สร้างโปรเจค Data Engineer แบบลากวางด้วย Azure Data Factory (พาร์ท2)

สวัสดีค่ะเพื่อนๆ และแล้วก็มาถึงบทความในพาร์ทที่ 2 ในการสร้าง Data Engineer Project ด้วย Azure Data Factory ซึ่งต่อเนื่องจากบทความที่แล้ว ที่เราทำการ Setting ในส่วนของการออกแบบ Ingestion บนขั้นตอนการของการ Setup Environment ส่วน Azure blob storage ไปเรียบร้อย ในบทความนี้ นิกเลยจะพาเพื่อนๆ ไปต่อให้จบทุกขั้นตอนในการสร้างโปรเจคของเรา โดยเริ่มจาก การ Setup Environment กันต่อ ,,,, ว่าแล้วก็ไปเริ่มกันเลยค่ะ ψ(`∇´)ψ
#2 Data Ingestion
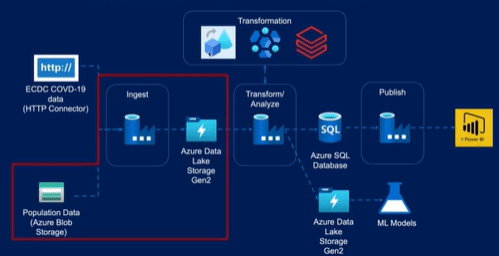
2.1 Environment Setup
- การ Setup Azure blob storage (ทำแล้วในบทความพาร์ท1: สร้างโปรเจค Data Engineer แบบลากวางด้วย Azure Data Factory (พาร์ท1))
- การ Setup Azure Data Lake Storage Gen2
ขั้นตอนที่ 1: ไปที่ Azure Portal และค้นหา “Storage Account”
ขั้นตอนที่ 2: เลือกไปที่ Storage Account แรกเพื่อตั้งค่า Azure Data Lake Storage Gen2 และกด Create
ขั้นตอนที่ 3: เลือกประเภทของ Subscription และ Create Resource Group โดยให้ตั้งค่าเช่นเดียวกับ Blob Storage ในบทความพาร์ท1 ซึ่งตั้งค่า Resource Group เป็น “covid” และเลือกเป็น “Locally-redundant storage (LRS)”
ขั้นตอนที่ 4: ตั้งค่า Networking, Data Protection, Encryption, Tags, Review โดยส่วนนี้ ให้ตั้งเป็นค่า Default - การ Setup Azure SQL Database
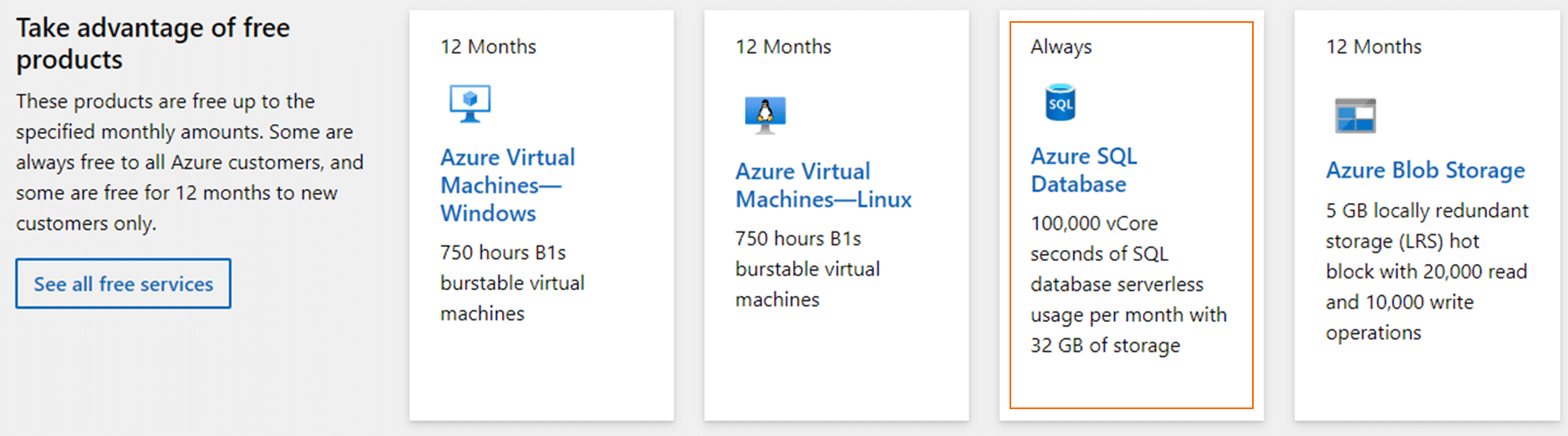
สำหรับเพื่อนๆ ที่ยังไม่มี Azure SQL Database สามารถเข้าไปที่ Link: https://azure.microsoft.com/en-us/free/sql-on-azure/#all-free-services เพื่อดูรายละเอียด และทดลองเป็นแบบ Free service ได้
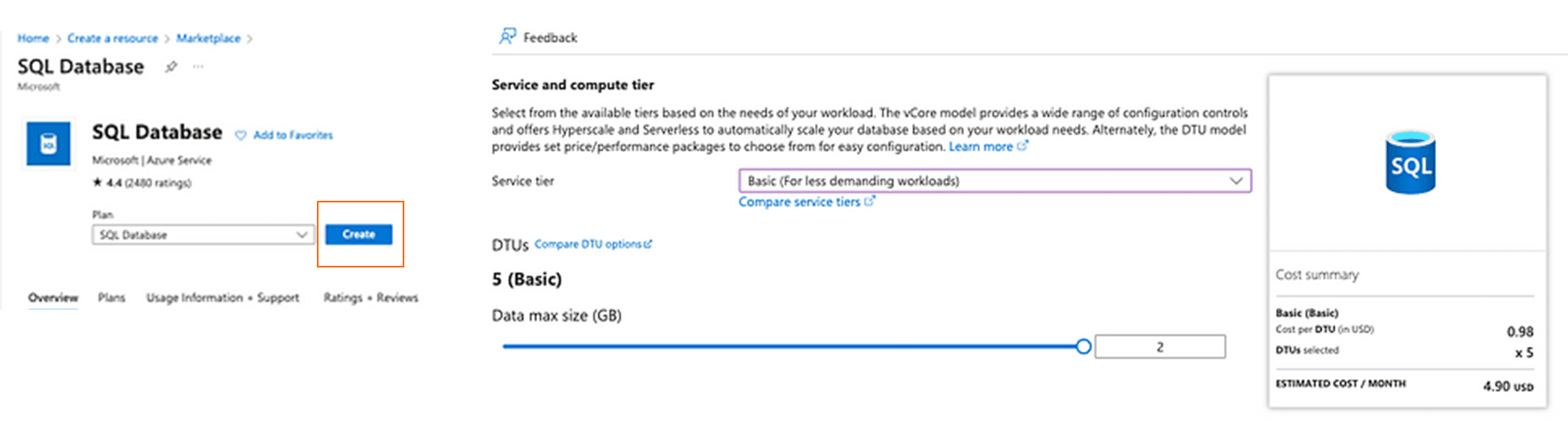
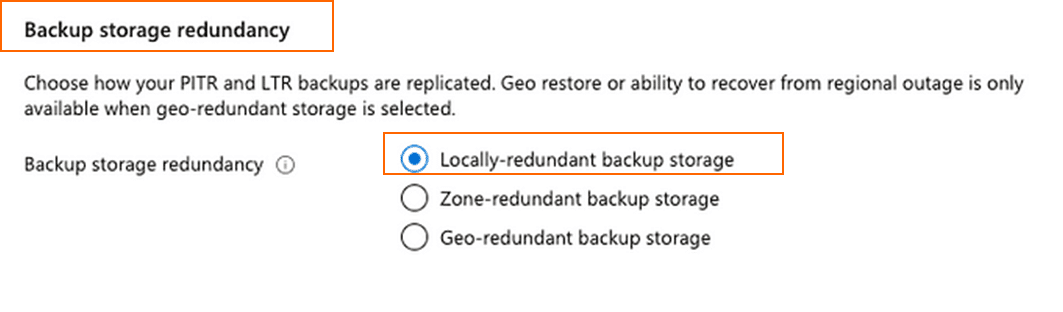
แต่สำหรับโปรเจคนี้ให้เข้าไปตามหา Database service ได้ที่ Search แล้วทำกด “Create” เพื่อสร้าง SQL Database ตามกล่องสีส้มในภาพด้านล่าง หลังจากนั้นในกรอกรายละเอียดในส่วนของ “ชื่อ” ของฐานข้อมูล และ Server ที่ต้องการให้ฐานข้อมูลนั้นเชื่อมต่อ แต่หากเรายังไม่มี Server ก็ให้ทำการ “Create” server ขึ้นมาใหม่ได้เลยค่ะ หลังจากนั้นให้ไปที่ “Configure database” แล้วเลือกในส่วน “Service Tier” ตามภาพด้านล่างเป็น “Basic (For less demanding workloads)” เนื่องจากเราต้องการประหยัดค่าใช้จ่าย แล้วเลือก Backup storage redundancy เป็นแบบ “Locally-redundant backup storage” เป็นอันเสร็จสิ้นขั้นตอนย่อยที่ 3 Setup Azure SQL Database ค่ะ (~ ̄▽ ̄)~
4. การ Setup “Azure Data Factory” สำหรับ Data Engineer Project (นี้)
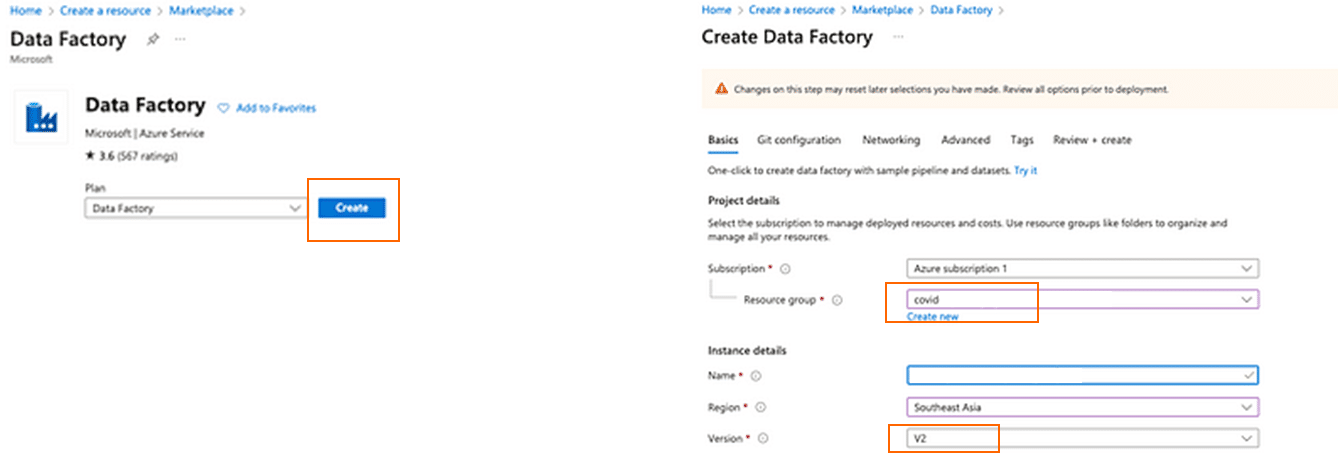
สร้าง “Data Factory” ด้วยการเข้าไป Search เซอร์วิสนี้ใน Marketplace แล้วกด “Create” ตามกล่องสีส้ม ในภาพด้านล่าง แล้วกรอกข้อมูล “Project details” ตามรายละเอียดดังต่อไปนี้
- Subscription: เลือกเป็น Azure subscription 1
- Resource group: เลือกเป็น Covid (ตามที่เราตั้งชื่อไว้จากบทความแรกค่ะ^^)
- Name: เลือกเป็นชื่อที่เราตั้งไว้ได้เลย เช่น Covid
- Region: ในที่นี้ใช้เป็น “Southeast Asia” ค่ะ
- Version: ใช้เป็น “V2”
*หมายเหตุ: อย่างไรก็ตาม ในส่วนข้อมูลการตั้งค่าดังกล่าว เพื่อนๆ สามารถเปลี่ยนแปลงรายละเอียดได้ตามแต่ Project ของตัวเองเลยนะคะ และส่วนของการตั้งค่าอื่นๆ เช่น Git, Networking และ Monitoring ในที่นี้จะเลือกเป็น Default ไว้เช่นเดิมค่ะ
และหลังจากที่เพื่อนๆ กด “Create” แล้วให้ตรวจสอบความถูกต้องของ Data Engineer Project ของเราให้เรียบร้อย =>> ซึ่งหากไม่มีแก้ไขแล้ว ให้เราทำการ 📌pin resources ทั้งหมดที่เราสร้างไว้ในหน้า dashboard ใน Azure Portal เพื่อให้สามารถตรวจสอบความเคลื่อนไหว และแก้ไขได้ง่ายๆ ต่อไป
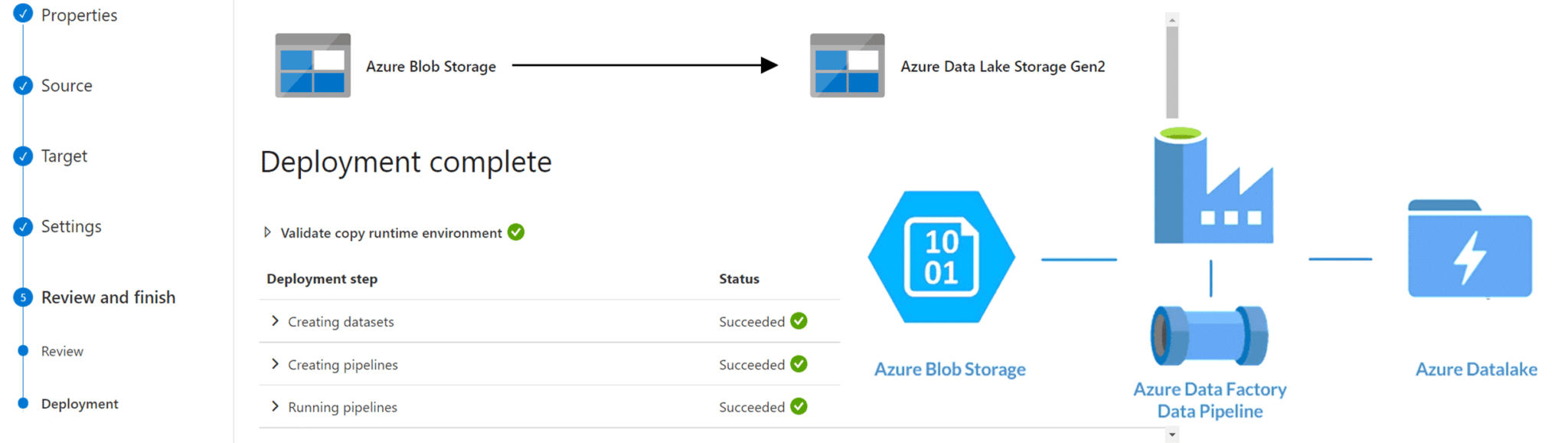
2.2 การนำเข้าข้อมูลจาก Azure Blob ไปยัง Azure Data Lake Gen2
หลังจากที่เพื่อนๆ ทำการตั้งค่า Environment และ Create “Azure blob storage” กับ “Azure Data Lake Storage Gen2” ตามขั้นหัวข้อที่ 2.1 เรียบร้อยแล้ว
ในหัวข้อนี้เราจะมานำเข้าข้อมูลจาก “Azure blob storage” ไปยัง “Azure Data Lake Storage Gen2” ซึ่งเป็น Data Lake ของเราในการใช้งาน Azure Data Factory ค่ะ^^ โดยในโปรเจคนี้เราต้องการคัดลอกข้อมูลที่เป็นไฟล์ .gz ซึ่งถูกจัดเก็บไว้ใน Azure blob ไปยัง Azure data lake ทุกครั้งที่มีการส่งไฟล์มาถึง และหลังจากที่คัดลอกข้อมูลเสร็จเรียบร้อยแล้ว ให้ทำการลบไฟล์ .gz ใน Azure blob โดยอัตโนมัติ
ซึ่งในการใช้งาน Azure Data Factory เราควรเตรียม Dataset จำนวน 2 ชุด และ link services จำนวน 2 links สำหรับ Azure Blob Storage และ Azure Data Lake Gen2 อย่างละ 1 ชุด
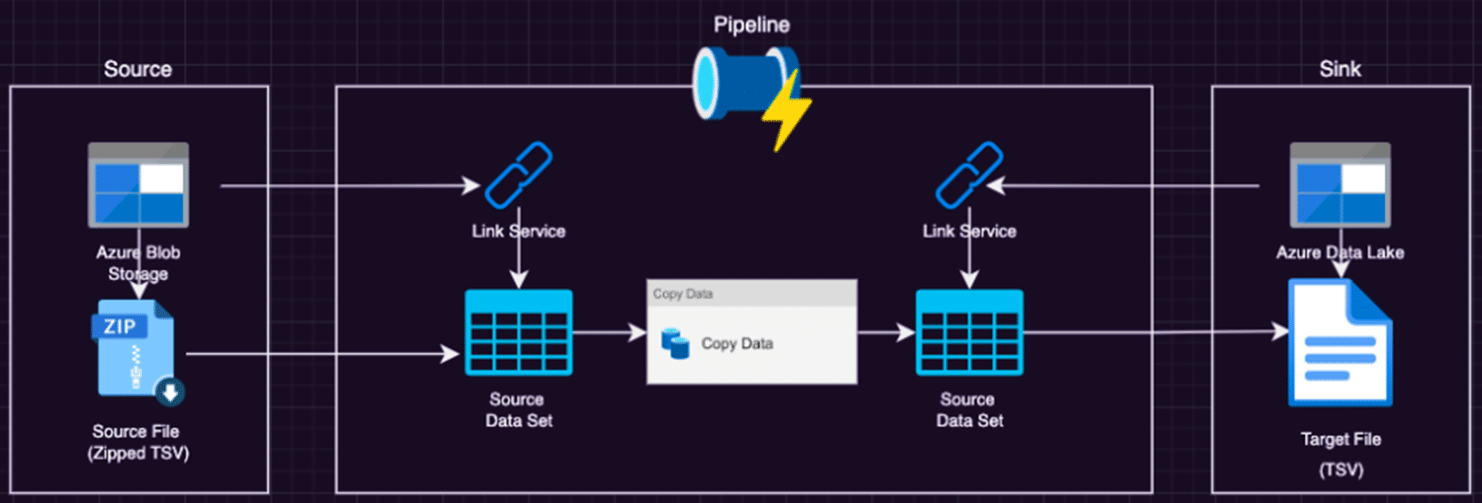
โดยในการเรียก Pipeline ของเราจะมีรายละเอียดและขั้นตอนดังต่อไปนี้
- ตรวจสอบว่ามีไฟล์ที่เราต้องการ (ในที่นี้เป็นไฟล์ .gz) อยู่หรือไม่ หากมีไฟล์ให้ get ไฟล์ metadata ของไฟล์นั้นมา โดยให้ทำการตรวจสอบด้วยว่าจำนวน metadata ตรงกับจำนวน columns หรือไม่ ซึ่งหากตรงกันแล้ว ให้ทำการ copy เอาไว้ แล้วลบไฟล์ดังกล่าวจาก source ซึ่งในที่นี้คือ Blob Storage ได้เลย
- พิจารณาชุดข้อมูลที่จะต้อง ingest ไปยัง Data Lake ของเราว่ามีจำนวนกี่ชุด (ในที่นี้ dataset ของเราจะเป็นไฟล์ .csv) ซึ่งในขั้นตอนนี้เราไม่จำเป็นต้องทำแบบ Manual นะคะ เพราะเราสามารถใช้ “Lookup Activity” ในการ “Lookup” แต่ละ Information ใน Data ได้เลย โดยการใส่ข้อมูลทั้งหมดเกี่ยวกับ sourceBaseURL, sourceRelativeURL และ sink File ลงใน json ไฟล์ แล้วใช้ “For Each Activity” ในการทำซ้ำในส่วนของ “Copy Activity”
- หลังจากนั้นให้เราทำการ “Debug” เพื่อให้ชุดข้อมูลทั้งหมดของเราถูกนำเข้าไปอยู่ใน Azure Data Lake Storage Gen2
#3 Data Transformation for Data Engineer project
และเมื่อเราทำ Data Ingestion เสร็จเรียบร้อยตามกระบวนการในขั้นตอนที่ 2 ก็มาถึงส่วนของขั้นตอนต่อไป นั่นคือการทำ Data Transformation หรือการแปลงข้อมูล โดยเริ่มจากการพิจารณาข้อมูลที่เราต้องการทำ Transform ว่าเราอยากได้ข้อมูลสุดท้ายในรูปแบบไหน มีรายละเอียดอย่างไร โดยเลือกเก็บเฉพาะ Column ที่เราต้องการไว้ และแปลงข้อมูลในคอลัมน์นั้นให้อยู่ในลักษณะที่เราจะนำไปใช้ต่อ

และจากภาพการทำ Data Transformation ในโปรเจค data engineer บน Azure จะเริ่มจาก การสร้าง Pipeline ใหม่ใน Azure Data Factory หลังจากนั้นให้เพิ่มกิจกรรม “Copy Data” ลงใน Pipeline นั้น และกำหนดแหล่งข้อมูล/เป้าหมายให้กิจกรรม “Copy Data” แล้วให้พวกเรากำหนดหรือตั้งค่าการ Transform สำหรับ “Copy Data” เมื่อเรียบร้อยแล้ว ก็สามารถเรียกใช้ Pipeline ที่เราสร้างไว้ได้เลยค่ะ😃✨
โดยในส่วนของการทำ Transformation สามารถทำได้หลายแบบผ่านการเลือกลากสิ่งที่เราต้องการจะทำมาได้ง่ายๆ ยกตัวอย่างเช่น การทำ Transformation ด้วยการใช้สูตรต่างๆ, การแปลงรูปแบบของข้อมูลจากรูปแบบหนึ่ง ไปยังอีกรูปแบบหนึ่ง (เช่นการแปลงในเรื่องของวัน/เวลา) หรือการ Aggregated ข้อมูลจากหลายแหล่งข้อมูล เป็นต้น^^
นอกจากนี้เราย้งสามารถใช้ Tools ต่างๆ ใน Azure ในการทำ Data transformation ด้วยวิธีที่หลากลายออกไป อย่างเช่น
- การใช้ Azure Synapse Analytics ที่สามารถใช้คำสั่ง SQL เพื่อแปลงข้อมูลได้
- การใช้ Azure Databricks ร่วมกับการสร้าง Spark dataframe จากข้อมูลที่เราต้องการ และใช้ Spark API ในการแปลงข้อมูล ซึ่งเหมาะกับการรวบรวมข้อมูลที่พวกเรา(น่าจะ)คุ้นเคย นั่นคือข้อมูลแบบ Dataframe นั่นเองค่ะ ☜(゚ヮ゚☜)
#4 Data Warehouse
เมื่อเราดำเนินการแล้วเสร็จตั้งแต่ขั้นตอนที่ 1-3 แล้ว ก็จะเข้าสู่ขั้นตอนของการย้ายข้อมูล (Transformation Data) จาก Azure Data Lake Storage Gen2 ไปยังฐานข้อมูล SQL (ตอนนี้ฐานข้อมูลของเราจะเป็น Azure Data Lake และ SQL Database ใช้เป็น Sink นะคะ^^)
โดยกระบวนการ Data Warehouse ตามสถาปัตยกรรมที่เราใช้ในบทความจะประกอบด้วยขั้นตอนต่อไปนี้:
- การเตรียม Database และ Links สำหรับ Sink ที่ใช้เป็นฐานข้อมูล SQL ซึ่งเราจะต้องสร้างการเชื่อมต่อกับฐานข้อมูล SQL และกำหนด Table เป้าหมาย
- การ Create Table หรือสร้างตารางสำหรับข้อมูลที่เราจะทำการ “ย้าย” โดยในขั้นตอนนี้ เราจะต้องสร้างตารางแยกในข้อมูลแต่ละประเภท เช่น “ตารางสำหรับผู้ป่วยรายวัน”, “ตารางสำหรับข้อมูลการทดสอบ” เป็นต้น (ป.ล. เผื่อเพื่อนๆ ท่านไหนลืม สำหรับ Data Engineer โปรเจคนี้ จะเป็นข้อมูล Covid-19 นะคะ)
- การ Copy ข้อมูลจาก Azure Data Lake Storage Gen2 ไปยังฐานข้อมูล SQL โดยใช้การ “Copy Data” ใน Azure Data Factory (หรือเพื่อนๆ ที่ถนัด SQL ก็สามารำถใช้คำสั่ง SQL ในการดำเนินการได้เลยค่ะ)
ซึ่งเมื่อข้อมูลของเราถูกย้ายไปยัง SQL Database เรียบร้อยแล้ว เราก็จะสามารถนำข้อมูลนั้นมาวิเคราะห์ หรือทำ Data Visualization ได้ต่อไป เช่น สำหรับชุดข้อมูลนี้เราจะวิเคราะห์จำนวนผู้ป่วยรายวันที่ได้รับการรักษาในโรงพยาบาลเป็นต้น (^∀^●)ノシ
# Lastly, ทำ Pipeline โปรเจค Data Engineer ให้พร้อมใช้งาน
ในที่สุดก็มาถึงส่วนสำคัญส่วนสุดท้าย ซึ่งคือการทำให้โปรเจค Data Engineer ที่เราสร้างมาพร้อมใช้งาน และสามารถดำเนินการได้แบบ “Fully Automated” โดยที่ไม่ต้องมาสั่งการแบบ manual อีกต่อไป ด้วยการที่เราให้ Azure Data Factory Pipeline เป็นเวิร์กโฟลว์ที่กำหนดวิธีการประมวลผล และย้ายข้อมูลระหว่างที่เก็บข้อมูลต่างๆ ให้สามารถทำงานที่หลากหลายได้ เช่น การนำเข้าข้อมูลจากแหล่งต่างๆ, การประมวลผลข้อมูล และการโหลดข้อมูลลงใน Database หรือ Data storage อื่นๆ
โดยเริ่มต้นจากการตั้งค่าให้ Pipeline เริ่มการรันกระบวนการ (Process) ด้วย Trigger ที่เป็น events เช่น การมีข้อมูลใหม่ถูกป้อนเข้ามา หรือมีการเปลี่ยนแปลงข้อมูลใดๆ ก็ตาม แล้วตั้งค่าให้ทำ Transformation เฉพาะในกรณีที่มีการทำ Data Ingestion แล้วเสร็จเท่านั้น (เพื่อนๆ สามารถกลับไปอ่านรายละเอียดได้ที่ #2 Data Ingestion นะคะ) ทั้งนี่เพื่อเป็นการให้ Pipeline ของเราสามารถตรวจสอบความถูกต้อง และประสิทธิภาพได้ง่าย
เมื่อเราพิจารณาถึง Requirements ที่ต้องการอย่างครบถ้วนแล้ว ก็ให้เรามาดูในส่วนของ Azure Data Factory ค่ะว่ามีเซอร์วิสอะไรให้เราใช้บ้าง เพื่อให้เราสามารถเชื่อมโยง “Activities” ที่เรา setup ไว้ก่อนหน้าให้ทำงานตามลำดับที่เราตั้งค่าไว้ได้ ซึ่งในส่วนนี้เราสามารถเชื่อมต่อ (Chain) ไปป์ไลน์ที่เราต้องการกับ “parent pipeline” และ trigger อื่นๆได้ด้วย 💬🕸
กลับมาที่โปรเจค Data Engineer ที่เราสร้างไว้ด้วย Data Factory ของเรากันค่ะ ซึ่งตอนนี้เรามี Pipeline จำนวน 8 ชุด, Dataset จำนวน 17 ชุด และมี 3 Data flows ซึ่งเพื่อให้ง่ายในการดำเนินการ เราจะจัดกลุ่มของไปป์ไลน์เป็น Folders แบ่งตามวัตถุประสงค์ของไปป์ไลน์นั้น เช่น โฟลเดอร์ ingestion, processing และ SQL และทำการจัดกลุ่ม datasets ประเภทเดียวกันป็นโฟลเดอร์ด้วยเช่นกัน ได้แก่ โฟล์เดอร์ raw data, process และ SQL dataset ตามภาพด้านล่าง

หลังจากนั้นเราจะสร้างไปป์ไลน์หลัก ด้วยการ create “parent pipeline” และรวม Ingestion กับ Processing pipelines เข้ากับไปป์ไลน์หลักนั้นด้วย แล้วให้เราทำการ “Publish” ก็จะเป็นอันเสร็จเรียบร้อยสำหรับ Data Engineer ของเราค่ะ (^U^)ノ~YO

Last but not Least…
หลังจากจบบทความทั้ง 2 พาร์ทเรื่องการสร้าง Data Engineer Project แบบ Low-code ด้วยการลากวางด้วย Tool Azure Data Factory นี้ หวังเป็นอย่างยิ่งว่าเพื่อนๆ จะได้ลองทำ และมีความเข้าใจเรื่องโครงสร้างของข้อมูลมากยิ่งขึ้น หรือสามารถสื่อสารเพื่อระบุ Requirements ของเราให้หน่วยงานที่ทำเรื่องนี้ช่วยเรารวบรวมข้อมูลได้อย่างมีประสิทธิภาพ และตอบโจทย์ในการทำการตลาด หรือการวิเคราะห์ข้อมูลต่อไป^^
ป.ล. บทความพาร์ท 1 สามารถอ่านได้ตามนี้ค่ะ =>>



){kind=link}