Data Architecture: โครงสร้างข้อมูลจากอดีตสู่ปัจจุบัน และอนาคตที่ควรรู้เพื่อการใช้งาน

สวัสดีค่ะเพื่อนๆ หรือใครที่ทำงานเกี่ยวเนื่องกับการใช้ข้อมูล หรือการนำข้อมูลมาวิเคราะห์ ไม่ว่าจะเป็นข้อมูลของลูกค้า ข้อมูลการขายแต่ละ transactions หรือข้อมูลการเข้าใช้งานแพลตฟอร์ม โดยข้อมูลเรานี้ถูกเก็บใน Data Architecture หรือโครงสร้างของข้อมูลที่แตกต่างกันออกไป และมีการปรับเปลี่ยนรูปแบบ จากอดีต มาสู่ปัจจุบัน และพัฒนาไปสู่อนาคต
ซึ่งในการนำข้อมูลมาใช้งาน มักจะมีอีกทีมหนึ่งที่มีหน้าที่ดึงข้อมูลมาให้เราชาว Data Analyst หรือ Marketer วิเคราะห์ต่อกันใช่ไหมคะ =>> จากตรงนี้เองที่ทำให้สิ่งที่เราเห็นเป็นเฉพาะในส่วนของข้อมูลที่ถูกดึงมาแล้ว 😊📰
ในบทความนี้นิกจึงอยากพาทุกท่านไปทำความรู้จักกับโครงสร้างของข้อมูล หรือ Data Architecture ในรูปแบบต่างๆ ที่มีการใช้งานกันตั้งแต่อดีต (ซึ่งปัจจุบันก็ยังมีใช้อยู่) สู่ปัจจุบัน และจะแนะนำให้รู้จักกับโครงสร้างของข้อมูลที่จะมีการนำมาใช้มากขึ้นในอนาคต 🚀📤 โดยจะแบ่งรูปแบบของโครงสร้างข้อมูลเป็น 3 รูปแบบหลัก ได้แก่
- Data Warehouse: ระบบคลังข้อมูล
- Data Lake =>> ไม่รู้จะเรียกเป็นภาษาไทยว่าอะไรจริงๆ ค่ะ 🤣🤣
- Data Mesh =>> โครงสร้างของข้อมูลที่รองรับการ Decentrialized
ถ้าอย่างนั้นเรามาเริ่มต้นกันที่ระบบโครงสร้างข้อมูลที่มีการใช้งานกันมากในอดีต (แต่ย้ำนะคะว่า ปัจจุบันก็ยังมีใช้อยู่) ซึ่งก็คือ Data Warehouse กันเลยค่ะ (☞゚ヮ゚)☞
#1st Generation
Data Warehouse: ระบบคลังข้อมูล
โดยโครงสร้างข้อมูลแบบ Data Warehouse ถูกนิยามโดยการถ่ายโอนหรือ transfer ดาต้าระหว่างระบบปฏิบัติการ (เช่น SAP, Salesforce) และฐานข้อมูลที่มีการเก็บรวบรวมมาจากผู้ใช้งาน หรือภาคธุรกิจเก็บข้อมูลมาเอง (1st party databases จาก MySQL หรือ SQL server) สู่การทำ BA (Business Intelligence)
ซึ่ง Data Warehouse เป็นฐานข้อมูลชนิดรวมศูนย์ (Central Point) ขนาดใหญ่ ที่ถูกเซต Schema หรือโครงสร้างของความสัมพันธ์ของข้อมูลไว้อย่างชัดเจน เช่น snowflake schema หรือ star schema เป็นต้น โดยทำการเก็บในลักษณะของการ Query ข้อมูล หรือ Fact มา เก็บต่อไปเรื่อยๆ แล้วเพิ่มรายละเอียดจากบาง Columns ในส่วนของตารางแสดงรายละเอียดของข้อมูล (Dimension) ลงไป เช่น การเลือกว่าจะเก็บเฉพาะข้อมูลการขายอาหารแมว ในจังหวัดสระบุรี ในแต่ละสัปดาห์

โดยข้อมูลที่เก็บไว้จะมีลักษณะเป็น Historical Data ซึ่งต้องมีกระบวนการการส่งผ่านข้อมูลจาก Database แบบ Periodic (การ Query ข้อมูลมาเป็นระยะ) ซึ่งเรียกว่าการทำ ETL หรือ Extract Transfor Load แต่!!!! พอเรา Query ข้อมูลมาลง Data Warehouse แล้วจะแก้ไขค่อนข้างยากค่ะ ซึ่งถ้าเราต้องการแก้ไขจริงๆ จะต้องมีกระบวนการเพิ่มเติมอีก
และจากลักษณะของข้อมูลที่เก็บมาทำให้ภาคธุรกิจสามารถพิจารณาถึงความสัมพันธ์ระหว่างแต่ละข้อมูล และความเปลี่ยนแปลง ตลอดจนปฏิกิริยาของลูกค้าที่ตอบสนองต่อสิ่งต่างๆ ได้ และใช้เพื่อการวิเคราะห์ สร้าง report เพื่อตอบคำถามได้^^
*นิกขอเพิ่มเติมในส่วนของคำศัพท์ที่ควรรู้ด้าน Data เพื่ออรรถรสในการอ่านบทความ (ทั้งบทความนี้และบทความอื่นๆ) เผื่อว่าเพื่อนๆ จะเจอคำศัพท์เทคนิค ดังนี้นะคะ,,,,
1>> Fact: ข้อมูลที่เกิดขึ้นจริง และเราทำการบันทึกไว้เป็น transaction เช่น ข้อมูลการซื้อ-ขาย หรือข้อมูลการเข้าใช้งาน application หรือแพลตฟอร์ม โดย
2>> Dimension: หรือ Master data เป็นตารางที่แสดงรายละเอียดของข้อมูลอีกที เช่น ตารางข้อมูลส่วนบุคคลของลูกค้า ตารางรายละเอียดสินค้า หรือ Calendar ที่แสดงว่าวันที่นี้ คือสัปดาห์ เดือนอะไร ปีที่เท่าไหร่ เป็นต้น โดย Dimension จะต้องเป็นข้อมูลที่ห้ามซ้ำ (Unique) หรือเป็น Primary key ของตารางนั้นๆ

ซึ่งความยากในการระบบการเก็บข้อมูลยุคแรกหรือแบบ Data Warehouse ที่ทำให้เกิดการพัฒนามาเป็นโครงสร้างข้อมูลแบบต่อไปมีดังนี้ค่ะ ༼ つ ◕_◕ ༽つ
- จากการที่ Data Warehouse ส่งผ่านข้อมูล Operational data ผ่าน Data pipelines โดยกระบวนการ ETL ทำให้เมื่อเวลาผ่านไป จะทำให้ตัวตาราง รายงานที่ถูกสร้างขึ้นมา มีเฉพาะผู้ที่ดูแลข้อมูล หรือผู้เชี่ยวชาญเท่านั้นที่จะเข้าใจ และสามารถ maintain ระบบได้
- แนวทางการจัดการข้อมูลรูปแบบใหม่ เช่น CI/CD ไม่สามารถนำมาใช้ร่วมด้วย
- โครงสร้างข้อมูลแบบ Data Warehouse และ Schema ค่อนข้างไม่ยืดหยุ่นในการใช้งานกับข้อมูลขนาดใหญ่ ซึ่งประกอบด้วยทั้งข้อมูลที่เป็น structured และ unstructured data จากแหล่งข้อมูลที่หลากหลาย
#2nd Generation
Data Lake: รองรับข้อมูลได้หลากหลาย
สถาปัตยกรรมโครงสร้างข้อมูลแบบ Data Lake ถูกเปิดตัวครั้งแรกในปี 2010 เพื่อแก้ไข challenges ของการใช้งาน Data Warehouse ให้ตอบสนองต่อใช้งานข้อมูลที่เปลี่ยนแปลงไปจาก Data Analyst ที่มีการนำข้อมูลที่หลากหลายไปวิเคราะห์/สร้าง ML โมเดล หรือแม้แต่ Marketer ที่ต้องการทำ Social listening ก็เช่นเดียวกันค่ะ^^
โดย Ecosystem ที่เรามักจะคุ้นเคยกันดีและเหมาะกับการทำ Data Lake คือ Hadoop หรือ Apache Hadoop ที่มีการจัดเก็บข้อมูลใน HDFS หรือ Hadoop Distributed File System ที่มีการส่งผ่านข้อมูลที่ถูกแบ่งออกเป็นก้อนๆ (Block) และประมวลผลแบบกระจาย ระหว่างคอมพิวเตอร์ที่เชื่อมต่อกันในระบบ (Clusters) ซึ่งถูกบริหารทรัพยากร และจัดตารางเวลาการทำงานตามชุดคำสั่งอย่างเป็นระบบ
โดยส่วนประกอบหลักของ Hadoop framework ได้แก่,,,,
1>> HDFS: Hadoop Distributed File System เป็นหน่วยเก็บข้อมูล โดยเป็นการเก็บข้อมูลกระจายไปในหลายคอมพิวเตอร์หลายๆ เครื่อง
2>> Map Reducer: ใช้ในการสั่งการประมวลผลของข้อมูล
3>> YARN: ใช้ในการจัดลำดับการทำงานให้ Task แต่ละ Task และจัดการ Resources ต่างๆ

(แต่จริงๆ แล้วการสร้าง Data Lake ขึ้นมานี่ก็มีหลากหลายรูปแบบนะคะ แล้วแต่ลักษณะของข้อมูล หรือ infrastruture ต่างๆ ที่ระบบ provide ให้เลยค่ะ)
โดยในส่วนของ Data Lake จะสามารถเก็บข้อมูลได้หลากหลายทั้งในรูปแบบของ Structured, Semi-structured และ Unstructered data หรือพูดง่ายๆ ค่ะว่า คือการเก็บข้อมูลทุกอย่างเข้าระบบมาก่อน ไม่ว่าจะเป็นข้อมูลที่คิดไว้แล้วว่าจะมีการนำไปวิเคราะห์ต่อ หรือข้อมูลที่เรายังไม่รู้ว่าจะนำไปใช้งานอะไรต่อ (แต่คิดว่าอาจได้ใช้ในอนาคต) ซึ่งลักษณะของข้อมูลเป็นได้ทั้งในรูปแบบตาราง ไฟล์งานต่างๆ รวมถึงภาพและวิดีโอ เนื่องจากการ provide ข้อมูลจากแพลตฟอร์มต่างๆ ในยุคปัจจุบันที่มีความหลากหลาย หรือมีความเป็น Big Data (เพราะฉะนั้น,,,,เพื่อนๆ ลืมเรื่องความเป็นระเบียบของข้อมูลที่อยู่ใน Data Lake ไปได้เลยค่ะ 🤣🤣)

ซึ่งนิกมองว่าจริงๆ แล้ว Data Lake ไม่ได้ถูกนำมาใช้งานเพื่อแทนที่ Data Warehouse นะคะ เนื่องจากลักษณะของการจัดเก็บข้อมูลที่ไม่เหมือนกัน แต่ทั้ง 2 แบบจะถูกนำมาใช้ร่วมกันตามแต่ความต้องการ เช่นถ้าต้องการข้อมูลที่พร้อมที่จะนำไปวิเคราะห์ต่อทันที แบบไม่ต้องเข้ากระบวนการอะไรอีกแล้ว Architecture แบบ Data Warehouse ก็จะเหมาะกว่า
ซึ่งความยากในการระบบการเก็บข้อมูลแบบ Data Lake ที่ทำให้เกิดการพัฒนามาเป็นโครงสร้างข้อมูลแบบต่อไปมีดังนี้ค่ะ ༼ つ ◕_◕ ༽つ
- เนื่องจากข้อมูลที่ถูกจัดเก็บใน Data Lake เป็นข้อมูลที่หลากหลาย และอะไรก็ได้ 🤣🤣 เลยทำให้คุณภาพของข้อมูลที่อยู่ในนั้นค่อนข้าง poor และขาด reliability
- ถ้าเพื่อนๆ ดูจากรูป Framework ของ Hadoop จะเห็นว่า data piplines ค่อนข้างมีความซับซ้อน ทำให้ผู้ที่ดูแลระบบต้องมีความเชี่ยวชาญ
- จากการที่เป็นข้อมูลที่ไม่ได้รับการจัดการ ทำให้บางที value ที่จะได้จากข้อมูลที่ถูกเก็บใน Data Lake ไม่มีคุณค่าเท่าที่ควร
- ตามหาที่มาที่ไปของข้อมูลได้ค่อนข้างยาก และเนื่องจากการไม่ได้ออกแบบโครงสร้างมาก่อน ทำให้การ mapping ข้อมูลแต่ละ data sources ค่อนข้างลำบาก
#3rd Generation
Cloud Data Lake: ดาต้าเลคที่อยู่บนคลาวด์
และจาก difficulties ต่างๆ ที่เกิดจากการใช้งาน Data Lake ในยุคที่ 2 เลยเป็นที่มาของการพัฒนาสู่ Cloud Data Lake หรือดาต้าเลคที่อยู่บนระบบคลาวด์ ซึ่งสามารถรองรับการใช้งานของ และการจัดเก็บข้อมูลแบบ Real-time และการควบรวมกันระหว่าง Data Warehouse และ Data Lake
โดยการที่เรามีความต้องการประมวลผลข้อมูลในแบบ real-time หรือ near real time เนื่องจากเราปัจจุบันข้อมูลที่ถูก feed เข้ามาเป็นข้อมูล Streaming ซึ่งรูปแบบโครงสร้างข้อมูลแบบเดิมไม่สามารถดำเนินการให้ได้ เป็นที่มาของ Architecture แบบ Kappa ที่จะมองข้อมูลทุกประเภท ที่ถูกป้อนเข้ามาเป็น Streaming และไม่ block การประมวลผลในรูปแบบ batch ทำให้สามารถใช้ rawdata จาก Data Lake ไปประมวลผลผ่าน real-time processing และทำ Analytics ได้เลย
ซึ่ง Kappa แบ่งเป็น 2 layers คือ
1>> Speed layer: เลเยอร์ของข้อมูลที่ถูก Streaming เข้ามา โดยในเลเยอร์นี้เราสามารถเขียนโปรแกรมต่างๆ ลงไปได้เลย (ซึ่งแตกต่างจาก Architect แบบ Lambda,,,,เพื่อนๆ ลองไปอ่านเพิ่มเตมกันดูนะคะ นิกไม่ได้เขียนไว้ในบทความนี้ เดี๋ยวจะยาวเกิน (❁´◡`❁))
2>> Serving layer เป็นเลเยอร์ที่จะใช้เก็บผลลัพธ์ที่ได้จากการประมวลผลจากข้อมูล และโปรแกรมใน Speed layer

ซึ่งการเก็บข้อมูลแบบ Cloud Data Lake ก็ยังคงมีความยากอยู่ ซึ่งความยากที่ทำให้เกิดการพัฒนามาเป็นโครงสร้างข้อมูลแบบต่อไปมีดังนี้ค่ะ ༼ つ ◕_◕ ༽つ
- โครงสร้างของการเก็บข้อมูลแบบ Cloud data lake ยังคงมีความซับซ้อนมากกกกก ด้วยความที่มีหลาย Layer และแต่ละเลเยอร์ยังต้องมีเครื่องมือที่นำมาใช้ร่วมด้วยอีก
- จากการที่ tools เยอะมากกกก ทำให้หาผู้เชี่ยวชาญมาควบคุมระบบยากให้เสถียร มีความยากขึ้นไปอีก และดูแลค่อนข้างยากค่ะ
- ถึงแม้จะทำ CI/CD ได้ แต่ด้วยความซับซ้อนก็ทำยากอีกเช่นกัน
#4th Generation
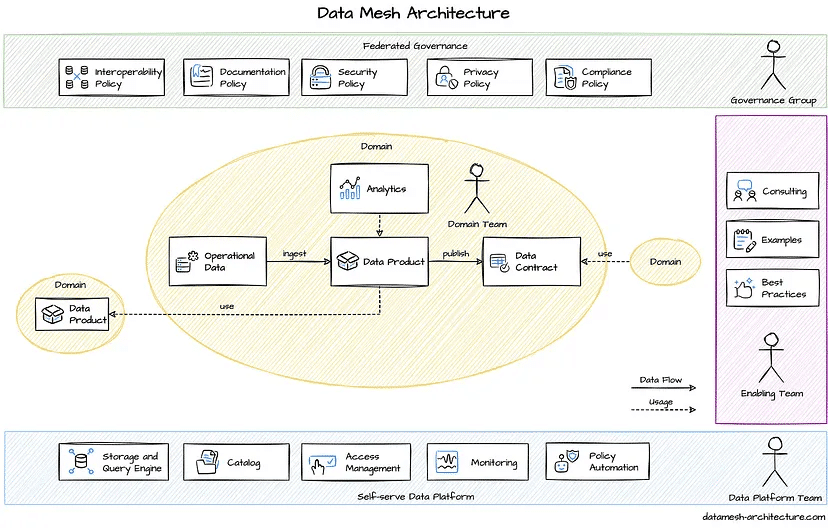
Data Mesh Architecture
และแล้วก็มาถึงโครงสร้างข้อมูลน้องใหม่แบบสุดท้ายที่นิกจะเล่าให้เพื่อนๆ ฟังในบทความนี้ค่ะ ซึ่งจากโครงสร้างของข้อมูลที่ถูกกล่าวถึงมาทั้งหมดก่อนหน้า ทั้ง Data Warehouse, Data Lake และ Cloud Data Lake ล้วนเป็นการจัดเก็บข้อมูลแบบรวมศูนย์ หรือ Centralized

แต่ Data Architecture แบบ Data Mesh เป็นการจัดการโครงสร้างของข้อมูลแลลกระจายศูนย์ (Decentralized Architecture) ที่จะแบ่งโครงสร้างตาม Data domain ที่จะให้อำนาจแต่ละหน่วยงานที่เกี่ยวข้องเป็นเจ้าของข้อมูล (product) และทำหน้าที่บริหารจัดการ รับผิดชอบข้อมูลใน domain ของตัวเองไปเลย ซึ่ง data owner สามารถกำหนดสิทธิ์ในการเข้าถึง product ของ domain ที่ตนถือครองอยู่ได้ ซึ่งนี่เองคือความต่างจาก Data Architecture รูปแบบเดิม ที่หน้าในการบริหารข้อมูลนั้น เป็นของผู้เชี่ยวชาญหรือหน่วยงาน Centralized เท่านั้น
โดยส่วนประกอบสำคัญของโครงสร้างข้อมูลแบบ Data Mesh ประกอบด้วย,,,,
- Domains — หน่วยงานที่เป็นเจ้าของข้อมูล ซึ่งมีหน้าที่บริหารจัดการข้อมูลใน domains ของตนเอง
- Data Products — ข้อมูลที่เป็น end result ซึ่งถูก provide โดย data domain ที่เป็นเจ้าของข้อมูล เพื่อให้ domains อื่นสามารถเข้ามาร่วมใช้งานได้ ผ่านการกำหนดสิทธิ์
- Data Infrastructure — โครงสร้างของข้อมูล ที่ประกอบด้วย tools ต่างๆ เในการบริหารจัดการข้อมูลใน domain นั้น
- Data Governance — การกำหนดสิทธิ หน้าที่ และความรับผิดชอบในการบริหารจัดการข้อมูล
- Mesh API — เป็น microservice ในการ expose ข้อมูลผ่าน HTTP REST APIs

Last but not Least…
จาก Story เรื่องของพัฒนาการโครงสร้างข้อมูลในแต่ละ Generations จะเห็นว่าทุก Data Architectures ต่างก็มี pros และ cons ของตัวเอง ซึ่งการเลือกใช้รูปแบบใดก็ตามขึ้นอยู่กับความเหมาะสมของปลายทางที่เราต้องการนำมาวิเคราะห์ หรือเป้าหมายของการเก็บข้อมูล ซึ่งนิกเชื่อว่าความเข้าใจในเรื่องของโครงสร้างข้อมูล จะทำให้เพื่อนๆ นั้นการตลาด สามารถมองภาพรวมของการนำข้อมูลมาวิเคราะห์ได้ง่ายขึ้น และสามารถสื่อสารกับหน่วยงานที่ทำหน้าที่กรองข้อมูลออกมาเพื่อให้เราวิเคราะห์ได้อย่างตรงประเด็นค่ะ
โดยจาก Generation สุดท้ายที่มีการกล่าวถึงเรื่อง Data Governance =>> เพื่อนๆ สามารถอ่านบทความเพื่อมเติมได้จาก link ต่อไปนี้ค่ะ 🔍🧐



{kind=link}