Facebook Algorithm: เข้าใจที่มาแบบละเอียด และ How to win?

printf(“Hello World!”) สวัสดีค่ะทุกท่าน ขอกล่าวคำทักทายแบบวิชาภาษา C#101 เพราะในบทความนี้นิกจะพาทุกท่านไปเข้าใจถึงสิ่งที่ถือได้ว่าเป็นหนึ่งใน Hot issue สำหรับงานการตลาดบน Social Media ในยุคแห่ง Digital Marketing นั่นก็คือที่มา และหลักการของการสร้าง Facebook Algorithm ตลอดจนการเอาชนะ Alogorithm นั้น เพื่อให้เราสามารถทำการตลาดบน Facebook ที่มีผู้ใช้งานถึง 3.03 พันล้านคนได้อย่างมีประสิทธิภาพ ตามที่เราต้องการค่ะ
โดยในบทความนี้จะเริ่มจากการกล่าวถึงหลักการคำนวณทางคณิตศาสตร์ที่อยู่เบื้องหลังการทำ “Personalized Ranking” และการคำนวณด้าน Optimization อื่นๆ ซึ่งไม่อยากอย่างที่คิดแน่นอนค่ะ,,,, และรับรองได้ว่า ถ้าหากมีความเข้าใจในส่วนนี้แล้ว จะสามารถประยุกต์ใช้ได้ยาวๆ เลย
หลังจากนั้นเราจะมาเจาะลึกถึง 4 ปัจจัยหลักที่ Facebook ทำการเลือกแสดง New feed และ Reels ตามค่าที่ได้จากการคำนวณจาก Algorithm ได้แก่ Inventory, Signals, Predictions และ Relevance และท้ายสุดนิกจะพาทุกท่านไปดูตัวอย่างการนำองค์ความรู้ทั้งหมดนี้ไปใช้งานจริงให้ได้ผลสัมฤทธิ์ทางการตลาดตามเป้าหมายที่เราตั้งค่าเอาไว้,,,, Let’s go (o゜▽゜)o☆

เข้าใจหลักการคำนวณเบื้องหลัง Facebook Algorithm
#1 หลักการ Personalized Ranking
หลักการจัดอันดับของ Contents หรือเนื้อหาบนแพลตฟอร์มของ Facebook Algorithm จะประกอบด้วยชุดของ “กฎ” หรือ “Rules” ที่ได้รับการคำนวณโดย AI และคำนวณตามหลักการทางสถิติมาก่อนหน้า โดยจะทำการประเมินในทุกโพสต์, Ads, Story และ Reel เพื่อใช้เป็นเกณฑ์ในการพิจารณาว่า User ควรจะเห็นอะไร และเรียงลำดับการเห็นอย่างไรในแต่ละบุคคล ซึ่งการจัดอันดับแบบนี้จะถูกเรียกว่า การจัดอันดับแบบ “Personalized Ranking” ค่ะ
โดยการทำ Personalized Ranking จะเกิดขึ้นทุกครั้งที่ผู้ใช้งานทำการรีเฟรชฟีดของตัวเอง ซึ่งใช้สมการที่ประกอบไปด้วยฟังก์ชั่นย่อยจำนวน 3 ฟังก์ชั่นดังนี้ค่ะ
R(u,c) = α*I(u,c) + β*P(u,t) + γ*E(c)
โดยที่ R(u,c) ที่เป็นผลลัพธ์ที่ได้จากการคำนวณคือ คะแนนความเกี่ยวข้อง (relevance score) ของผู้ใช้งาน “u” กับเนื้อหา “c” ซึ่งประกอบไปด้วยความสัมพันธ์ของฟังก์ชั่น I, P และ E ผ่านการปรับคูณค่าน้ำหนัก (weight) สำหรับแต่ละฟังก์ชั่นซึ่งคือค่าของตัวแปร α, β และ γ ตามที่ปรากฎในสมการ โดยฟังก์ชั่นแต่ละฟังก์ชั่นมีรายละเอียดดังต่อไปนี้ค่ะ
- I(u,c) หรือ Interaction: คือฟังก์ชั่นที่แสดงความสัมพันธ์ระหว่างผู้ใช้งาน “u” และเนื้อหา “c” เช่น เนื้อหานั้นมาจากเพื่อน, เพจที่กดไลค์ไว้ หรือกลุ่ม โดย I(u,c) จะแคปเจอร์ความแข็งแรง หรือความใกล้ชิดของความสัมพันธ์ ในรูปแบบของกราฟและค่าน้ำหนัก =>> เพื่อนๆ สามารถอ่านต่อในเรื่องของ Graph Theory นะคะ
- P(u,c) หรือ Preference: คือฟังก์ชั่นที่ใช้คำนวณค่าความสัมพันธ์ระหว่างผู้ใช้งาน “u” กับประเภทของคอนเทนต์ “t” ซึ่งฟังก์ชั่นนี้จะขึ้นอยู่กับสองสิ่งคือ ความสนใจที่ผู้ใช้งานตั้งค่าไว้ตั้งแต่แรก และค่าจากการอัปเดตข้อมูลจากการโต้ตอบกับคอนเทนต์ประเภทนั้นๆ ซึ่งค่าหลังนี้จะมีการเปลี่ยนแปลงตลอดเวลาโดยคำนวณจาก AI ขึ้นกับลักษณะการใช้งาน และโต้ตอบบน Facebook แพลตฟอร์มในช่วงนั้นของ User ค่ะ
- E(c) หรือ Engagement: หมายถึงคะแนนโดยรวมของคอนเทนต์ “c” ซึ่งคำนวณมาจากการใช้ Engagement metrics ประกอบด้วย การกดไลค์, การคอมเมนต์ และการแชร์ โดยที่ค่าน้ำหนักของตัวคูณ (γ ) ในแต่คอนเทนต์ได้มาจากค่าความสัมพันธ์ระหว่าง user กับคอนเทนต์นั้นๆ
โดยที่ค่าน้ำหนัก α, β และ γ ที่คูณอยู่ที่ด้านหน้าของฟังก์ชั่น I, P และ E ได้มาจาก AI ของ Facebook Algorithm ซึ่งจากการพิจารณาสมการเราสามารถสรุปได้ว่าเป้าหมายหลักของ FB Algorithm คือการแสดงเนื้อหาที่ User (อาจจะ)พบว่าน่าสนใจเป็นการส่วนตัวมากที่สุดเรียงตามลำดับคะแนนนั่นเองค่ะ
*หมายเหตุ: อธิบายเพิ่มเติมในเรื่อง Maths ค่ะ =>> ฟังก์ชันคือสมการ หรือความสัมพันธ์ทางคณิตศาสตร์ระหว่างตัวแปรที่เราสนใจ เช่นในสมการด้านบน I(u,c) เป็นค่าความสัมพันธ์ระหว่าง User และ Content ที่ถูกนิยามด้วยคำว่า Interaction (I) ค่ะ
#2 หลักการ Inventory และ Components Predictions
จากหลักการของ Personalized Ranking ที่เป็นหลักการหลักแล้ว สำหรับทั้ง Feed และ Reels ในปี 2023 มีองค์ประกอบในสมการเพิ่มขึ้นมาอีกค่ะ นั่นคือค่าที่ได้จาก AI ที่ทำ Prediction ออกมาได้แก่ค่า Inventory และค่า Components ทำให้สมการ Feed&Reels Algorithm ของ Facebook มีการเปลี่ยนแปลงนิดหน่อย (แต่หลักๆ ก็ยังคงคอนเซ็ปต์ พื้นฐานเหมือนเดิม คือการนำเสนอเนื้อหาจาก User, แบรนด์ และกลุ่มที่เชื่อมต่อเป็นหลัก โดยหน้าตาของสมการมีดังนี้ค่ะ ψ(`∇´)ψ
R_feed(u, c) = α * I(u, c) + β * P(u, t) + γ * E(c) + δ * I_feed + ε * P_feed
ดูยุบยับ น่ากลัวขึ้นไหมคะ 🤣😁 แต่จริงๆ แล้ว ถ้าเราสังเกตุดีๆ จะเห็นว่ามีพารามิเตอร์ที่เพิ่มมาเพียงแค่ 2 พารามิเตอร์เท่านั้นเอง นั่นก็คือ I_feed และ P_feed ที่คูณอยู่กับค่าน้ำหนัก δ และ ε ตามลำดับ
ซึ่งจากสมการที่เปลี่ยนไปนี้ เรามาดูรายละเอียดในแต่ละพารามิเตอร์ที่เพิ่มเข้ามาโดยสรุปเพื่อความเข้าใจง่ายดังนี้ค่ะ 🚀✔
- I_feed (หรือ I_reels) คือ องค์ประกอบย่อยของ Inventory หรือคอนเทนต์ทั้งหมดที่มีโอกาสที่จะแสดงบน Feed และ Reels
- P_feed (หรือ P_reels) คือ องค์ประกอบของความสอดคล้องกันของคอนเทนต์ที่ผู้ใช้งานน่าจะชอบโดยการ Predict ออกมา ซึ่งในส่วนนี้เองที่จะใช้ AI คำนวณผลลัพธ์เป็นค่าคะแนน (โดย Logisitc regression ร่วมกับ Nueral networks)
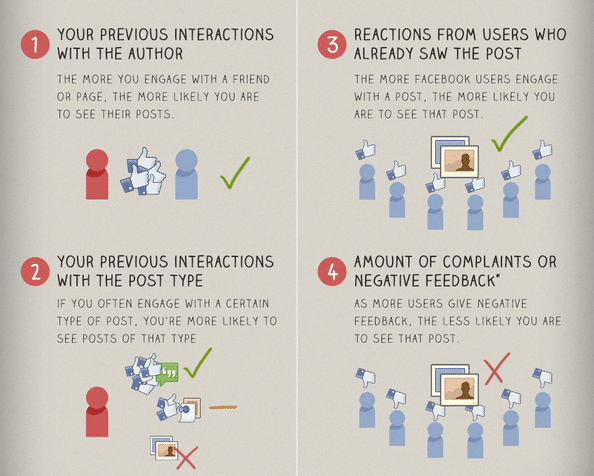
ปัจจัยที่ต้องพิจารณาสำหรับสร้างคอนเทนต์อิงตาม Facebook Algorithm
หลังจากที่เราทำความเข้าใจโครงสร้างของสมการในการให้คะแนนคอนเทนต์ของ Facebook Algorithm เรามาย่อยเนื้อหาและรายละเอียดในส่วนของสมการเพื่อให้เข้าใจง่ายยิ่งขึ้น โดยแบ่งเป็น 4 ปัจจัยที่ Facebook พิจารณา และเราจะต้องสนในดังนี้ค่ะ
- Inventory: หมายถึง เนื้อหาหรือคอนเทนต์ทั้งหมดที่มีโอกาสแสดงบนหน้าฟีดของ User โดยหมายรวมไปถึงพื้นที่โฆษณา
- Signals: หมายถึง สัญญาณ ซึ่งในที่นี้คือข้อมูลแฝงที่เกี่ยวข้องกับตัวคอนเทนต์ทั้งหมด ได้แก่ ยอดไลค์, การคอมเมนต์, แชร์ หรือแม้แต่ช่วงเวลาที่โพสต์ ตลอดจน Signals เชิงลึกอื่นๆ ที่แสดงความเชื่อมโยงระหว่างตัวคอนเทนต์และ User ที่แสดงค่าออกมาเป็น Ranking
- Predictions: พิจารณาเป็น Custom Prediction ตาม Ranking Factor ต่างๆ จาก AI Algorithm (ปัจจัยนี้มาจาก P_feed หรือ P_reels ตามสมการค่ะ) ที่จะให้คะแนนความสัมพันธ์หรือค่าความเกี่ยวข้องของคอนเทนต์ที่ User น่าจะสนใจหรือมี Interaction ในทางบวกด้วย
- Relevances: จากค่า Predictions ก่อนหน้า เนื้อหาใน Facebook จะเรียงลำดับตามค่าคะแนนความเกี่ยวข้องจากผลรวมถ่วงน้ำหนักของ User และคอนเทนต์ โดยที่โพสต์ที่ได้คะแนนส่วนนี้สูงกว่าจะอยู่ด้านบน (หรือพูดง่ายๆ ว่า ค่าคะแนน Relevances จะพิจารณาจากปัจจัย 3 ส่วนก่อนหน้าคือ Inventory, Signals และ Predictions ค่ะ)
มาเอาชนะ Facebook Algorithm ในทุกตัวแปรของสมการกัน^^
จากปัจจัยทั้ง 4 ที่สรุปออกมาเป็นปัจจัยหลัก (เพื่อให้ทุกท่านเข้าใจง่าย) ในการพิจารณาสร้างคอนเทนต์สำหรับทั้ง Feed และ Reels แล้ว ในพาร์ทนี้เรามาลงรายละเอียดในเชิงลึกสำหรับพารามิเตอร์ (หรือนิพจน์) แต่ละตัวในสมการกันเลยค่ะ ว่าถ้าเราต้องการให้คอนเทนต์ของเรามีการเข้าถึงเยอะ และขึ้น New Feed ของผู้ใช้งาน Facebook ในวงกว้างแล้ว เราควรทำอย่างไร,,,, Here we go,,,, 🤗🎑
1. Interaction (I):
เราต้องทำการปรับปรุงการโต้ตอบ (Interaction) ระหว่างผู้ใช้งานกับคอนเทนต์ของเรา ด้วยการโพสต์เนื้อหาที่มีความเกี่ยวข้อง ให้องค์ความรู้ เชื่อมโยงกับเทรนด์ในปัจจุบัน(สามารถใช้ #hashtag ที่เกี่ยวข้อง) และมีคุณค่า(อย่างสม่ำเสมอ) โดยสิ่งสำคัญคือเพื่อการกระตุ้นให้เกิดการสนทนาโต้ตอบภายในโพสต์ ซึ่งจะเป็นการเพิ่มส่วนของฟังก์ชัน I(u,c) ในสมการ ที่เป็นส่วนของคะแนนความเกี่ยวเนื่อง และสิ่งนี้จะสามารถช่วยเพิ่มโอกาสของโพสต์เราที่จะขึ้น New Feed ในวงกว้างได้ตาม Facebook Algorithm ได้
2. Preferences (P):
ในส่วนนี้ให้เราพิจารณากลุ่มเป้าหมายของเรา ว่าเป็นกลุ่มที่ให้ความสนใจในเรื่องใด โดยตรวจสอบประเภทของคอนเทนต์ที่ User สนใจและมี Engage มาก และพิจารณาโพสต์คอนเทนต์นั้น เพื่อเป็นการเพิ่มค่าของฟังก์ชั่น P(u,t) ที่ช่วยเพิ่มโอกาสให้คอนเทนต์ของเราเข้าสู่กลุ่มเป้าหมายได้อย่างถูกกลุ่ม
3. Engagement (E):
เพิ่มค่าการมีส่วนร่วมกับเนื้อหา ด้วยการสร้างคอนเทนต์ที่ส่งเสริมการมีส่วนร่วม เช่น แบบสำรวจ แบบทดสอบ หรือคำถามกระตุ้นตามเทรนด์ต่างๆ ซึ่งส่วนนี้เองเป็นส่วนที่สำคัญมากๆ ในการเพิ่มค่าของนิพจน์ E(c) ในสมการ ซึ่งทำให้คะแนนความเกี่ยวข้องกับกลุ่มผู้ใช้งานของเราสูงขึ้น และส่งผลให้ค่าการมองเห็นใน New Feed ของเราดีขึ้นโดยรวมค่ะ
4. Inventory และ Prediction (I_feed, P_feed):
ค่าโอกาสการเห็นของคอนเทนต์องค์รวมของเราทั้งหมด และค่าคาดการณ์ว่าคอนเทนต์ของเราจะถูกชอบ สามารถเพิ่มขึ้นได้ด้วยการมีปฏิสัมพันธ์ที่ใกล้ชิดกับผู้คนที่มา Engage ในคอนเทนต์ของเราค่ะ โดยเมื่อเราสร้างเนื้อหาที่มีคุณภาพ และเป็นที่ชื่นชอบ ตลอดจนมี Interaction ที่สูงแล้ว การที่เราเข้าไปโต้ตอบในคอนเทนต์ เป็นส่วนสำคัญในการเพิ่มค่า Positive Prediction หรือคือความชื่นชอบและความเกี่ยวเนื่องในเชิงบวกของคอนเทนต์ในคลังโดยรวมของเราได้ค่ะ
5. ค่าน้ำหนัก (α, β, γ, δ, ε):
เนื่องจาก Facebook Algorithm ในปัจจุบันที่ถูกพัฒนาจนถึงยุคของการใช้งาน AI ในการคำนวณความสัมพันธ์แล้ว ในส่วนค่าน้ำหนักของแต่ละนิพจน์จึงถูกคำนวณและถูกปรับเปลี่ยนให้เหมาะสมกับผู้ใช้งานตามหลักการของกฎ “Personalized Ranking” ในการเพิ่มค่าน้ำหนักของตัวคูณ α, β, γ, δ, ε จึงทำได้โดยการติดตามการเปลี่ยนแปลงของ Algorithm อย่างต่อเนื่องร่วมกับการพิจารณา Facebook Insights เพื่อดูว่ามีการเปลี่ยนแปลงของพารามิเตอร์ และ “Rules” ต่างๆ อย่างไรบ้าง และปรับลักษณะของคอนเทนต์/เนื้อหาให้เหมาะสม
สรุป
จากบทความนี้เพื่อนๆ จะเห็นค่ะว่า Facebook Algorithm มีที่มาที่ไปอย่างชัดเจนในเรื่องของการให้ค่าคะแนนตามกฎของทาง Facebook ซึ่งมีการปรับปรุงให้เหมาะสมกับปัจจุบันอย่างสม่ำเสมอ ดังนั้นนิกขอปิดท้ายบทความนี้ด้วยภาพของ Timeline พัฒนาการเปลี่ยนแปลง Aligorithm ของ Facebook จากปี 2018 – 2022 ตามภาพด้านล่างนี้ค่ะ 🤗✨ (ส่วน 2023 – ปัจจุบัน ใช้หลักการตามบทความนี้)




{kind=link}