The Art of Statistics Learning from Data หนังสือแนะนำสำหรับคนที่สนใจเรื่องดาต้า

สรุปหนังสือ The Art of Statistics – Learning from data หนังสือแนะนำสำหรับคนที่สนใจเรื่อง Data ไม่ว่าจะ Data Science, Data Analytics หรือ Data Visaulization หนังสือเล่มที่จะพาคุณไปเปิดมุมมองให้เห็นการใช้หลักสถิติในรูปแบบต่างๆ ที่ช่วยทำให้ข้อมูลที่มีคลี่คลาย Insight สำคัญออกมา
หนังสือเล่มนี้ทำให้เข้าใจว่าแท้จริงแล้ว Data กับ Statistics คือเรื่องเดียวกันอย่างไม่น่าเชื่อ แต่คนที่สนใจเรื่องดาต้าอาจไม่ต้องรู้วิธีการของสถิติเชิงลึกมาก แต่ต้องเข้าใจว่าหลักการคิดและทำงานของแต่ละวิธีการนั้นจะทำให้ได้ผลลัพธ์แบบไหน
เช่น ค่าเฉลี่ยที่เราชอบพูดกันติดปากเวลาจะวิเคราะห์ข้อมูลสักอย่าง แท้จริงแล้วมีค่าเฉลี่ยกี่รูปแบบกันบ้างหละในทางสถิต Mean Median หรือ Mode เพราะแต่ละวิธีการก็ทำให้ได้ผลลัพธ์ที่ต่างกันมหาศาลได้
- Mean คือค่าเฉลี่ยแบบ Average ที่เอาทุกค่ามาบวกกันแล้วหารเฉลี่ยถัวกันไปอย่างที่เราคุ้นเคย
- Median คือค่ากลาง ที่อยู่ตำแหน่งตรงกลางของค่าทั้งหมด
- Mode ค่าที่มีซ้ำมากที่สุด
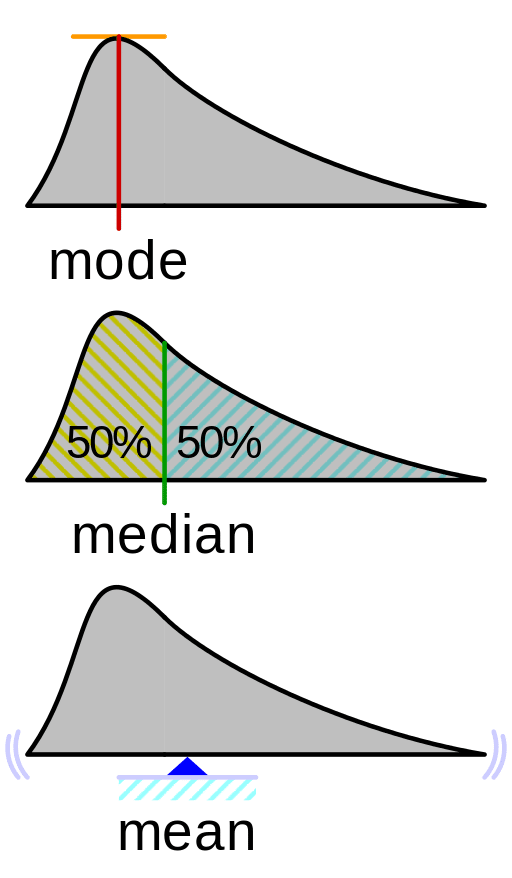
ดูจากภาพด้านบนน่าจะอธิบายได้ชัดเจนนะครับว่าค่าเฉลี่ยแบบต่างๆ นั้นแตกต่างกันอย่างไร และภาพด้านล่างก็เป็นอีกภาพหนึ่งที่ผมชอบมากจากหนังสือเล่มนี้ เป็นภาพที่ทำให้ผมเห็นว่าการทำ Visualization หลายๆ แบบพร้อมกันนั้นทำให้เราสามารถเข้าถึง Insight สำคัญได้ง่ายขึ้น

ภาพนี้ทำให้ผมเห็นมิติการใช้ scatter plot ผสมกับ Data Visualization รูปแบบอื่นที่ทำให้เห็นชัดว่าปีไหนสำคัญ และช่วงอายุเฉลี่ยเท่าไหร่ที่เราควรสนใจ ซึ่งการจะวิเคราะห์ข้อมูลให้ได้ซึ่ง Insight จำเป็นต้องใช้การบิดดาต้าอย่างคล่องแคล่วชำนาญหลากหลายรูปแบบครับ
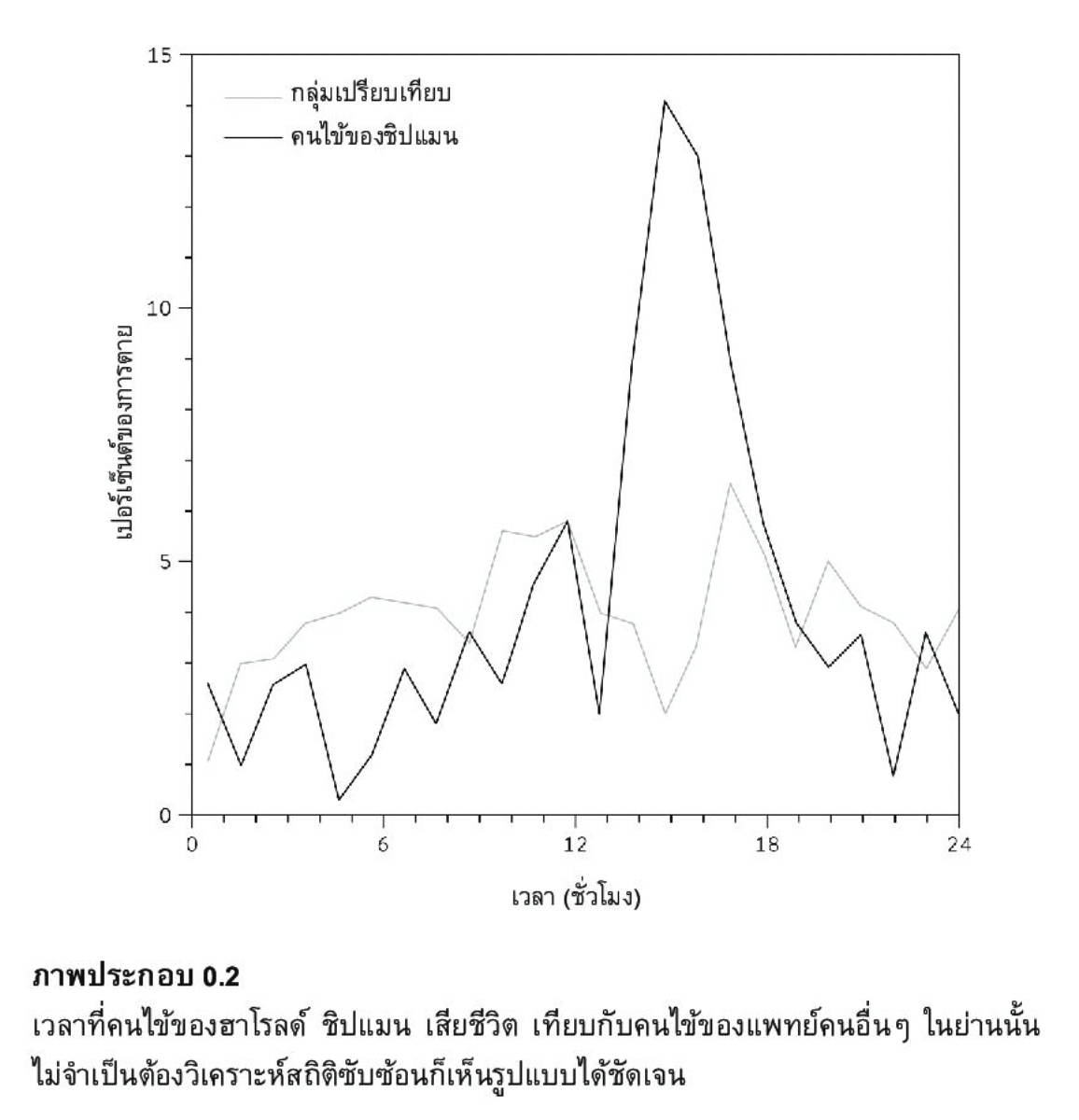
จากภาพด้านบนก็เหมือนกันที่เมื่อเอาข้อมูลบันทึกการตายของคนไข้ของแพทย์รายหนึ่งมาวิเคราะห์ผ่านการทำ Data Visualization ก็จะเห็นว่า แพทย์คนอื่นมาการระบุเวลาการตายของคนไข้ที่กระจายตัวอย่างเห็นได้ชัด แต่ของแพทย์คนนี้นั้นกลับมีการกระจุกตัวอย่างผิดปกติชัดเจนว่าเหตุใดคนไข้ของแพทย์รายนี้จึงมักเสียชีวิตช่วงบ่ายเป็นพิเศษ
จะเห็นได้ว่าประเด็นสำคัญของการวิเคราะห์ข้อมูลคือการมองหาความผิดปกติที่ซ่อนอยู่ในข้อมูลให้เจอ ซึ่งความปกตินั้นจะนำไปสู่คำถามใหม่ที่น่าสนใจขึ้น และคำถามนั้นก็จะพาเราเข้าใกล้คำตอบหรือ Insight ที่แท้จริงมากขึ้น นี่แหละครับความสนุกของการเล่นกับดาต้า
PPDAC นักวิเคราะห์สายดาต้า

ถ้าอยากจะเป็นนักวิเคราะห์หรือนักสืบสายดาต้า หนังสือเล่มนี้มี Framework ที่ชื่อว่า PPDAC ที่คุณสามารถเอาไปประยุกต์ใช้ได้
- Problem เริ่มต้นจากปัญหา เข้าใจปัญหาก่อนว่าตกลงแล้วปัญหาเราคืออะไร แล้วปัญหานี้เราต้องหาคำตอบหรือดาต้าแบบไหน
- Plan พอรู้แล้วว่าจะต้องใช้ดาต้าแบบไหนมาตอบคำถาม ก็ต้องเริ่มวางแผนว่าเราจะวัดผลหรือเก็บข้อมูลที่เราอยากรู้ได้อย่างไร
- Data ไม่ใช่แค่เก็บ แต่ต้องคลีน และบริหารจัดการดาต้าทั้งหมดที่ต้องการให้พร้อมนำไปใช้งานต่อในขั้นถัดไป
- Analysis การวิเคราะห์ข้อมูล มีตั้งแต่ทำข้อมูลให้เรียบร้อย จัดเรียงข้อมูลให้พร้อม มองหารูปแบบหรือ Pattern ที่ซ่อนอยู่ หรือมองหา Signal ความผิดปกติก็ได้ แล้วก็ตั้งสมมติฐานขึ้นมาว่าทำไมมันถึงเป็นแบบนี้ อะไรทำให้มันแสดงผลแบบนั้น
- Conclusion สรุป จากทั้งหมดที่เห็นเราได้ข้อสรุปแบบไหน ตีความออกมาอย่างไร มีไอเดียอย่างไรเมื่อผ่านการวิเคราะห์ถึงสาเหตุเบื้องหลัง แล้วก็เตรียมนำเสนอไปยังคนที่เกี่ยวข้องให้เข้าใจได้ง่ายด้วย
Data Cleansing ขั้นตอนสำคัญของการทำ Data-Driven
หนังสือเล่มนี้ช่วยย้ำเรื่องของ Data Cleansing ได้ดี ซึ่งเป็นสิ่งสำคัญมากในการทำงานกับดาต้า เพราะการ Cleasing data ไม่ได้มีแค่การล้างข้อมูลที่ไม่เกี่ยวออก แต่มันนิยามไปถึงการเตรียมข้อมูลให้ดีก่อนเริ่มนำไปวิเคราะห์ ตั้งแต่หาข้อมูลที่ไม่สมบูรณ์แล้วคัดออก ตัดข้อมูลที่ไม่เกี่ยวข้องออก เอาข้อมูลที่ซ้ำซ้อนออก หรือทำการแก้ไขปรับเปลี่ยนข้อมูลให้ถูกต้องเพื่อที่จะได้พร้อมนำไปใช้งาน
ตัวอย่างที่ผมเจอบ่อยมากเวลาทำ Analytics คือ จังหวัด ข้อมูลประเภทจังหวัดนี้มีความหลากหลายน่าปวดหัว ยกตัวอย่างง่ายๆ จังหวัดกรุงเทพมหานครนั้นเวลาคนกรอกข้อมูลมักจะได้มาหลากหลายรูปแบบ ตั้งแต่
- กทม
- กทม.
- กรุงเทพ
- กรุงเทพฯ
- กรุงเทพมหานคร
- จ.กทม
- จ.กรุงเทพ
- Bangkok
- BKK
เป็นอย่างไรครับกับข้อมูลที่หมายถึงจังหวัดกรุงเทพมหานครที่มีหลากหลายรูปแบบ สิ่งที่ผมต้องทำคือปรับทั้งหมดให้อยู่ในรูปแบบเดียวกันเพื่อให้ระบบมันนำไปวิเคราะห์ต่อได้อย่างถูกต้องไม่ผิดพลาด ดังนั้นขั้นตอนการทำ Data Cleansing จึงเป็นหนึ่งในขั้นตอนที่ใช้เวลามากที่สุด เหมือนกับการเตรียมวัดถุดิบให้พร้อมกันนำไปปรุงอาหาร ถ้าเราเตรียมไม่ดีปรุงดีแค่ไหนก็รสชาติเพี้ยนจนพังได้
Statistics ถูกยกระดับไปอีกขั้นเพราะ Data
วิชาสถิติ หรือสถิติศาสตร์นั้นมีมายาวนาน แต่ก่อนอาจไม่ค่อยได้รับความสนใจมากเพราะปริมาณข้อมูลที่มีให้นักสถิตินำไปวิเคราะห์อาจจะมีน้อยและจำกัด แต่วันนี้เราอยู่ในยุคของ Big Data เต็มตัว หรืออยู่ในยุคของ Data-Driven แบบเต็มปาก ดังนั้นทักษะเรื่องสถิติจึงสำคัญมาก ยิ่งมีความเข้าใจเรื่องนี้ดีเท่าไหร่ ก็จะยิ่งสามารถยกระดับธุรกิจหรือเข้าถึง Insight ดีๆ ได้ยิ่งขึ้นเท่านั้น
ดังนั้นผมอยากบอกว่าเพื่อนๆ นักการตลาดและคนทำธุรกิจต้องมีความเข้าใจโมเดลทางสถิติไว้ไม่มากก็น้อยนะครับ เพราะแม้เราอาจจะทำเองไม่เป็น วิชาเลขง่อยมาก(แบบผม) แต่อย่างน้อยถ้าเรารู้และเข้าใจคอนเซปไว้ การจะทำงานกับทีมดาต้าก็จะเป็นเรื่องง่าย เพราะเราจะได้เข้าใจว่าเขาทำอะไรมา และเราอาจจะเสนอไอเดียว่าลองบิดดาต้าอีกอีกแง่มุมแล้วหรือยัง
แล้วนั่นก็ทำให้การเรียนการสอนวิชาสถิติศาสตร์ในยุค Data กำลังเปลี่ยนไป จากการเรียนแบบเน้นหนักด้านคณิตศาสตร์ ไปสู่การนำหลักสถิติศาสตร์มาเพื่อใช้แก้ปัญหาแบบองค์รวม
เราต้องมองว่าสถิติคือเครื่องมือที่ทำให้เราตัดสินใจได้แม่นยำขึ้นครับ
อยากทำงานกับดาต้าต้องตั้งคำถามให้เป็น
อีกหนึ่งแง่คิดในเล่มนี้ที่น่าสนใจคือเรื่องของการตั้งคำถาม ตัวอย่างเช่นถ้าเราอยากรู้ว่ามีเด็กที่เสียชีวิตเพราะผ่าตัดหัวใจเท่าไหร่ สิ่งสำคัญที่เราต้องทำก่อนลงมือหาคำตอบคือต้องแยกรายละเอียดไปจนถึงองค์ประกอบของคำถามให้ชัดเจนว่า “เด็ก” ในที่นี้จะนับตั้งแต่อายุเท่าไหร่ลงไป เพราะนิยามของคำว่าเด็กมีมากมาย ตั้งแต่เด็กอ่อน เด็กเล็ก เด็กโต หรือเด็กวัยรุ่น แล้วก็ตีออกมาเป็นตัวเลขชัดๆ ว่าแค่ไหนคือเด็ก เพื่อที่จำได้เลือกข้อมูลที่ถูกต้องมาวิเคราะห์หาคำตอบได้ชัดเจน
แล้วก็ต้องระบุให้ชัดเจนว่า การเสียชีวิตที่ว่านี่จะนับแบบไหน เช่น นับแบบภายใน 24 ชั่วโมงหลังผ่าตัดเสร็จ หรือนับแบบ 7 วันหลังผ่าตัดเสร็จ หรือนับ 30 วันหลังผ่าตัดเสร็จ
เห็นไหมครับว่าคำถามที่ดูเหมือนไม่มีอะไรกลับมีอะไรมากมายให้ทำ ดังนั้นก่อนจะเริ่มต้นทำงานกับดาต้าทุกครั้ง แต่ตีโจทย์ออกมาเป็น Data Attributes ให้ชัดเจนว่าเราจะวัดผลสิ่งนี้แบบไหน อย่างไร
“สุ่มตัวอย่าง” การรีเสิร์จแบบโลกเก่าที่อาจจะเอาท์ไปเสียแล้ว
การรีเสิร์จแบบโลกเก่าที่มีการสุ่มตัวอย่างจากคนไม่กี่คน เช่น n = 20, 200, 400, 1,200 หรือ 2,000 อาจไม่ตอบโจทย์ของโลกทุกวันนี้ เพราะในวันนี้เราสามารถเข้าถึงดาต้าจากผู้คนมหาศาลได้มากมายหลายวิธี แล้วเหตุใดเราถึงยังต้องใช้ sampling data จากกลุ่มคนจำนวนน้อยมากมาใช้ตัดสินใจกลุ่มเป้าหมายนับล้านๆ คนของเราอยู่หละ
ในยุค 1930 การรีเสิร์จแบบนี้ถูกคิดค้นขึ้นมาด้วยการเปรียบเทียบกับการชิมซุปในหม้อ ซึ่งถ้าเราคนซุปดีๆ เราสามารถรู้รสทั้งหม้อได้โดยไม่ต้องชิมทั้งหมด แต่ประเด็นคือเราจะแน่ใจได้อย่างเราว่าเราเลือกกลุ่มตัวอย่างที่สามารถเป็นตัวแทนของกลุ่มเป้าหมายทั้งหมดของเราได้ ซึ่งในวันที่วิธีการนี้ถูกคิดค้นขึ้นก็ดูจะเหมาะสม แต่ในวันนี้ที่มีเทคโนโลยีและดาต้ามากมายก็ดูจะเป็นอะไรที่ไม่เหมาะกับโลกยุคใหม่ทุกวันนี้แล้วครับ
นอกจากนี้หนังสือเล่มนี้ยังพูดถึงวิธีการทาง Statistics ที่น่าสนใจหลายอัน ซึ่งเป็นสิ่งที่ Data Scientist น่าจะคุ้นเคยกันดีแต่คนทั่วไปอาจไม่คุ้น ซึ่งผมคิดว่านักการตลาดที่สนใจเรื่องดาต้าจำเป็นต้องรู้ไว้ว่าเรามีเครื่องมือแบบไหนในการวิเคระห์ข้อมูลได้บ้างครับ
Logarithmic scale ช่วยให้เห็นการกระจายตัวของข้อมูลดีขึ้น
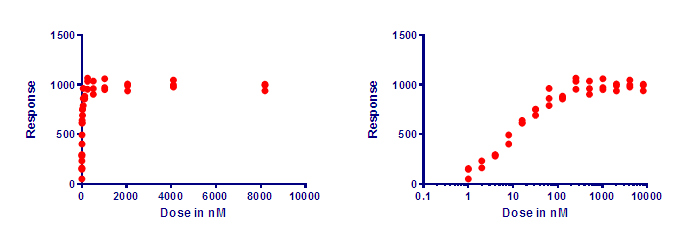
หลายครั้งข้อมูลมีการกระจุกตัวกันทำให้ยากต่อการวิเคราะห์ต่อยอดได้ ซึ่งปกติแล้วข้อมูลมักจะแสดงผลแบบ Linear หรือเส้นตรงตามลำดับ แต่ถ้าเราปรับมาแสดงผลแบบ Logarithmic เราจะเห็นการกระจายตัวของข้อมูลที่ดีขึ้นตามภาพครับ
Regression
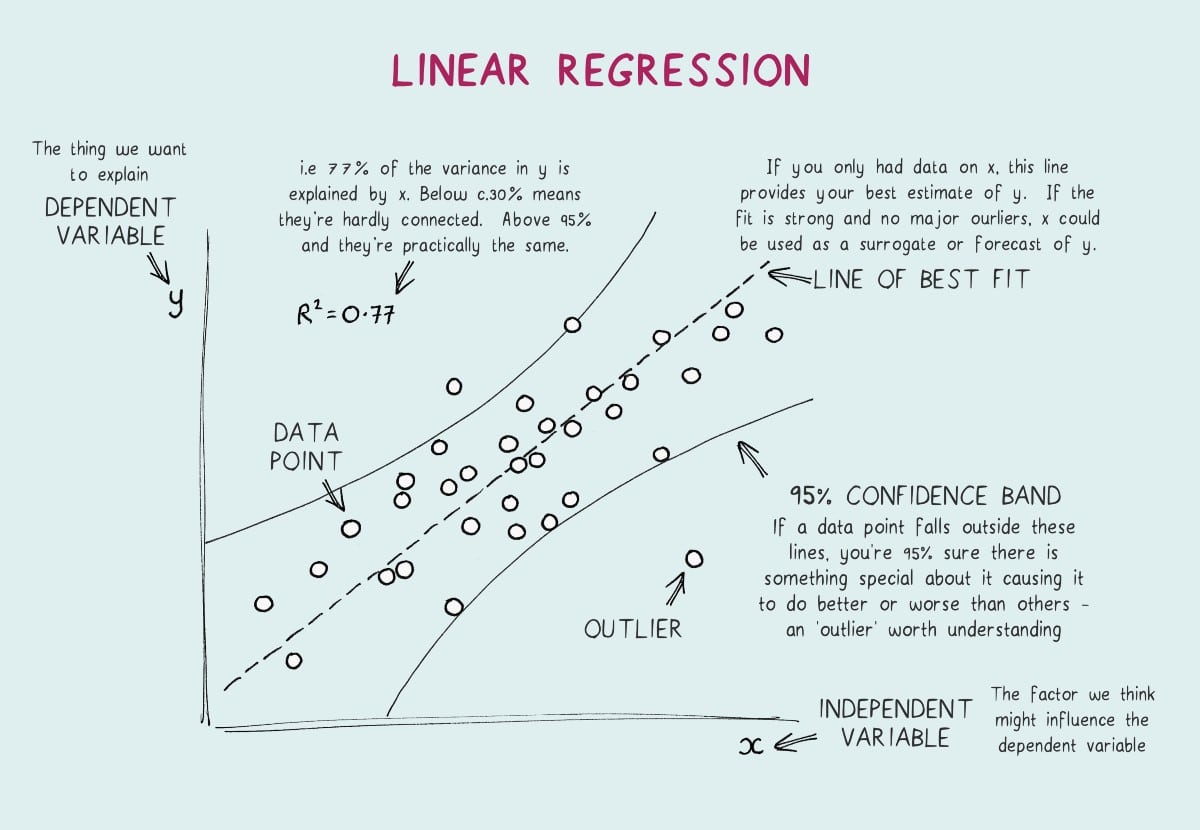
อีกหนึ่งหลักสถิติที่สำคัญที่นักการตลาดควรรู้ครับ เพราะถ้าเราวิเคราะห์จนรู้อดีตที่มาที่ไปได้ เราก็สามารถ predict ล่วงหน้าได้ระดับหนึ่งเลยว่าสิ่งที่เกิดขึ้นนี้ดีหรือไม่ดี แล้วเราควรจะปรับอย่างไรให้มันดีขึ้น
Unsupervised Learning
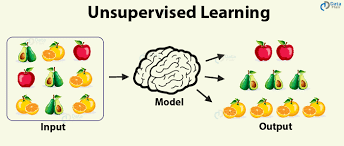

คือการที่เราใส่ข้อมูลเข้าไปแล้วปล่อยให้ระบบเรียนรู้และทำงานด้วยตัวเอง จากนั้นเราอาจจะมีการปรับแต่ง model หรือ algorithm ให้ทำงานฉลาดขึ้นได้
ด้านล่างคือภาพความแตกต่างระหว่าง Supervised Learning (สอนคอมให้รู้ด้วยคน) กับ Unsupervised Learning ปล่อยให้คอมเรียนรู้ด้วยตัวเองก่อนแล้วเราค่อยกลับไปสอนอีกทีนึงให้มันฉลาดขึ้น

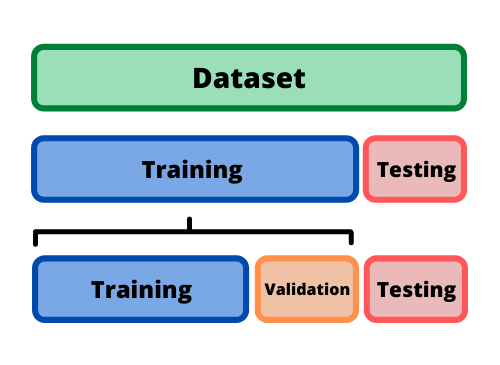
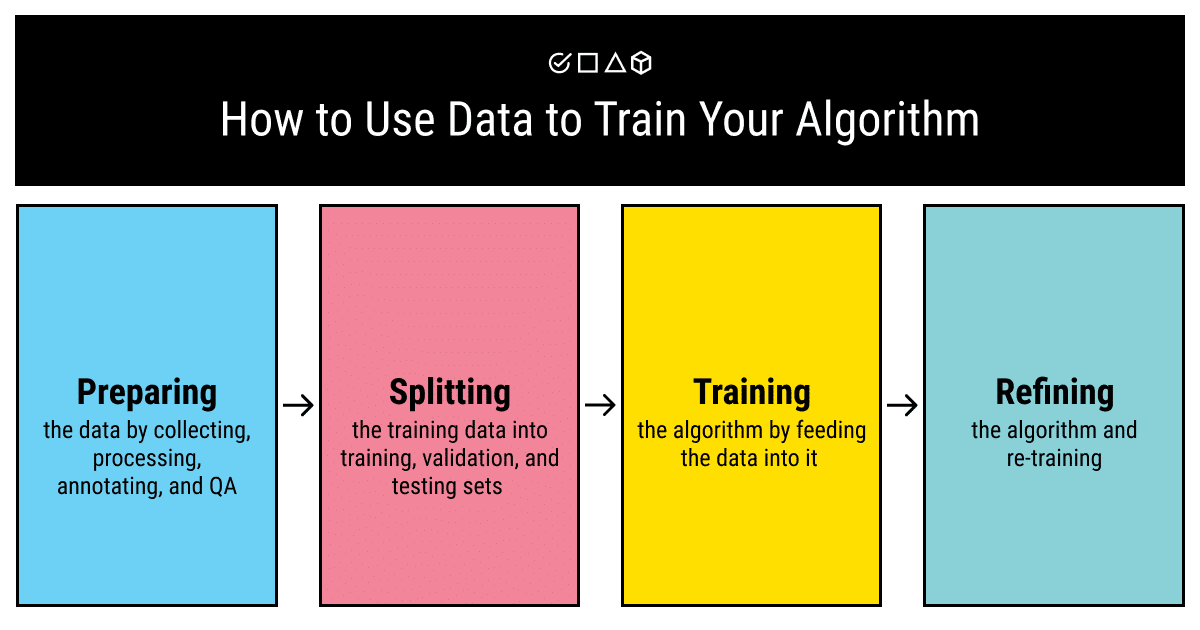
A/A Testing แบ่ง Data ส่วนหนึ่งเอาไว้ทดสอบสมมติฐานด้วยว่าแม่นจริง

หลักการนี้ผมเขียนไว้ในหนังสือ Data Thinking ทำธุรกิจให้รุ่งยอดขายพุ่งด้วยดาต้า ไว้แล้ว แต่ขอหยิบมาอธิบายสั้นๆ อีกรอบเพราะหนังสือเล่มนี้ก็พูดถึงประเด็นเดียวกัน
การวิเคราะห์ข้อมูลที่ดีเราควรแบ่งข้อมูลออกเป็นสองชุดระหว่าง Data Training Set กับ Data Testing Set พูดง่ายๆ คือชุดแรกสำหรับการเอามาเทรนโมเดล สร้าง Algorithm เพื่อจะได้นำไปใช้ทำงานแทนเรา ชุดหลังคือข้อมูลจากชุดเดียวกันที่ถูกแบ่งออกมาส่วนหนึ่งเพื่อใช้ทดสอบสมมติฐานหรือ Algorithm ที่หาได้จาก Data Training Set ว่าได้ผลลัพธ์แบบเดียวกันหรือต่างกันไม่มาก ไม่ใช่ผิดเพี้ยนไปมากจะได้กลับไปเริ่มต้นวิเคระาห์หาคำตอบใหม่
กฏหมาย Algorithm โมเดลต้องโปร่งใส ตรวจสอบได้ว่าไร้ Bias
บางประเทศในยุโรปมีการออกกฏว่า Algorithm ต้องห้ามใส่ตัวแปรหรือ Attribute บางอย่างที่สะท้อนถึง Bias ไม่ว่าจะเพศ อายุ เชื้อชาติ หรืออื่นใดก็ตามที่บอกให้รู้ว่าถูกใช้นำมาเป็นเกณฑ์การตัดสินที่ไม่เท่าเทียม
และนั่นอาจส่งผลกระผลให้ Algorithm แบบ Black box อาจถูกปัดตกทิ้งไปให้ไม่สามารถใช้งานได้ในบางประเทศที่ออกกฏแบบนั้น ซึ่งทำให้ต้องกลับมาใช้โมเดลแบบ Regression ที่สามารถตรวจสอบได้ว่าใช้ Attributes ใดบ้างเป็นเกณฑ์
HARKing เลือกคำตอบใหม่หลังรู้ผล
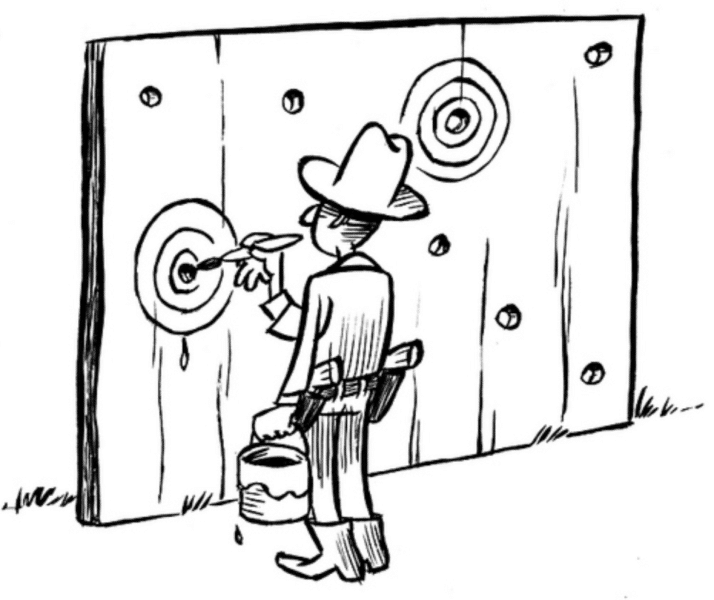
ข้อนี้น่าสนใจและต้องพึงระวังไว้ให้ดี บางครั้งเมื่อเราตั้งสมมติฐานแล้ววิเคราะห์ข้อมูลออกมาได้อีกแบบ กลายเป็นว่าเราเอาคำตอบใหม่ที่ได้กลายเป็นสมมติฐานตั้งต้นแทน ภาพด้านบนเปรียบเทียบได้ดีครับ
สรุปหนังสือ The Art of Statistics Learning from Data
ถ้าใครได้อ่านหนังสือเล่มนี้ Storytelling with Data ผมแนะนำให้คุณอ่านหนังสือเล่มนี้ต่อ เพราะจะพาคุณไปทำความเข้าใจดาต้าที่ลึกซึ้งขึ้น แต่ยังคงอยู่ในระดับที่มนุษย์ทั่วไปอ่านได้ (เช่นผม) แล้วคุณจะพบว่าโลกของดาต้านั้นมีอะไรอีกมากให้เรียนรู้ และหลักการทางสถิติศาสตร์ก็ไม่ได้น่ากลัวอย่างที่เราเคยเรียนมาสมัยมัธยมกันสักเท่าไหร่เลย
อ่านแล้วเล่า เล่มที่ 28 ของปี 2021

สรุปหนังสือ The Art of Statistics Learning from Data
เท่าทันข้อมูล ทลายกำแพงตัวเลขด้วยศาสตร์และศิลป์แห่งสถิติ
David Spiegelhalter เขียน
สุนันทา วรรณสินธ์ แปล
สำนักพิมพ์ Bookscape
อ่านสรุปหนังสือการตลาดแนะนำต่อ > https://www.everydaymarketing.co/category/book-recommended/
สั่งซื้อออนไลน์ > https://click.accesstrade.in.th/go/QfiCdGag




{kind=link}