Centrality หลักการที่อยู่เบื้องหลังการหา Influencer ที่แท้จริง
Centrality หลักการที่อยู่เบื้องหลังการหา influencer ที่แท้จริง ในยุคนี้อะไรๆก็เชื่อมต่อถึงกันไปหมด ทำให้ความสัมพันธ์มีความสลับซับซ้อนเกิดเป็นเครือข่าย (network) ในรูปแบบต่างๆ เช่น เครือข่ายทางสังคมออนไลน์ (social media network) เครือข่ายการเดินทางสาธารณะ เป็นต้น และภายใต้เครือข่ายเหล่านี้ สิ่งที่มักจะถูกให้ความสนใจเป็นพิเศษก็คือ สมาชิกในเครือข่ายที่มีอิทธิพล เชื่อมต่อหรือมีความสัมพันธ์กับสมาชิกอื่นๆในเครือข่ายมากเป็นพิเศษ
อย่างเช่น เมื่อนึกถึงสถานีรถไฟฟ้าบีทีเอส เรามักจะนึกถึงสถานีสยามซึ่งเป็นจุดศูนย์กลางหลักที่เชื่อมต่อระหว่างสายสุขุมวิทและสายสีลม เป็นต้น แต่สำหรับผมและหลายๆคนกลับนึกถึงสถานีอื่นๆ เช่น ผมนึกถึงสถานีพร้อมพงษ์เพราะอยู่ใกล้ เดินทางสะดวก บางคนนึกถึงสถานีศาลาแดงหรืออโศกเพราะเป็นจุดเชื่อมต่อกับรถไฟฟ้าใต้ดิน MRT บางคนนึกถึงสถานีพญาไทเพราะเป็นจุดที่ใกล้ทั้งที่พักและที่ทำงานที่สุด เป็นต้น ในเมื่อมีหลายแนวทางในการพิจารณาหาจุดที่มีความสำคัญในเครือข่าย แล้วหลักการไหนหล่ะที่เป็นหลักการมาตรฐานในการพิจารณาหาจุดสำคัญเหล่านั้น

Centrality คืออะไร
Centrality คือ หลักการในการหาค่าของจุดต่างๆ ที่มีผลต่อ network ที่จุดนั้นเป็นสมาชิก ซึ่งคำจำกัดความของ centrality ในงานด้านการวิเคราะห์เครือข่ายทางสังคม (social network analysis) คือ ค่าที่แสดงถึงการเชื่อมโยงระหว่างจุดหนึ่งกับจุดอื่นๆ ในเครือข่าย ซึ่งการหาค่า centrality สามารถทำได้หลายวิธี ดังต่อไปนี้
Local หรือ Degree Centrality
“สถานีสยาม สถานี BTS ที่ popular ที่สุด”
Local หรือ Degree Centrality ถือเป็น Centrality ในท่ามาตรฐานที่พิจารณาจำนวนการเชื่อมต่อติดกันหรือความสัมพันธ์ทั้งหมดของจุด (node) ใดจุดหนึ่งเท่านั้น โดยไม่คำนึงถึงว่าจุดที่มาเชื่อมต่อหรือมีความสัมพันธ์กับจุดๆนั้น มีความสำคัญหรือมีอิทธิพลขนาดไหน หากใช้หลักการนี้พิจารณาเลือกสถานีรถไฟฟ้าบีทีเอสที่มีความเป็นศูนย์กลาง
หรือมีค่า Degree Centrality สูงที่สุด ก็คงจะต้องนึกถึงสถานีสยาม เนื่องจากเป็นสถานีที่อยู่ติดกันกับสถานีอื่นถึง 4 สถานี ได้แก่ สถานีชิดลม สถานีราชเทวี สถานีราชดำริ และสถานีสนามกีฬาแห่งชาติ มากกว่าสถานีอื่นๆ ที่ส่วนใหญ่มักอยู่ติดกับสถานีอื่นเพียง 2 สถานี ดังนั้น ในทางปฏิบัติมักประยุกต์ใช้หลักการของ Local หรือ Degree Centrality ในการหาว่าใครหรือ node ใดที่ได้รับความนิยมสูงสุดหรือต่ำสุด
สำหรับ concept ในการคำนวณ จากรูปจะเห็นว่า node A มีค่า degree เท่ากับ 2 เนื่องจากอยู่ติดกันกับ node B และ node C ส่วน node E มีค่า degree เท่ากับ 1 เนื่องจากอยู่ติดกันกับ node B เพียง node เดียว อย่างไรก็ดีในทางปฏิบัติจะมีการปรับค่าให้เป็นค่ามาตรฐาน (standardization) ก่อน เพื่อให้สามารถนำค่าต่างๆ ของ network ที่มีขนาดแตกต่างกันมาเปรียบเทียบกันได้ (ลด network size effect ต่อ degree centrality)
สำหรับการหาค่า degree centrality นั้น นิยมปรับค่าให้เป็นค่ามาตรฐานด้วยการนำพจน์ (n-1)(n-2) มาหารค่า degree โดยที่ n คือ จำนวน node ทั้งหมดใน network ตัวอย่าง เช่น ค่า degree ของ node A หลังทำ standardization จะเท่ากับ 2/(5–1)(5–2) = 0.167 เป็นต้น

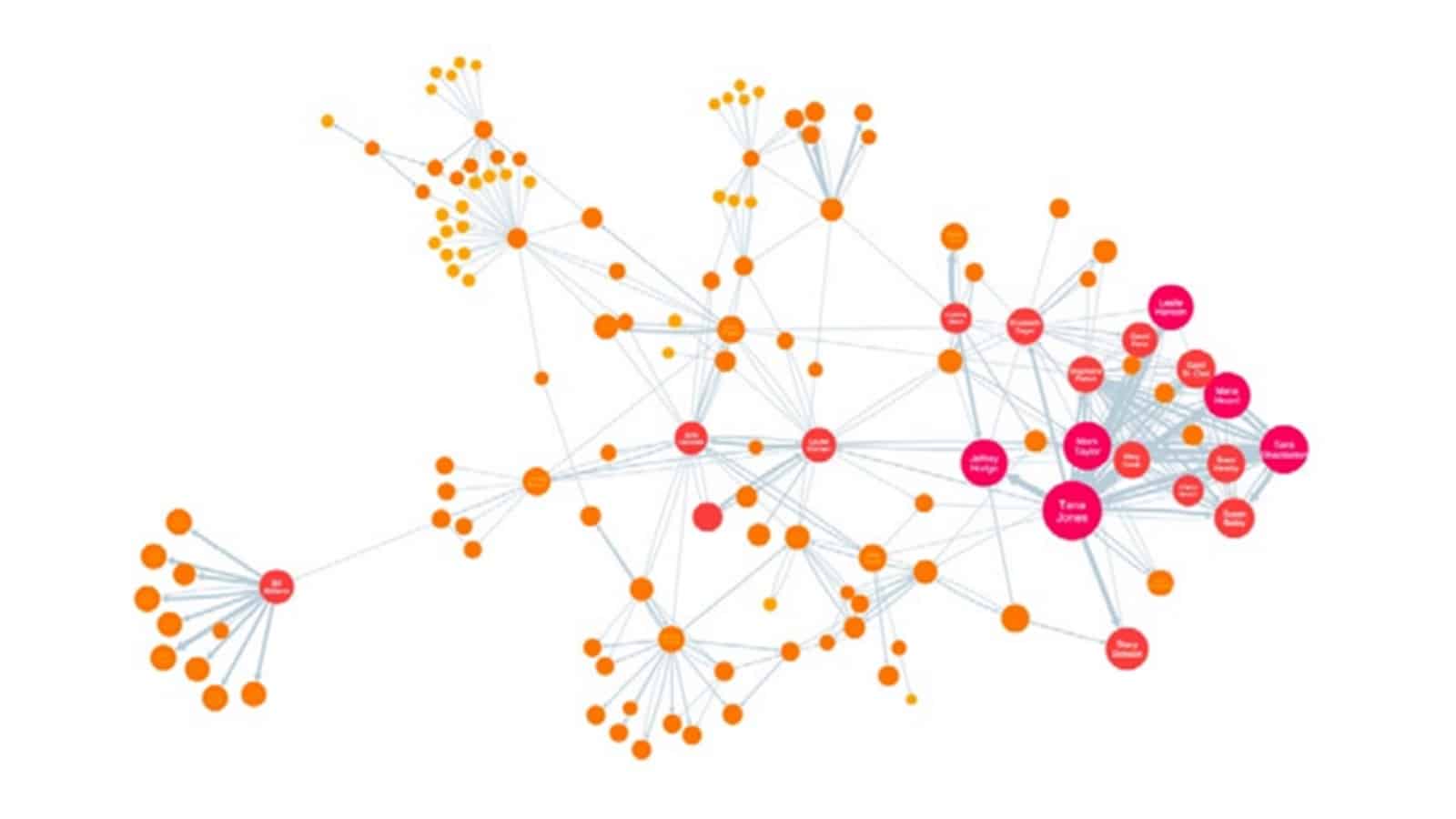
จากรูปตัวอย่าง network ด้านล่างจะเห็นว่าจุดสีชมพูมีขนาดใหญ่ที่สุดเนื่องจากเป็นจุดที่มีอยู่ติดกันกับจุดอื่นๆใน network จำนวนมากที่สุดหรือกล่าวอีกนัยหนึ่งคือเป็นจุดที่มีค่า Degree Centrality มากที่สุด สังเกตว่าจุดที่มีค่า Degree Centrality สูงที่สุดไม่จำเป็นที่จะต้องตั้งอยู่ในตำแหน่งศูนย์กลางของระบบหรือ network

Betweenness centrality
“ระหว่างสถานีสยามถูกสั่งปิดกับสถานีกรุงธนบุรีถูกสั่งปิด อันไหนน่าปวดหัวมากกว่ากัน?”
แน่นอนว่าคำตอบต้องเป็นสถานีสยาม เนื่องจากเป็นสถานีศูนย์กลางที่ถือว่าเป็นจุดที่เชื่อมต่อไปยังสถานีอื่นๆ โดยรอบมากที่สุด ส่วนสถานีกรุงธนบุรีถึงแม้จะเป็นจุดเชื่อมต่อไปยังรถไฟฟ้าสายสีทองแต่หากพิจารณาจำนวนสถานีโดยรอบแล้วพบว่ามีจำนวนน้อยกว่าในกรณีของสถานีสยาม ตัวอย่างนี้ใกล้เคียงกับหลักการของ betweenness centrality โดยหาก node นั้นมี betweenness centrality score สูง node นั้นถือว่าเป็นจุดเชื่อมต่อที่สำคัญระหว่าง node อื่นๆ
ซึ่งสามารถนำไปสู่การพิจารณาหา short pathway ใน network ได้ ดังนั้นในทางปฏิบัติจึงมักพบการนำ betweenness centrality มาช่วยพิจารณาหาจุดศูนย์กลางที่เป็นจุดที่น่าสนใจของ network เช่น หาจุดที่เป็นจุดศูนย์กลางควบคุมการกระจายข้อมูล หรือหาตำแหน่งที่กระทบกับ flow งานมากที่สุด หากมีปัญหาเกิดขึ้น เป็นต้น
การหาค่า betweenness ของ node ใดๆ ใช้หลักการง่ายๆ คือ ดูจำนวนครั้งทั้งหมดที่ node นั้นทำหน้าที่เป็นสะพานหรือตัวกลางในการเชื่อมต่อระหว่างสองจุดใดๆ ตัวอย่าง เช่น การหาค่า betweenness ของสถานีสยามให้นับจำนวนครั้งทั้งหมดที่การเดินทางระหว่างสองสถานีใดๆจะมีการเดินทางผ่านสถานีสยาม เป็นต้น
เพื่อให้เข้าใจ concept ในการคำนวณได้ดีขึ้น จากรูปจะเห็นว่า node A มีค่า betweenness เท่ากับ 4 เนื่องจาก node A ทำหน้าที่เป็นสะพานหรือตัวกลางในการเชื่อมต่อระหว่าง
- node E และ C
- node E และ D
- node B และ C
- node B และ D
ส่วน node B มีค่า betweenness เท่ากับ 3 เนื่องจาก node B ทำหน้าที่เป็นสะพานหรือตัวกลางในการเชื่อมต่อระหว่าง
- node E และ A
- node E และ C
- node E และ D เป็นต้น
สำหรับการปรับค่าให้เป็นค่ามาตรฐาน (standardization) ของค่า betweenness นิยมนำพจน์ (n-1)(n-2)/2 มาหารค่า betweenness โดยที่ n คือ จำนวน node ทั้งหมดใน network ตัวอย่าง เช่น ค่า betweenness ของ node A หลังทำ standardization จะเท่ากับ 4/[(5–1)(5–2)/2] = 0.53 เป็นต้น

จากรูปตัวอย่าง network ด้านล่างจะเห็นว่าจุดสีชมพูมีขนาดใหญ่ที่สุดเนื่องจากเป็นจุดศูนย์กลางที่เชื่อมต่อกับจุดอื่นๆใน network สังเกตได้ว่าจุดที่มีค่า betweenness centrality สูงมักเป็นจุดในตำแหน่งศูนย์กลางของระบบหรือ network

Closeness centrality
“ตั้งต้นเดินทางจากสถานีไหนใกล้ ประหยัดเวลาเดินทางมากที่สุด”
หลักการของ closeness centrality คล้ายกับหลักการของ betweenness centrality แต่แตกต่างกันตรงที่ betweenness centrality พิจารณาจากการนับจำนวนทั้งหมดของ path หรือเส้นทางระหว่างสองจุดใดๆ ที่ตัดผ่านจุดที่สนใจ ส่วน closeness centrality พิจารณาจากระยะทางรวมของ shortest path ทั้งหมดของจุดที่สนใจไปหาจุดอื่นๆ ทั้งหมด
หากระยะทางรวมของ shortest path ทั้งหมดของจุดใดสั้น หมายความว่าจุดนั้นจะมีค่า closeness centrality score สูง ดังนั้นการหาค่า closeness ของ node ใดๆ จึงคิดจากการหาส่วนกลับของผลรวมทั้งหมดของจำนวน step ระหว่าง node ที่พิจารณากับ node อื่นๆ ที่เหลือใน network (นำ 1 มาหารด้วยผลรวมทั้งหมดของจำนวน step ระหว่าง node ที่พิจารณากับ node อื่นๆ)


เมื่อพิจารณาจากรูปและตารางประกอบกัน จะเห็นว่าผลรวมทั้งหมดของจำนวน step ระหว่าง node A กับ node อื่นๆ ที่เหลือใน network จะเท่ากับ 6 โดยคิดมาจาก 1 {จำนวน step จาก A-B} + 1 {จำนวน step จาก A-C} + 2 {จำนวน step จาก A-D} + 2 {จำนวน step จาก A-E} ดังนั้นก่อนทำ standardization node A จะมีค่า closeness เท่ากับ 1/6 = 0.167 สำหรับการปรับค่าให้เป็นค่ามาตรฐาน (standardization) ของค่า closeness นิยมนำพจน์ (n-1) มาคูณกับค่า closeness โดยที่ n คือ จำนวน node ทั้งหมดใน network ดังนั้นค่า closeness ของ node A หลังทำ standardization จะเท่ากับ (5–1)*0.167 = 0.67 เป็นต้น
เนื่องจากหลักการของ closeness centrality เกี่ยวข้องกับ shortest path ดังนั้นการประยุกต์ใช้จึงมักเกี่ยวข้องกับการหาคำตอบเกี่ยวกับเรื่องของประสิทธิผล (efficacy) การประหยัดเวลา และความสะดวก เป็นหลัก

จากรูปตัวอย่าง network ด้านบนจะพบจุดสีชมพูขนาดใหญ่จำนวนหลายจุดและส่วนใหญ่ไม่ได้ตั้งอยู่ในตำแหน่งศูนย์กลาง จึงเป็นข้อสังเกตได้ว่าหาก network มีการกระจุกตัวกันของสมาชิก จะทำให้มีจุดที่มีค่า closeness centrality ใกล้เคียงกันจำนวนหลายจุด หรืออาจกล่าวได้ว่าการพิจารณาด้วยหลักการของ closeness centrality จะให้ insight ที่เป็นประโยชน์สูงที่สุดในกรณีที่สมาชิกใน network กระจายตัวกัน (sparsely connected)
Eigen centrality
“ภาคต่อของ Degree Centrality”
หลักการของ Eigen centrality ใช้หลักของ Degree Centrality ร่วมกับการพิจารณาความสำคัญของจุดที่มาเชื่อมต่อหรือมีความสัมพันธ์กับจุดๆนั้น โดยอาศัยหลักการพื้นฐานของ Eigenvector ในการคำนวณ ซึ่งหากเปรียบเทียบเพื่อให้เห็นภาพ ในกรณีของสถานีรถไฟฟ้าบีทีเอส หากต้องเลือกสถานีที่ติดกับสถานีสยาม (ได้แก่ สถานีชิดลม สถานีราชเทวี สถานีราชดำริ และสถานีสนามกีฬาแห่งชาติ) เพียงหนึ่งสถานีที่สำคัญที่สุดด้วยหลักการของ Eigen centrality คงต้องเลือกสถานีราชดำริ เนื่องจากเป็นสถานีที่การเชื่อมต่อกับสถานีศาลาแดง ซึ่งถือว่าเป็นสถานีใกล้เคียงที่มีความสำคัญที่สุดเนื่องจากสถานีศาลาแดงเป็นสถานีสำคัญที่ผู้โดยสารสามารถเชื่อมต่อกับบริการของรถไฟฟ้าใต้ดิน MRT ได้
ซึ่งทำให้ผู้โดยสารสามารถเดินทางต่อไปยังสถานีอื่นๆ ได้อีกจำนวนมาก สถานีที่มี Eigen centrality รองลงมา คือ สถานีราชเทวี ซึ่งเชื่อมต่อกับสถานีพญาไท ซึ่งเป็นสถานีที่เชื่อมต่อกับรถไฟฟ้า airport rail link และแน่นอนว่าสถานีสนามกีฬาแห่งชาติมี Eigen centrality ต่ำที่สุด เนื่องจากไม่มีการเชื่อมต่อกับสถานีใดๆ ต่อเลย
อย่างไรก็ดีการวิเคราะห์หา Eigen centrality อาจมี bias ซ่อนอยู่ ลองนึกถึงการที่คนที่เพิ่งสมัครเข้ามาเล่น Facebook (New user) แล้วไปเป็นเพื่อนกับท่านนายกประยุทธ์ ซึ่งถือเป็นบุคคล (node) สำคัญ เนื่องจากมี Facebook friend อยู่เป็นจำนวนมาก ทำให้ New user รายนั้น ถูกมองว่าเป็นบุคคล (node) สำคัญเนื่องจากมี Eigen centrality สูงได้ ถึงแม้ว่าจะมี Degree Centrality ต่ำก็ตาม Bias ในลักษณะนี้บางทีเรียกว่า “Hub Bias” โดยจากตัวอย่างท่านนายกประยุทธ์เปรียบเสมือน hub นั่นเอง
การคำนวณหาค่า Eigen centrality ใช้การหลักการคำนวณ adjacency matrix เพื่อหา principal eigenvector ซึ่งการคำนวณมีความซับซ้อนจึงไม่ขอกล่าวในที่นี้ Eigen centrality มักถูกประยุกต์ใช้ในการตอบคำถามเพื่อหาบุคคลหรือสิ่งที่มีความสำคัญใน network ในระดับ macro scale หรือมีความสามารถในการเข้าถึงบุคคลหรือสิ่งที่มีอิทธิพลกว้างขวางใน network ตัวอย่าง เช่น มีการใช้ Eigen centrality มาประยุกต์เพื่อวิเคราะห์ความสัมพันธ์ของเครือข่ายนักวิจัย เป็นต้น
จากรูปตัวอย่าง network ด้านล่างจะเห็นว่าจุดสีชมพูที่มีขนาดใหญ่เป็นจุดที่เชื่อมต่อติดกันกับจุดอื่นๆใน network จำนวนมาก (degree score สูง) และจุดที่จุดนั้นเชื่อมต่อด้วยเป็นจุดที่มี degree score สูงเช่นกัน

PageRank centrality
“Concept จาก Google”
เพื่อแก้ปัญหา hub bias ดังเช่นจาก Eigen centrality ทำให้มีการคิดค้นหลักการที่ช่วยแก้ไขปัญหาดังกล่าว โดยผู้คิดค้นก็คือทีมผู้ก่อตั้ง Google search engine นั่นเอง พวกเขานำเสนอ centrality แบบใหม่ โดยเรียกมันว่า “PageRank centrality” เพื่อนำมา ranking web content โดยการให้ความสำคัญกับ hyperlinks ระหว่าง pages ต่างๆ
โดยพิจารณาถึงทิศทางของการ link กันด้วยนั่นเอง กล่าวคือ หากทิศทางการ link กันเป็นในแบบที่ page อื่นๆ link มายัง page นั้นเยอะๆ ย่อมทำให้ page นั้นมีน้ำหนักหรือความสำคัญมากกว่าการที่พยายาม link page นั้นกับ page อื่นๆ ดังนั้นในการให้คะแนนต่อ page ต่างๆ ใน network จะพิจารณาจากจำนวน link ทั้งหมด ที่ page อื่นๆ link มายัง page นั้นๆ (indegree) เป็นหลัก ร่วมกับการพิจารณาคะแนนสัมพัทธ์ของ page ต่างๆ ที่ page นั้น link ด้วย
แม้ว่า PageRank centrality ถูกคิดค้นมาเพื่อจุดประสงค์ในการ ranking web content เป็นหลัก แต่ในทางปฏิบัติเราสามารถประยุกต์ใช้ PageRank centrality กับ network ในแบบอื่นๆ ที่ให้ความสำคัญกับ link direction ได้เช่นกัน ตัวอย่าง เช่น การศึกษาการอ้างอิงหรือ citation การ visualize IT network activity การทำโมเดลเพื่อศึกษาผลของการทำ SEO และ link building activity เป็นต้น

กล่าวโดยสรุป centrality คือ ค่าของ node ต่างๆ ที่มีผลต่อ network ซึ่งคำจำกัดความของ centrality ในงานด้านการวิเคราะห์เครือข่ายทางสังคม (social network analysis) คือ ค่าที่แสดงถึงการเชื่อมโยงของ node หนึ่งไปยัง node อื่นๆ ซึ่งการหาค่า centrality ทำได้หลายวิธี เช่น degree centrality, betweenness centrality, closeness centrality, eigenvector centrality และ PageRank centrality เป็นต้น ซึ่งแต่ละวิธีก็มีจุดเด่นจุดด้อยที่แตกต่างกัน ดังนั้นจึงต้องนำไปประยุกต์ใช้อย่างเหมาะสมในทางปฏิบัติ โดยพิจารณาถึงลักษณะของงานและจุดประสงค์ ลักษณะข้อมูลที่เกี่ยวข้อง ตลอดจนเข้าใจถึง network dynamics และ network influence
Bonus
เราสามารถประยุกต์ใช้วิธีการหาค่า centrality หลายๆ วิธีในงานๆ หนึ่งได้ และหากศึกษาเพิ่มเติมจะพบว่ามีความพยายามในการคิดค้นวิธีการหาค่า centrality ใหม่ที่มีความจำเพาะเจาะจงกับแต่ละงานและจุดประสงค์มากขึ้น ตัวอย่าง เช่น เมื่อกลางปี ค.ศ. 2020 ได้มีนักวิจัยนำเสนอ Distinctiveness centrality เพื่อใช้กับงาน social networks เป็นต้น
ขอบคุณ คุณ Sorrakorn Juntarasiripas เจ้าของบทความที่อนุญาตให้นำมาแบ่งปันในการตลาดวันละตอนด้วยครับ

อ่านบทความที่เกี่ยวกับ Data Science for Marketing ในการตลาดวันละตอนต่อ > https://www.everydaymarketing.co/?s=data+science





{kind=link}