แจกโค้ดทำ Data Visualizations โดย Python (ดีงามเหมือนใช้ PowerBI)

สวัสดีค่ะเพื่อนๆ 🤗😄 บทความนี้เป็นหนึ่งในบทความที่นิกอยากเขียนมากกกก ซึ่งได้แต่แพลน แต่ยังไม่มีโอกาสได้รวบรวมสักที ซึ่งเกิดจากการที่โดยส่วนตัวแล้วนิกไม่สันทัดในเรื่องการทำ Data Visualization ใน PowerBI ให้สวยงาม =>> ไม่มีศิลปะใดๆ ทั้งสิ้นนั่นเองค่ะ 55+
และนิกเชื่อว่า น่าจะมีหลายท่านที่ประสบปัญหาเช่นเดียวกัน ในบทความนี้จึงเป็นการนำแนะนำอีกหนึ่งแนวทางในการทำ Data Visualization ผ่านการ Coding บนโปรแกรมภาษา Python โดยใช้ Lib เทพๆ ที่มี provide ให้ ซึ่งสามารถพิมพ์ตามได้ง่ายๆ รันแล้วไม่(น่าจะ) error หรือมีปัญหาอะไร แม้ว่าจะเป็นมือใหม่ที่เริ่มการ Coding ก็ตามค่ะ ╰(*°▽°*)╯
ซึ่งสำหรับท่านใดที่มี IDE สำหรับรัน Python อยู่แล้ว เช่น Pycharm หรือ Jupyter notebook ก็สามารถใช้ตัวเดิมได้เลยนะคะ แต่สำหรับท่านใดที่ยังไม่มี นิกขออนุญาตแนะนำเป็น Google Colab ในการใช้ edit & run โค้ดของเรา โดยสามารถเข้าไปเปิด Notebook ใหม่บน Google Colab ได้ตาม link นี้ค่ะ (☞゚ヮ゚)☞
https://colab.google/
ซึ่งเมื่อเพื่อนๆ เข้ามาแล้ว ให้ทำการกดไปที่ New Notebook แล้วทำการพิมพ์โค้ด เพื่อทำ Data Visualization ตามนี้ได้เลยยย
1. Heatmaps
จาก Lib ชื่อคุ้นอย่าง seaborn
Heatmaps เป็นกราฟที่ใช้ lib seaborn ที่นิยมใช้เพื่อบ่งบอกความสัมพันธ์ หรือใช้วิเคราะห์ correlation ของข้อมูล โดยแสดงผลออกมาในรูปแบบของตารางสี และสามารถกำหนดให้กราฟ Heatmaps ที่ seaborn generate ให้แสดงค่าของความสัมพันธ์ระหว่างข้อมูลได้ โดยข้อดีของ Heatmaps คือการทำให้เราเห็นความสัมพันธ์ของข้อมูลที่มีความซับซ้อนได้ง่าย ด้วยรูปภาพ โดยเราสามารถพิมพ์โค้ดได้ง่ายๆ ดังนี้
import seaborn as sns
# Load data
data = pd.read_csv(‘data.csv’)
# Create heatmap
sns.heatmap(data.corr(), cmap=’coolwarm’, annot=True, fmt=”.1f”)
plt.show()
*บรรทัดแรกของโค้ดเป็นการ import Library คือ seaborn มาใช้เพื่อสร้าง Data Visualization โดยตั้งชื่อเล่นในการเรียกใช้ seaborn ใหม่เป็น sns =>
และในส่วนบรรทัด data = pd.read_csv(‘data.csv’) เป็นการโหลดชุดข้อมูลจากไฟล์ชื่อ data.csv มาเก็บไว้ในตัวแปรชื่อ data แล้วเราจึงนำตัวแปรนี้ไปใช้งานต่อค่ะ (*/ω\*)
ซึ่งในโค้ดต่อๆ ไปที่นิกจะพาเพื่อนๆ ไปดูกันต่อ ก็จะมีโครงสร้างประมาณนี้เหมือนกันค่ะ
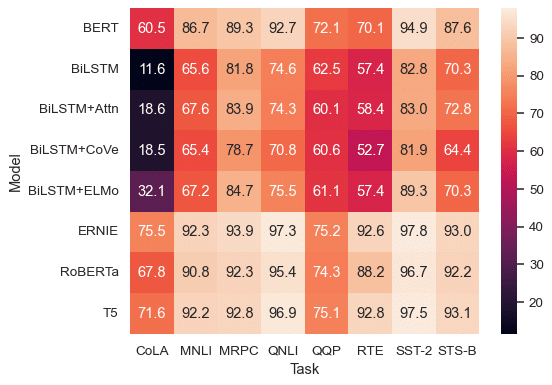
โดยจากกราฟ Heatmap ที่ได้ออกมา เราสามารถประยุกต์โค้ดเพื่อใช้งานเพิ่มเติมในการทำ Segmentation ของกลุ่มลูกค้าได้ง่ายๆ ด้วยการอาศัยความสามารถในการสร้าง Shade ของ Heatmap ตามกลุ่มที่แบ่งไว้จากการจัดเรียงข้อมูล ด้วยการเปลี่ยน โค้ดจาก cmap=’coolwarm’ เป็นการใส่รายละเอียด colormap เพิ่มตาม โค้ดนี้ค่ะ =>> cmap= ‘sns.diverging_palette(225, 0, n=6)’
ซึ่งหากเพื่อนๆ อยากได้โค้ดเพิ่มเติมในส่วนของ Heatmap นิกของแนะนำให้อ่านได้ที่ Link นี้ได้เลยค่ะ
2. Treemaps
Data visualization จาก Lib squarify
Treemaps จาก squarify เป็น data visualization ที่เหมาะกับการแสดงข้อมูลแบบลำดับชั้น ซึ่งสามารถแสดงข้อมูลได้อย่างชัดเจนและเข้าใจง่าย โดยใช้โค้ดดังนี้ (การ import data ใช้โค้ดเหมือนกับใน seaborn นะคะ)
import squarify
sizes = data[‘sales’]
labels = data[‘product’]
colors = sns.color_palette(‘Paired’, len(data))
plt.figure(figsize=(10, 8))
squarify.plot(sizes=sizes, label=labels, color=colors, alpha=0.8)
plt.axis(‘off’)
plt.show()
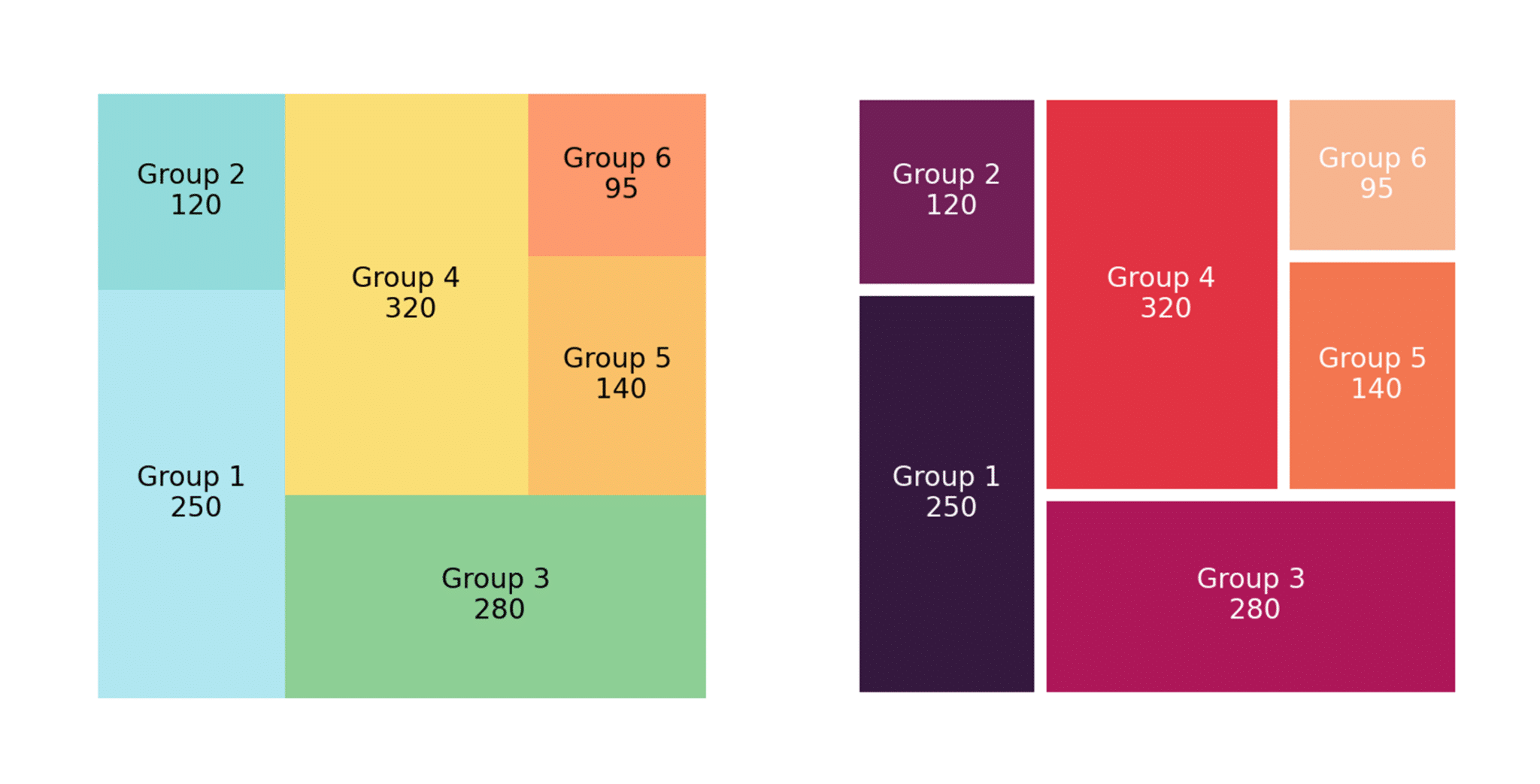
โดยจากภาพด้านบน Treemap ด้านซ้ายคือแบบดั้งเดิมที่ใช้เฉพาะ Lib squarify ค่ะ ซึ่งเพื่อนๆ สามารถแต่งสีใหม่ร่วมกับการใช้ seaborn ได้ โดยการเปลี่ยนโค้ดจาก color=colors เป็น color = sns.color_palette(“rocket”, len(values) ค่ะ
ซึ่งในส่วนของ Treemap ก็มีความเหมาะในการทำ data visualization ของการทำ Customer Segmentation เช่นเดียวกัน 🧐😉 ทั้งนี้หากเพื่อนๆ ต้องการศึกษาเพิ่มเติมเกี่ยวกับ Lib Squrify สามารถอ่านได้ตาม Link
3. Chord Diagrams
โดย Library ใช้งานง่าย plotly
Chord Diagrams เหมาะกับการแสดงความสัมพันธ์ของ connections และ flows ของข้อมูล หรือเป็นกราฟที่แสดงความสัมพันธ์แบบ inter relationship ที่มีการเปรียบเทียบความเหมือนและความต่าง ระหว่างข้อมูลแต่ละ Segment ที่ถูกจัดกลุ่มมาแล้ว ซึ่งมีโค้ดดังนี้ค่ะ
import plotly.graph_objects as go
# Create chord diagram
fig = go.Figure(data=[go.Chord(source=data[‘source’], target=data[‘target’], value=data[‘value’])])
fig.update_layout(title=’Entity Connections’, font_size=12, width=800, height=800, showlegend=False)
fig.show()
สำหรับข้อดีมากๆ ของ plotly คือ data visualization ที่ lib สร้างให้ สามารถทำเป็น interactive graph ได้ ทำให้มีความเป็น user friendly กับผู้ใช้งานมากยิ่งขึ้น
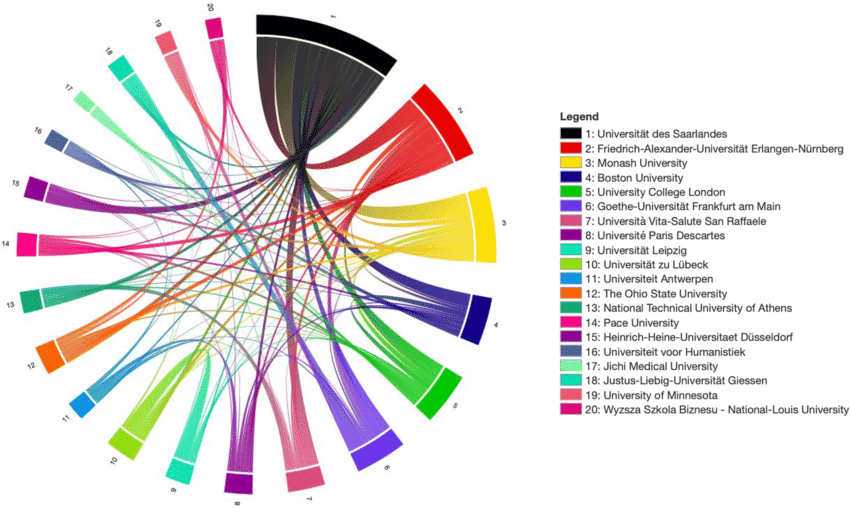
โดย Chord diagram จะแสดงความสัมพันธ์ของข้อมูลเป็นกราฟวงกลม ซึ่งมีความหนาของเส้นเชื่อม หรือ Arc แสดงถึง weight ของข้อมูลแต่ละ cluster ที่ถูกจำแนกโดยสีต่างๆ และมี Node ที่อยู่ที่กรอบของกราฟ แสดงกลุ่มแต่ละกลุ่มที่ถูกแบ่งออกมา
4. Scatter Plot
Data visualization แบบ 3 มิติ ของ Plotly
Scatter Plot (แผนภูมิการกระจาย) แบบนี้จะนิยมใช้เพื่อแสดงความสัมพันธ์ในเชิงตัวเลข จาก Features ของข้อมูล ในรูปแบบ 3 มิติ เพื่อให้เข้าใจ และเห็นภาพเชิงปริมาณของข้อมูลในแต่ละกลุ่มได้ชัดเจนมากยิ่งขึ้น โดยเพื่อนๆ สามารถใช้ Code ด้านล่างนี้ในการสร้าง Scatter graph ค่ะ
import plotly.graph_objects as go
# Create 3D scatter plot
fig = go.Figure(data=[go.Scatter3d(x=data[‘x’], y=data[‘y’], z=data[‘z’], mode=’markers’, marker=dict(size=6, color=data[‘color’], colorscale=’Viridis’, opacity=0.8))])
fig.update_layout(scene=dict(xaxis_title=’X’, yaxis_title=’Y’, zaxis_title=’Z’))
fig.show()
ซึ่งจากโค้ดจะต้องมีการ Provide data ให้ครบทั้ง 3 ตัวแปร ตามแกน X, Y และ Z โดยเราสามารถนำ Features ที่เราต้องการ Plot ดูความสัมพันธ์จากข้อมูลของเรามาป้อนใส่ในโค้ดได้เลยค่ะ
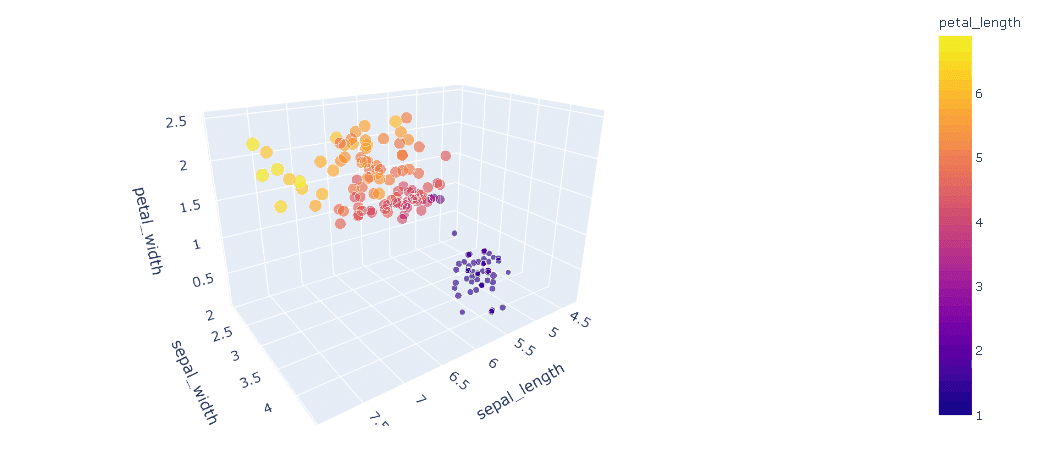
ซึ่งจากกราฟแบบ 3D Scatter จะเห็นว่ามีข้อดีเพิ่มเติมในการสามารถแยกกลุ่มของข้อมูลที่มีความคล้ายคลึงกันของ Data point ของแต่ละ Features ได้อย่างชัดเจน ผ่านการพิจารณาการกระจายตัวของจุดและสี ทำให้ Scatter plot เป็นอีกหนึ่งรูปแบบของการทำ visualization ที่ทำให้เราพิจารณา Cluster ได้ =>> และสำหรับเพื่อนๆ ที่ต้องการเรียนรู้กราฟประเภทนี้เพิ่มเติม สามารถเข้าไปดู tutorial ได้ที่ Link ได้เลยค่ะ ✨🔎
5. Network Graphs
กราฟความสัมพันธ์แบบเครือข่าย Data visualization ของ Lib networkx
กราฟความสัมพันธ์แบบเครือข่าย หรือ Network Graphs เป็นแนวทางที่เหมาะสำหรับการแสดงความสัมพันธ์ระหว่างข้อมูลแต่ละข้อมูล ในแง่ของความเกี่ยวเนื่องตามรูปแบบของเครือข่าย เพื่อให้สามารถวิเคราะห์ความสัมพันธ์ที่มีความซับซ้อนได้ดียิ่งขึ้น โดย Library ของไพธอนที่ใช้ในการสร้างกราฟเครือข่ายออกมาจะใช้เป็น networkx ตาม code ต่อไปนี้ค่ะ 🎑✨
import networkx as nx
# Create network graph
G = nx.from_pandas_edgelist(data, ‘source’, ‘target’)
plt.figure(figsize=(10, 8))
pos = nx.spring_layout(G, k=0.3)
nx.draw_networkx(G, pos=pos, with_labels=True, node_size=300, font_size=8)
plt.title(‘Entity Network Graph’)
plt.axis(‘off’)
ซึ่งข้อดีมากๆ ของการแสดงผลในรูปแบบนี้ คือทำให้เราสามารถระบุได้อย่างชัดเจนมากยิ่งขึ้นว่า ข้อมูลกลุ่มไหน มีความสัมพันธ์กับข้อมูลย่อยชุดใดบ้าง และเชื่อมโยงส่วนของความสัมพันธ์นั้นด้วยสิ่งใด =>> และนิกอยากแนะนำทุกท่านให้ลองอ่าน tutorial ของ lib networkx ตาม Link นี้กันค่ะ เพราะ Provider ของ lib ทำ tutorial ไว้ได้ดีมากๆ 😉😄
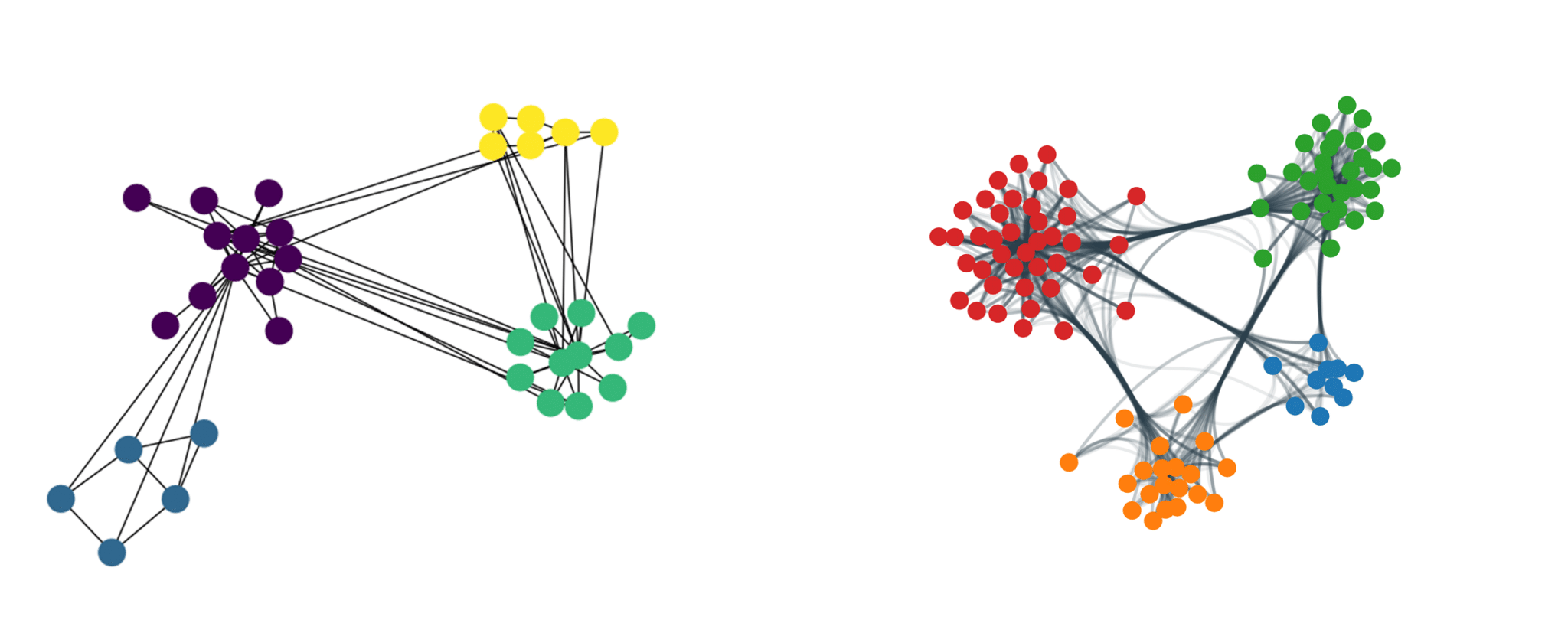
6. Parallel coordinates
กราฟแสดงความสัมพันธ์จาก Lib ดังอย่าง Pandas
จริงๆ แล้ว Data visualization แบบ Parallel coordinate เป็นสิ่งที่พวกเราน่าจะคุ้นเคยกันดีค่ะ (นิกเชื่อว่า ถ้าเพื่อนๆ เห็นรูปแล้วจะร้อง อ๋อออ อย่างแน่นอน^^) เทคนิคการแสดงผลของกราฟนี้ มักจะถูกใช้บ่อยๆ สำหรับการเปรียบเทียบค่าของข้อมูลจำนวนหลายๆ ชุด ในหมวดหมู่ หรือ Categories ที่แตกต่างกันออกไป ซึ่งสามารถสร้างกราฟนี้ได้ง่ายๆ ทั้งจาก Microsoft Excel และจาก PowerBI
โดย python lib ที่นิกจะแนะนำให้ทุกท่านลองใช้เพื่อสร้าง visualization แบบ Parallel coordinate คือ pandas ซึ่งใช้ Code ตามนี้ได้เลยค่ะ^^
import pandas as pd
import seaborn as sns
from pandas.plotting import parallel_coordinates
# Create parallel coordinates plot
plt.figure(figsize=(10, 8))
parallel_coordinates(data, ‘category’, color=sns.color_palette(‘Paired’, len(data)))
plt.title(‘Parallel Coordinates’)
การแสดงผลในรูปแบบนี้ ทำให้เราสามารถจำแนกกลุ่ม และพิจารณาค่าความแตกต่าง หรือแนวโน้มของความต่างเชิงคณิตศาสตร์ และจำนวนระหว่างข้อมูลแต่ละ Cluster หรือ Segment ได้อย่างชัดเจน ตามตัวอย่างกราฟด้านล่างค่ะ
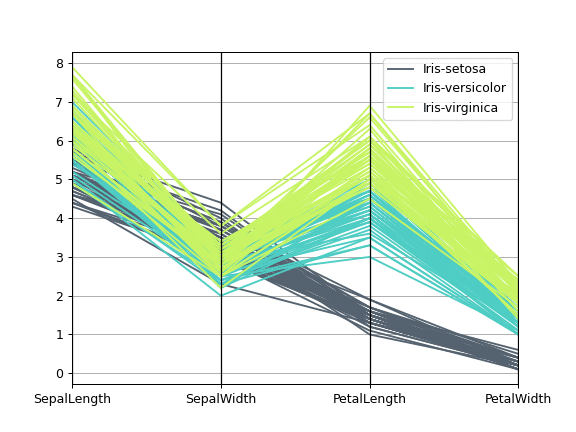
*จากโค้ด Parallel coordinates นิกมีการเรียกใช้งาน lib seaborn เพื่อใช้ชุดสีของ seaborn ในการให้สีของกราฟ parallel_coordinates จาก lib pandas นะคะ
7. Sunburst Chart:
Data visualization ทรงกลมคล้ายดวงอาทิตย์ 🌞🌝
กราฟแบบดวงอาทิตย์ หรือ Sunburst เป็นแผนภูมิที่ช่วยให้พวกเราสามารถเข้าใจความสัมพันธ์ตามลำดับชั้นของข้อมูลได้อย่างรวดเร็วมากยิ่งขึ้น โดยการแยกย่อยข้อมูลออกเป็น layer และแสดงสัดส่วนของค่าทางคณิตศาสตร์แนวเดียวกันกับการสร้างกราฟวงกลม
ซึ่งเราสามารถสร้างกราฟนี้ได้จากทั้งใน Microsoft Excel, PowerBI หรือใน Tableu ที่รองรับการแสดงผลแบบ Dynamic โดยในส่วนของ python เองก็มี Libraries หลากหลายที่สามารถช่วยให้เรา generate แผนภูมินี้จากข้อมูลของเราได้^^ แต่ในบทความนี้ นิกจะขอใช้ lib เจ้าประจำอย่าง plotly ในการสร้าง data visualization แบบ Sunburst ออกมา=>> follow โค้ดด้านล่างได้เลยค่ะ (☞゚ヮ゚)☞
import plotly.graph_objects as go
# Create sunburst chart
fig = go.Figure(go.Sunburst(labels=data[‘labels’], parents=data[‘parents’], values=data[‘values’]))
fig.update_layout(title=’Hierarchical Data Visualization’)
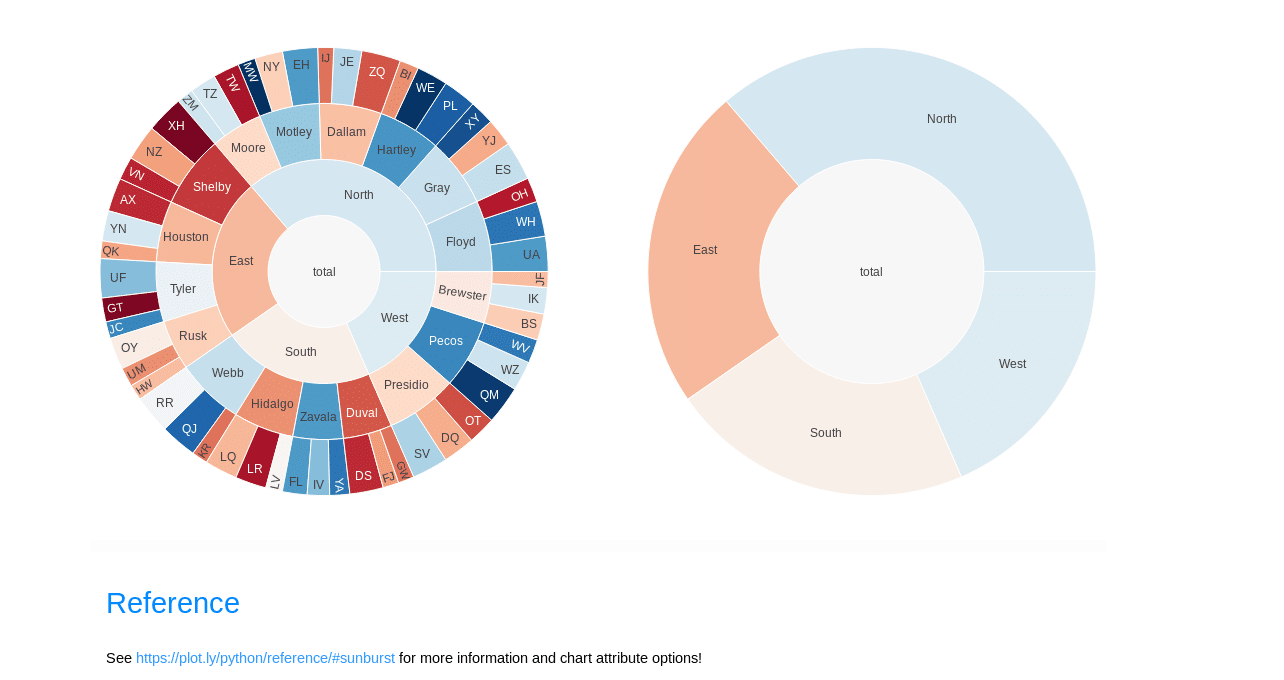
8. Animated Bar Charts
แผนภูมิแท่งแบบ Dynamic
เป็นการแสดงผลในรูปแบบของกราฟแท่งที่เป็นที่ถูกสร้างให้แสดงการเปลี่ยนแปลงเป็นแบบ Animation เพื่อให้เห็นถึงความเปลี่ยนแปลงของข้อมูล เช่น การเพิ่มขึ้นหรือลดลงของยอดขายสินถ้าแต่ละประเภท ในแต่ละปีเป็นต้น ซึ่งในส่วนของ Animated Bar Charts นิกขอใช้ lib เดิมที่เราคุ้นเคยอย่าง plotly ในการช่วย generate แผนภูมิออกมาตามโค้ดต่อไปนี้ค่ะ^^
import plotly.express as px
# Create animated bar chart
fig = px.bar(data, x=’category’, y=’value’, color=’category’, animation_frame=’year’, range_y=[0, 100])
fig.update_layout(title=’Category-wise Value Changes over Time’)
ซึ่งจากตัวอย่าง Bar Chart Race หรือ Animated Bar Chart ตามวิดีโอด้านบน (ซึ่ง advance ขึ้นจากโค้ดแบบ basic ในกล่องสีฟ้านะคะ) เพื่อนๆ สามารถลองเข้าไปทำตามได้จาก Link และ download ข้อมูลที่ใช้สร้างกราฟได้ที่ Data ค่ะ 📊 😊
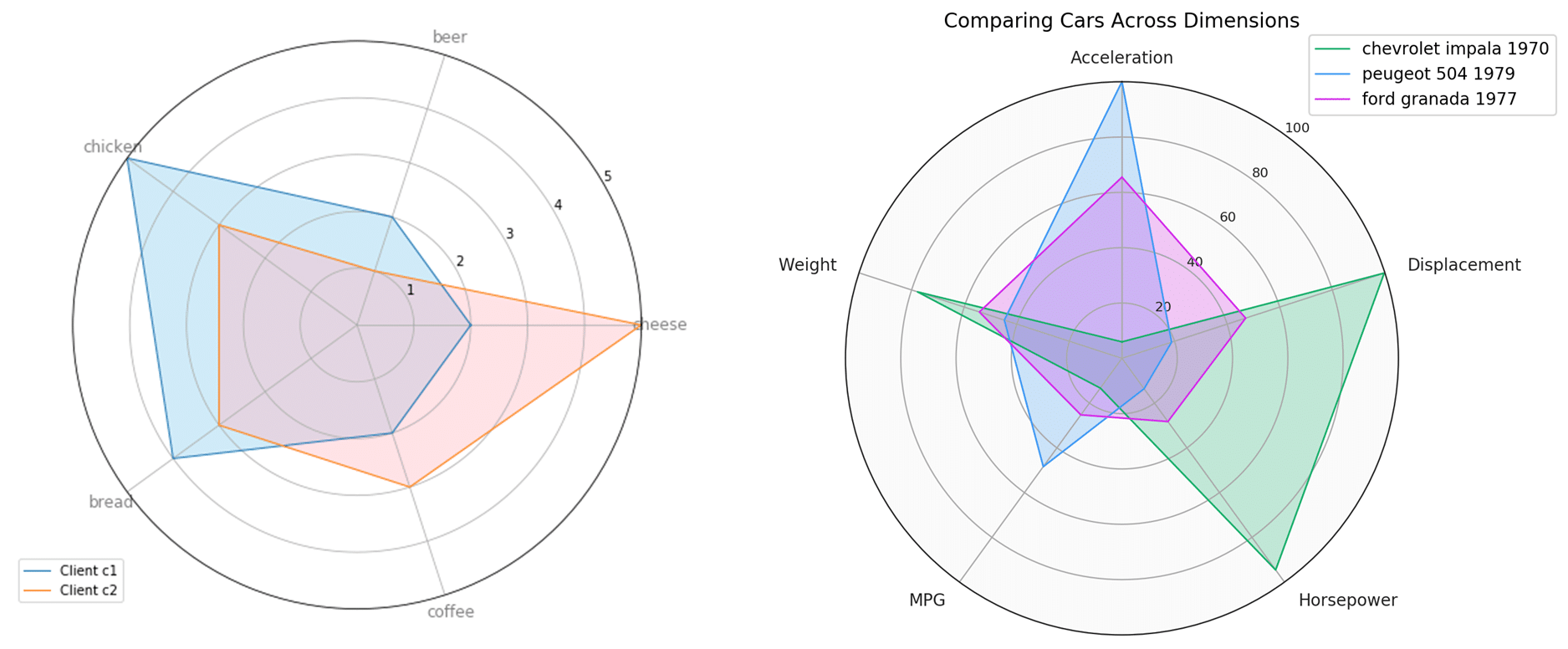
9. Radar Charts
แผนภูมิเรดาร์จากหลายตัวแปร 🕸🕷
แผนภูมิเรดาร์ (กราฟใยแมงมุม) หรือ Radar Charts น่าจะเป็นหนึ่งใน data visualization ที่เราค่อนข้างคุ้นเคยกันดี เพราะถือเป็นแผนภูมิที่มีประสิทธิภาพในการเปรียบเทียบข้อมูลหรือตัวแปรหลายตัวในประเภทที่แตกต่างกันออกไป =>> ถ้าเป็นสายเกม กราฟแบบนี้มักเอาไว้แสดงคุณสมบัติของตัวละครที่เราเล่นน้่นเองค่ะ^^ ซึ่ง Lib ที่นิกจะแนะนำในการทำ Radar Charts ในบทความนี้คือ Matplotlib (อาจมีความยุ่งยากในการ setting นิดหน่อยเมื่อเปรียบเทียบกับ plotly หรือ seaborn แต่ว่าอยากให้ลองกันนะคะ^^)
import numpy as np
import matplotlib.pyplot as plt
# Create radar chart
categories = data[‘category’]
values = data[[‘value1’, ‘value2’, ‘value3’, ‘value4’, ‘value5’]].values
angles = np.linspace(0, 2 * np.pi, len(categories), endpoint=False).tolist()
values = np.concatenate((values, values[:, 0:1]), axis=1)
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, polar=True)
for i in range(len(data)):
ax.plot(angles, values[i], marker=’o’, label=data.iloc[i][‘label’])
ax.fill(angles, values[i], alpha=0.25)
plt.thetagrids(np.degrees(angles), categories)
plt.title(‘Category Comparison’)
plt.legend()
โดยจากการที่กราฟใยแมงมุมมีการแสดงผลในลักษณะของการเปรียบเทียบของข้อมูลในแต่ละ Features (บางค่ายจะเรียกว่ามิตินะคะ) ทำให้เหมาะกับงานวิเคราะห์ด้านการตลาด เช่น การประเมินความพึงพอใจของลูกค้าในสินค้าและบริการด้านต่างๆ หรือการเปรียบเทียบคุณสมบัติแต่ละด้านของสินค้า เป็นต้น
10. Word Cloud Data Visualization
และแล้วก็มาถึง visualization แบบสุดท้ายจากการใช้โปรแกรมภาษา Python สำหรับบทความนี้ ซึ่งก็คือการสร้าง Word Cloud นั่นเองค่ะ^^
โดยอย่างที่เพื่อนๆ ทราบกันดีว่า Word cloud คือการจับเอาคำ หรือวลีสั้นๆ ในเนื้อหาบน website มาแยก แล้วจัดลำดับตามความถี่ (frequency) ของคำต่างๆ ซึ่งถือเป็นรูปแบบการแสดงผลของข้อมูลที่สามารถสื่อสารได้อย่างเข้าใจง่าย และมีประสิทธิภาพ ทำให้มีหลาย platform ที่ provide tools ในการสร้าง word cloud ให้เรา และในบทความนี้จะใช้ Library wordcloud บนภาษา Python ในการ generate Word Cloud ออกมาให้เราตาม Code ในกล่องสุดท้ายนี้ค่ะ (❁´◡`❁)
from wordcloud import WordCloud
# Prepare data
data = pd.read_csv(‘data.csv’)
# Generate word cloud
text = ‘ ‘.join(data[‘text’])
wordcloud = WordCloud(width=800, height=400).generate(text)
plt.imshow(wordcloud, interpolation=’bilinear’)
plt.axis(‘off’)
plt.title(‘Word Cloud’)
ซึ่งในส่วนของการใช้งาน lib Wordcloud หากเพื่อนๆ import WordCloud แล้วเจอ error ให้ทำการ !pip install wordcloud ก่อน และสามารถศึกษาการปรับแต่ง Visualization ของ word cloud ได้จาก Link (ในบทความนี้เป็นโค้ดการสร้าง word cloud อย่างง่ายค่ะ)


Last but not Least…
สำหรับบทความนี้ นิกหวังเป็นอย่างยิ่งค่ะ ว่าเพื่อนๆ นักการตลาด และผู้ที่สนในทุกท่านจะได้ประโยชน์ จากการลองทำ Data Visualization โดยโปรแกรมภาษา Python ซึ่งนิกพบว่า Marketer หลายนอกจากจะมีองค์ความรู้ด้านการตลาดที่ดีมากๆ อยู่แล้ว ยังสามารถเขียนโปรแกรมเพื่อวิเคราะห์ข้อมูลได้อีกด้วย!!!!
เนื้อหานี้จึงถูกรวบรวมขึ้นมาเพื่อแลกเปลี่ยนองค์ความรู้ ในการใช้งาน Tools ที่แตกต่างกันออกไปค่ะ และนำเสนอรูปแบบของทั้ง Charts และ Graph ที่น่าสนใจ มีประสิทธิภาพ และง่ายต่อการนำไปวิเคราะห์ต่อค่ะ 😊📈
ปูลู: สุดท้าย ท่านใดที่รันแล้วติด error หรืออยากแนะนำแนวทางอื่นๆ สามารถทัก FB นิกตามนี้ =>> https://www.facebook.com/panaya.sudta/ ได้เลยนะคะ^^




){kind=link}