าเราได้อย่างแน่นอน,, โดยในโปรเจคนี้เราจะใช้ส่วนหนึ่งของ Microsoft Fabric ซึ่งเป็น Service ที่มีบริการที่ครอบคลุมจาก Microsoft โดย Ecosystem ของเขาจะประกอบด้วย Data Factory, Synapse Data Engineering, Synapse Data Science, Synapse Data Warehouse และ Synapse Analytics ซึ่งจากในอดีตที่แต่ละพาร์ทแยกจากกัน แต่ในปัจจุบันได้มีการ Integrated ทุกสิ่งอันเข้าไว้ด้วยกัน ทำให้เราสามารถดึงประสิทธิภาพจากทุกส่วนออกมาได้อย่างเต็มที่
และสำหรับท่านที่สนใจ Services อื่นๆ สามารถเข้าไปดูรายละเอียดของ Microsoft Fabric ได้จาก Link: https://www.microsoft.com/en-us/microsoft-fabric
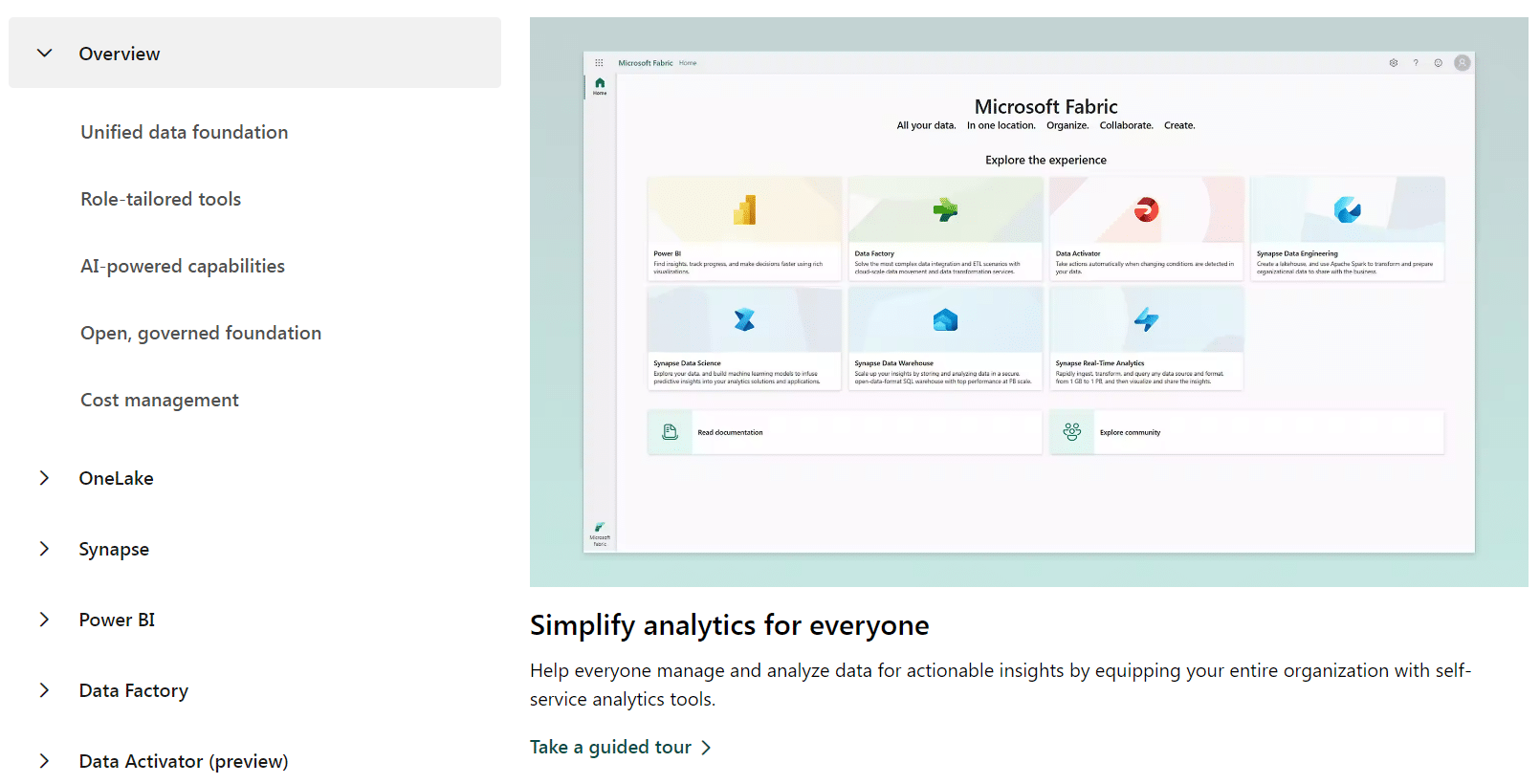
แต่สำหรับในบทความนี้ เราจะ Focus ไปที่ Software-as-a-Service (SaaS) เพื่อทำโปรเจค Data Engineer ที่ชื่อว่า Azure Data Factory ซึ่งมีรายละเอียดดังนี้ค่ะ ^^
#1 โครงสร้างของสถาปัตยกรรมข้อมูล (Data ARCHITECTURE)
เริ่มกันที่การสร้าง Pipeline ของการทำ ETL (ETL คือกระบวนการ Extract, Transform Load ซึ่งเป็นการย้ายข้อมูลจากระบบต้นทางไปยังระบบปลายทางตามช่วงเวลาหรือเงื่อนไขที่กำหนด) ซึ่งมีองค์ประกอบดังนี้
- Storage Solution ใช้เป็น Azure Blob Storage, Azure Data Lake Storage Gen2 และ Azure SQL Database
- Ingestion Solution ใช้เป็น Azure Data Factory
- Transformation Solution ใช้เป็น Data flow in Azure Data Factory, HDInsight และ Azure Databrick
- การแสดงผล ใช้เป็น Power BI
โดยมี Techstack ตามภาพด้านล่างนี้ค่ะ (สำหรับข้อมูลที่นำมาใช้ Build project จะใช้เป็นข้อมูล Covid-19 ซึ่งเป็น open source data นะคะ)
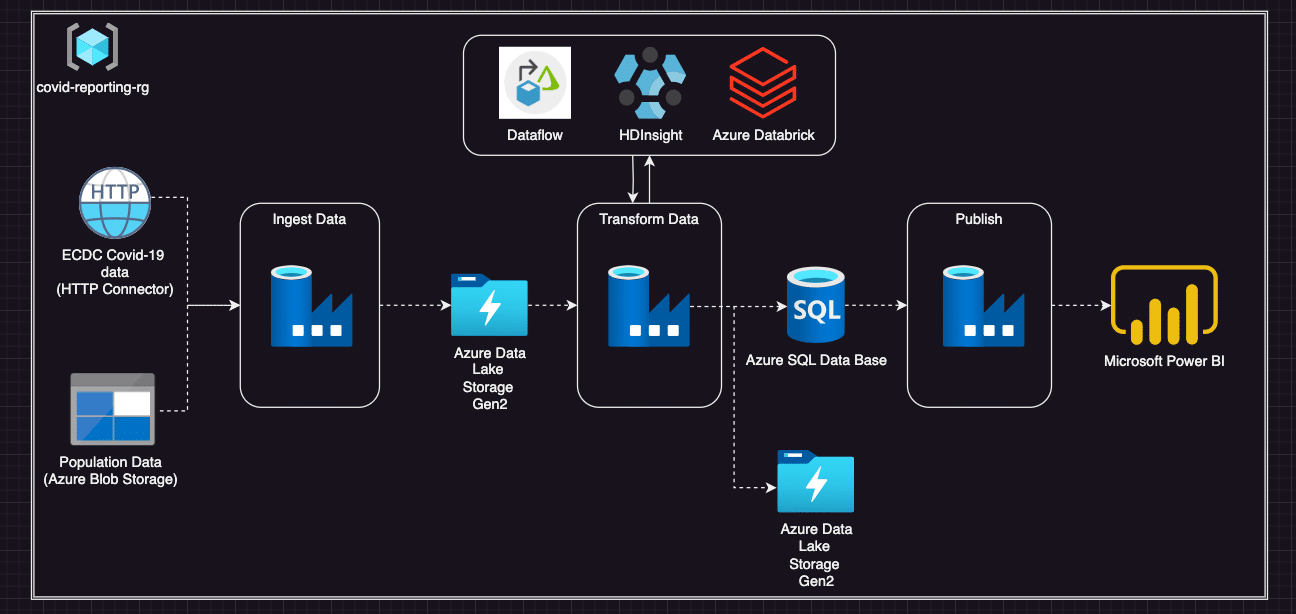
เริ่มจากเลือกใช้ Azure Data Factory (ADF) สำหรับการรวมข้อมูล เนื่องจากตัว ADF เองสามารถเชื่อมต่อเข้ากับแหล่งข้อมูล และ Database ทั้งหมดของเราใน Data Engineer Project นี้ได้ นอกจากนี้สามารถเชื่อมต่อกับข้อมูลจำนวนมากได้ด้วย ซึ่งในส่วนนี้เองค่ะ ที่หากเราต้องการที่จะ Scaleble Data Engineer Project ของเราก็สามารถทำได้ง่าย และจากการที่ Data Factory มีตัวเชื่อมต่อกับ Workflow ที่หลากหลาย ทำให้สามารถ Integrate กับ Workflow อื่นๆ ร่วมกับการทำ Data Transformation ใน HDInsight และ Azure Databricks ได้อีกด้วยค่ะ
และจาก Techstack ด้านบน จะเห็นว่าเรามีการใช้เทคโนโลยีเพื่อทำ Transformation จำนวน 3 เทคโนโลยีได้แก่การทำ Data Flow ภายใน Data Factory, HDInsight และ Azure Databricks ร่วมกันเพื่อที่เพื่อนๆ จะได้เห็นถึงความสามารถองค์รวมของ Azure Data Factory ว่าสามารถตอบสนองความต้องการของเราในเรื่องใดได้บ้างค่ะ
ซึ่งทั้ง Data Flow ภายใน Data Factory, HDInsight และ Azure Databricks ทำงานบนโครงสร้างพื้นฐานแบบกระจาย (Distributed Infrastructure) นอกจานี้จากการที่ Data Flow เป็น Tools ที่ไม่จำเป็นต้องเขียน Code ให้วุ่นวาย ทำให้เราสามารถทำ Scaleble ได้ง่ายอีกด้วยค่ะ
แต่ก็ใช่ว่า Data Flow จะมีแต่ข้อดีค่ะเพื่อนๆ,, ข้อจำกัดของ Data Flow คือเหมาะสำหรับการทำ Transformation ของข้อมูลที่มีความซับซ้อนไม่มากนักเท่านั้น ซึ่งหากเราต้องการทำ Transformation ของข้อมูลที่มีความซับซ้อนมากขึ้น จะต้องให้ Tools เพิ่มอีก 2 ตัวคือ HDInsight และ Databricks ซึ่งต้องเขียนโค้ดด้วยภาษาที่สื่อสารกับ Spark ได้เช่น Python, Scala หรือ Spark SQL หรือโค้ดในภาษาคล้าย SQL เช่น Hive หรือ Scripting language อย่าง Pig เป็นต้น
แต่สำหรับในบทความนี้จะไม่มีการใช้ HDInsight และ Azure Databricks ในโปรเจค Data Engineer ของเรานะคะ (เพียงแค่เกริ่นให้ฟังกันเฉยๆ ในกรณีที่เพื่อนๆ อย่างศึกษาเองเพิ่มเติมค่ะ 🤗🧐)
#2 Data Ingestion
2.1 Environment Setup
โดยขั้นตอน Data Ingestion คือ ขั้นตอนนี้เป็นการนำข้อมูลเข้าแพลตฟอร์มสำหรับจัดเก็บข้อมูล สามารถแบ่งการทำงานได้เป็น 2 แบบได้แก่ แบบกลุ่ม (Batch) และเรียลไทม์หรือกึ่งเรียลไทม์ (Real-time/ Near Real-time) โดยในขั้นตอนนี้เราต้องทำการ Setup ในส่วนของ Environment ที่สำคัญ โดยสำหรับ Storage เราจะใช้ Azure blob storage และ Azure Data Lake Storage Gen 2 ซึ่งมีรายละเอียดการ Setting ดังนี้ o(* ̄▽ ̄*)ブ
- การ Setup Azure blob storage
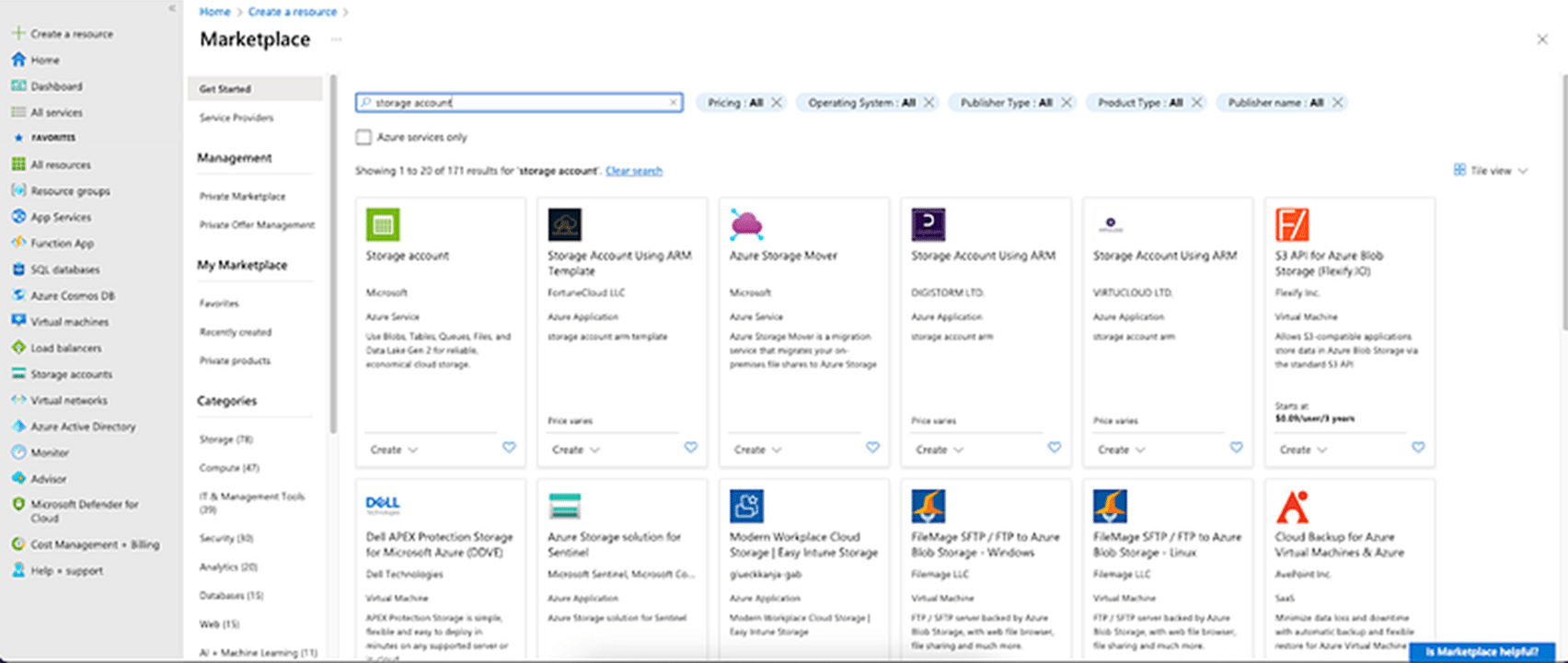
ขั้นตอนที่ 1: ไปที่ Azure Portal และค้นหา “Storage Account”
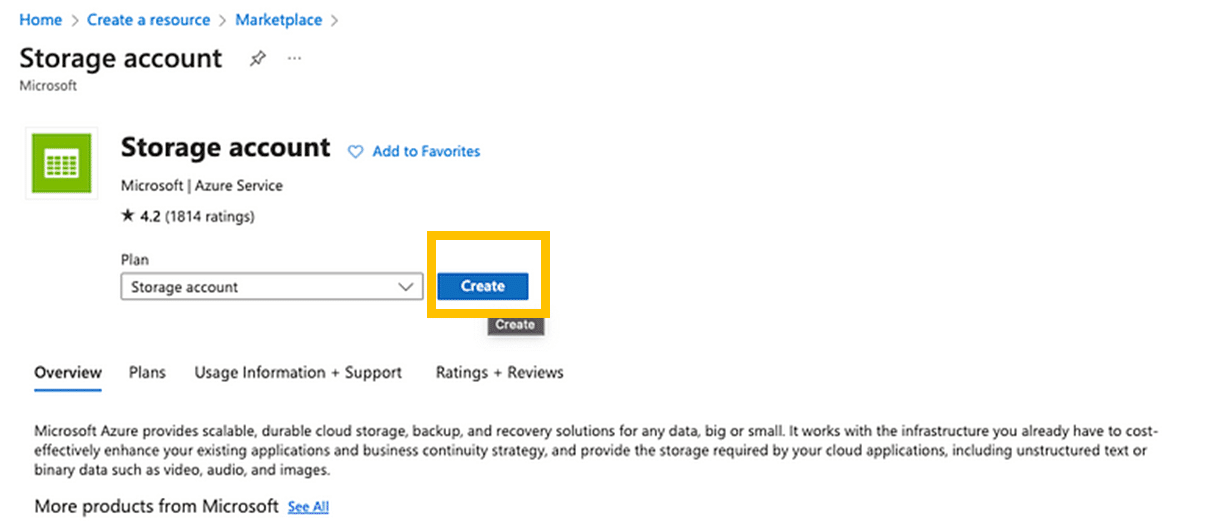
ขั้นตอนที่ 2: เลือกไปที่ Storage Account แรกเพื่อตั้งค่า Azure Blob Storage และกด Create ตามกล่องสีส้มค่ะ
ขั้นตอนที่ 3: เลือกประเภทของ subscription และ Create Resource Group โดยในบทความนี้นิกตั้งค่า Resource Group เป็น “covid” และเนื่องจากนิกไม่ต้องการวิเคราะห์ข้อมูลในวงกว้าง แต่ต้องการข้อมูลในพื้นที่ ก็เลยทำการเลือกเป็น “Locally-redundant storage (LRS)” ค่ะ
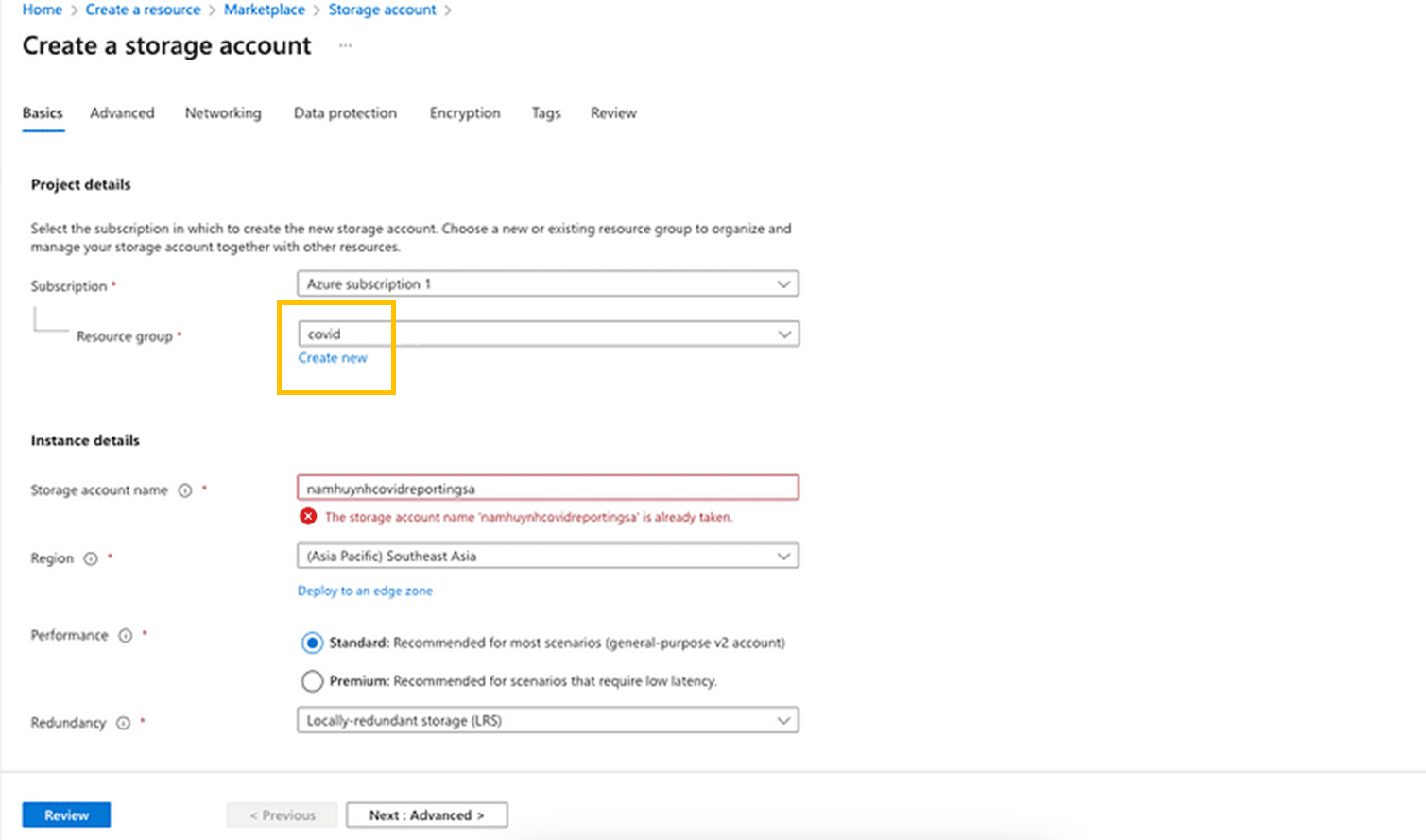
ขั้นตอนที่ 4: ตั้งค่า Networking, Data Protection, Encryption, Tags, Review โดยที่ส่วนนี้ นิกจะขอตั้งเป็นค่า Defult ไปเลย^^
ซึ่งนี่คือส่วนในการ Setting พาร์ทแรกของ Environment นั่นคือ Azure Blob Storage ค่ะ และเนื่องจากทุกพาร์ทมีรายละเอียดค่อนข้างมาก นิกจะขอแบ่งย่อยออกเป็น 2 บทความ โดยในส่วนของบทความต่อไป เราจะมาต่อกันในส่วนของการตั้งค่า Azure Data Lake Storage Gen2, Azure SQL Database, Azure Data Factory และปิดท้ายกันที่ Dashboard ตาม Data Engineer Pipelin ที่เราวางไว้กันค่ะ

Last but not Least…
หวังเป็นอย่างยิ่งว่าจากบทความนี้เพื่อนๆ จะได้ลองทำ แล้วเข้าใจเรื่องโครงสร้างของข้อมูลมากยิ่งขึ้นนะคะ ซึ่งจาก Data Engineer Pipeline ขั้นตอนยังไม่จบทั้งหมดในบทความนี้ค่ะ => พวกเราจะต้อง Setting ในส่วนของรายละเอียดเพิ่มเติมอีก ซึ่งนิกจะกล่าวถึงในบทความพาร์ทต่อไป เพื่อให้เราสามารถให้ Service ของ Azure Data Factory ได้อย่างเต็มประสิทธิภาพ — และเช่นเดิมค่ะ No-code (☞゚ヮ゚)☞ แล้วพบกันใหม่ในบทความต่อไปนะคะ^^



){kind=link}