ML model(s) หรือ RFM: Customer Segmentation ข้อมูลนี้ใช้โมเดลอะไรดี?

สวัสดีค่ะ นิกเชื่อว่าหลังจากที่พวกเราศึกษา/นั่งอ่าน หรืออาจนอนอ่าน 🙂 บทความทั้งในไทยและต่างประเทศ เพื่อหาแนวทางแบ่งกลุ่มลูกค้า (ML model หรือ RFM) ในการจัดทำ Customer Relationship Management (CRM) ให้ถูกกลุ่ม เรามักจะเกิดความสงสัยที่ว่า…
แล้ว Model(s) อะไรล่ะ ที่จะเหมาะสมในการใช้จัดกลุ่มลูกค้าของเรา หรือเราจะโยนข้อมูลที่เรามีทุกอย่างลง Machine Learning ชื่อเท่ๆ ซักโมเดล หรือทำ RFM แล้วบูมมมม ได้ Segments ของลูกค้าที่เราต้องการออกมา ตามคำพูดที่ว่า “DATA IS THE NEW OIL” (credit: Clive Humby)
แต่ช้าก่อนค่ะ!! ยังมีคำว่า Garbage in, garbage out อีก (ขอติดไว้ก่อนนะคะ เนื้อหาเรื่องนี้จะอยู่ในช่วงของการทำ Data Preparation และการหา Corelation เพื่อเลือก Feature ของข้อมูลให้สอดคล้องกับผลลัพธ์ที่เราอยากได้ ซึ่งเป็นกระบวนการจัดเตรียมข้อมูลก่อนนำข้อมูลนั้นมาหา Insight ค่ะ^^)
Segmentation VS Clustering
ก่อนอื่นเรามาทำความเข้าใจกันก่อนค่ะว่าการแบ่งกลุ่มลูกค้า ด้วยวิธี 2 วิธีนี้มีความแตกต่างกันอย่างไรในเทอมของวัตถุประสงค์ในการแบ่งกลุ่มค่ะ 😊
Segmentation: วิธีนี้จะนิยมใช้กับการที่เรามีโจทย์ค่อนข้างชัดเจนค่ะ ว่าเราต้องการจะพิจารณาลูกค้าในมุมอง (Criteria) ไหนบ้าง เช่นพิจารณาจากพฤติกรรมการซื้อ/การเข้าใช้งาน ที่เรียกว่า Behavioral Analysis หรือจะมองในมุมของ Demographic ที่โฟกัสไปที่เรื่องของ อายุ, เพศ, อาชีพ, รายได้, การศึกษา หรือสถานภาพ(โสด/สมรส) หรือเราจะแบ่งกลุ่มลูกค้าตาม Customer Value (มูลค่าของลูกค้า) ก็ได้เช่นเดียวกัน ซึ่งผลลัพธ์ที่ได้ออกมาจากการแบ่งกลุ่มลูกค้าด้วยหลักการทำ Segmentation คือเราจะได้กลุ่มลูกค้าที่ชัดเจน และประเภทของกลุ่มลูกค้านั้นๆ แบบเฉพาะ— RFM model ที่เรากำลังจะพูดถึงกันก็เป็นหนึ่งในวิธีที่ใช้แบ่งกลุ่มลูกค้าตามหลักการ Customer Value ค่ะ
Clustering: การแบ่งกลุ่มลูกค้าด้วยวิธีนี้ จะจัดกลุ่มลูกค้าที่มีความคล้ายคลึงกันของข้อมูล (Features) ให้อยู่กลุ่มเดียวกัน โดยที่เราไม่ได้มีโจทย์มาก่อนว่าจะประเมินลูกค้าในมุมมองใดเป็นพิเศษ แต่ต้องการที่จะทำการรวม Group/Cluster ของลูกค้า แต่หลังจากที่เราทำการ Clustering หรือแบ่งกลุ่มลูกค้าด้วยวิธีนี้แล้ว เราไม่สามารถระบุได้นะคะว่า ลูกค้ากลุ่มนี้ เป็นลูกค้าแบบไหน จะเป็น High Value customer มั๊ย? หรือจะเป็นลูกค้าที่กำลังจะโดนแย่งไปโดยคู่แข่ง! ซึ่งข้อมูลส่วนนั้นเราต้องมาทำการวิเคราะห์เองต่อเพิ่มเติมเพื่อทำ CRM ให้เหมาะสมกับลูกค้าแต่ละกลุ่มค่ะ 😂 — ML model ที่นิยมใช้ในการทำ Clustering คือการทำด้วยเทคนิค K-means ซึ่งจะอยู่ในประเภทของ Unsupervised Learning ค่ะ
แล้ว Dataset ที่เรามีเหมาะกับ ML model(s) หรือ RFM model กันแน่ล่ะ?
หลังจากที่เราเข้าใจความต่างในบริบทของวัตถุประสงค์ในการแบ่งกลุ่มแล้ว สิ่งเป็นคำถามก็คือ แล้วข้อมูลที่เรามีอยู่ (หรือข้อมูลที่ลูกค้าให้เรามาหา Insight^^) จะใช้ได้หรือเปล่า ตามโจทย์ที่เราตั้งไว้แต่แรกค่ะ 😎
เพราะถึงแม้ว่าเราจะ set target ไว้ชัดเจนว่าเพราะต้องการจะแบ่งกลุ่มลูกค้าตามลักษณะไหน แต่ถ้าข้อมูลที่เรามีไม่อำนวย เราก็อาจไม่ได้ Insight ตามที่ต้องการ ซึ่งระหว่าง RFM model (ซึ่งเอาไว้ทำ Segmentation) กับ ML model (K-means ที่ใช้ทำ Clustering) มีลักษณะข้อมูลที่ต้องใช้ต่างกันซึ่งมีรายละเอียดดังนี้
RFM Model
ถูกสร้างขึ้นมาเพื่อแบ่งกลุ่มลูกค้าตามพฤติกรรมการซื้อสินค้าจากแต่ละ Transaction ของลูกค้าแต่ละราย โดยตัวแปร (พฤติกรรม) ที่นำมาวิเคราะห์มี 3 มิติด้วยกัน คือ
- Recency: ระยะเวลา (จำนวนวัน) จากการซื้อครั้งล่าสุดที่ผ่านมา
- Frequency: ความถี่ในการซื้อสินค้า หรือเข้ารับบริการ หรือซื้อบ่อยแค่ไหน
- Monetary: ค่าใช้จ่ายของลูกค้า หรือมูลค่าที่ซื้อว่าจ่ายไปเท่าไหร่

โดยข้อมูลแต่ละ Transaction ของลูกค้าที่เรามักจะได้มาเพื่อทำการสร้าง RFM Model ที่สำคัญจำเป็นต้องมีเพื่อสร้างแต่ละมิติที่ต้องการวิเคราะห์ก็คือ
- Order Id (คำสั่งซื้อ)
- Order Date (วันที่ซื้อ)
- Quantity (จำนวนสินค้าที่ซื้อ), Unit Price (ราคาสินค้าต่อหน่วย) และ Sales (ยอดเงินที่ซื้อในคำสั่งซื้อนั้นๆ)
เรามาลองดูข้อมูลจาก https://www.kaggle.com/datasets/kyanyoga/sample-sales-data ซึ่งเป็นไฟล์ .csv (ซึ่งมีจำนวน 25×2823: rowsxcolumns)เพื่อให้เห็นภาพมากขึ้นกันค่ะ 😚😚
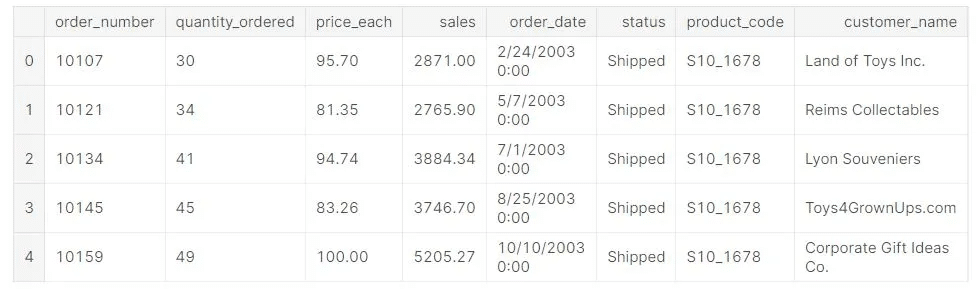
จะเห็นว่า Dataset ตัวอย่างจาก kaggle มีข้อมูลที่จำเป็นในการสร้าง Features ทั้ง R F และ M อย่างครบถ้วน โดยเริ่มแรกหลังจากที่เราได้ข้อมูลมาเราก็จะทำการ Grouping ข้อมูลของลูกค้าที่มี Customer Details เดียวกันไว้ด้วยกัน (เป็นการพิจารณาลูกค้าแต่ละราย) ก่อนจะทำการคำนวณค่า R F และ M ของลูกค้ารายนั้นๆ ออกมา โดยที่
🕑 ค่า R (Recency) คำนวณจากการนำเอาวันที่ปัจจุบันลบกับวันที่ที่มีการซื้อครั้งล่าสุด
⚡ ค่า F (Frequency) คิดจากจำนวนครั้งในการซื้อในช่วงเวลาที่เริ่มต้นพิจารณาจนถึงปัจจุบัน
💰 ค่า M (Monetary) คำนวณจากผลรวมของยอดซื้อของลูกค้ารายนั้น ซึ่งบางค่ายอาจมีการคำนวณ Basket Size (ค่าเฉลี่ยในการซื้อแต่ละครั้ง) ออกมาเพื่อประกอบการวิเคราะห์ข้อมูล
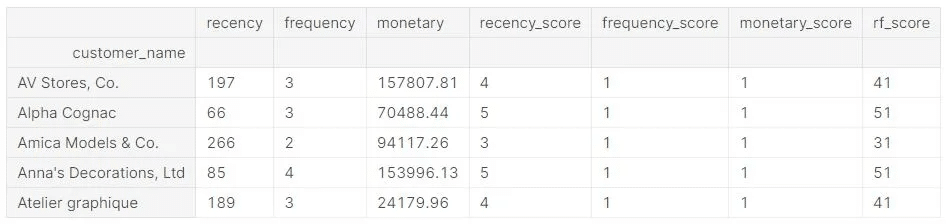
เพราะฉะนั้นสรุปว่า…ถ้าเราอยากทำ RFM Model เราจำเป็นต้องมี Order Id (คำสั่งซื้อ), Order Date (วันที่ซื้อ), Quantity (จำนวนสินค้าที่ซื้อ), Unit Price (ราคาสินค้าต่อหน่วย) และ Sales–ยอดเงินที่ซื้อในคำสั่งซื้อนั้นๆ ค่ะ😊😊
ML model: K-means Clustering
K-means เป็นเทคนิคการแบ่งกลุ่มชุดข้อมูลใดๆ แบบ Unsupervised Learning (ซึ่งหมายความว่าเราไม่มีผลลัพธ์เอาไว้ให้ ML model นั้นเรียนรู้ค่ะ) ซึ่งตัวโมเดลจะทำการจัด Cluster ให้ข้อมูลของลูกค้าที่มีความใกล้เคียงกันอยู่กลุ่มเดียวกัน
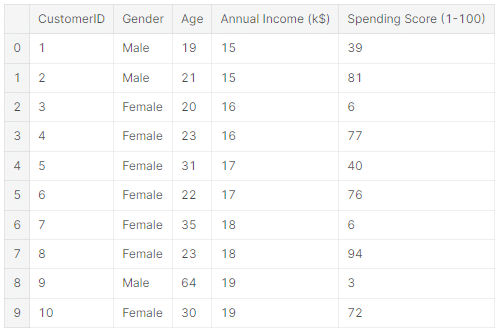
หมายความว่าเราจะสามารถ Input ข้อมูลที่อื่นๆ เพิ่มเติมจากที่ RFM Model (ทั้งค่า R F และ M score) ให้กับ K-means model ได้ยกตัวอย่างตามภาพด้านล่างนี้ได้ ซึ่งมีการเพิ่ม Feature อายุ, เพศ, รายได้, และคะแนนการจับจ่าย มาใส่เป็น Input เพิ่มให้กับตัว K-means ค่ะ
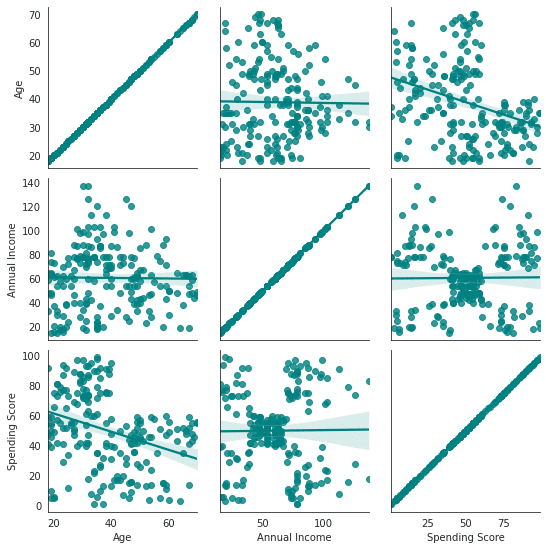
but, waitttt…. ใช่ว่าการที่เราโยนทุกสิ่งอย่างให้ K-means model จะเป็นสิ่งที่ดี เพราะข้อมูลบางข้อมูลก็ไม่ได้มี Correlation กับกลุ่มลูกค้าที่เราอยากจัดกลุ่มค่ะ เพราะฉะนั้นข้อสำคัญสำหรับ K-means ก็คือการหา Features ที่เหมาะสมที่จะส่งให้ model โดยการหา Correlation ของข้อมูล โดยการ plot เป็นกราฟออกมา หรือวิธีที่นิยมใช้คำนวณก็จะเป็นการทำ Pearson correlation ซึ่งจะคำนวณความสัมพันธ์ของชุดข้อมูลออกมาเป็นตัวเลข (ระหว่างค่า -1 ถึง 1) เราก็มีหน้าที่ในการเลือก Features ที่มี Strong correlation ไม่ว่าจะเป็นด้าน Positive หรือ Negative มาใช้งาน
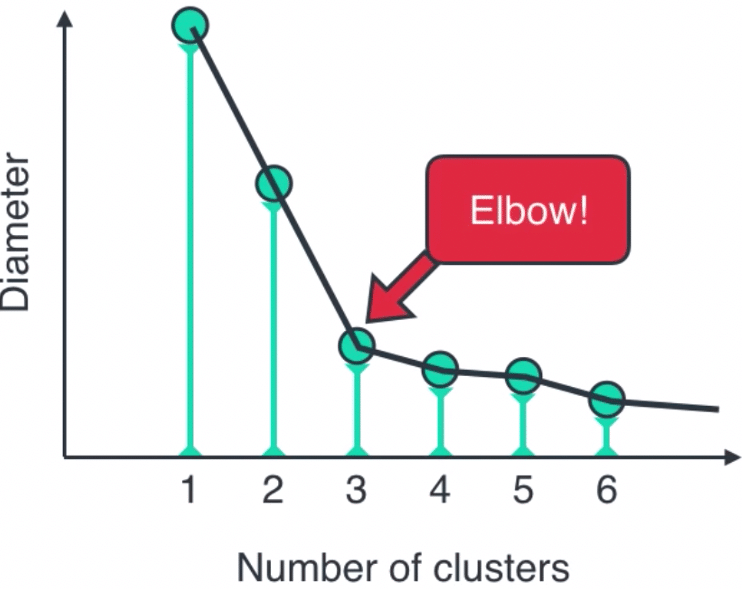
นอกจากนี้จำนวนของ Clusters หรือจำนวนกลุ่มลูกค้าที่เราต้องการให้ K-means จัดกลุ่มออกมาก็มีความสำคัญเช่นเดียวกัน ซึ่งวิธีที่เหมาะสมที่จะใช้ประเมินจำนวนกลุ่มที่ควรเป็นสำหรับชุดข้อมูลนั้นๆ คือ Elbow method 🙂แต่ถ้าเราอยากเปรียบเทียบวิธีการแบ่งกลุ่มลูกค้าระหว่าง RFM Segmetation กับ K-means ให้เราลอง set จำนวนกลุ่มที่ต้องการให้เท่ากับจำนวนกลุ่มที่เราให้ RFM จัดให้ (เช่นอาจ set เป็น 11 กลุ่มตามที่หลายๆ ค่าย นิยมกันค่ะ)
ดังนั้นสรุปว่า…สำหรับ K-means Model เราสามารถใส่ข้อมูลได้หลากหลายมากกว่า RFM ไม่ว่าจะเป็น คำสั่งซื้อ, วันที่ซื้อ, รายละเอียดสินค้าที่ซื้อพร้อมกัน, Customer Details อื่นๆ เช่น เพศ, อายุ, รายได้, ที่อยู่, จำนวนสมาชิกในครอบครัว, การศึกษา บลาๆๆ ของลูกค้ารายนั้นเพิ่มเติมได้ตราบเท่าที่ข้อมูลนั้นมี ค่ะ😊😊
มาลองทำ Customer Segmentation Model กันค่ะ^^
😊 และแล้วก็ถึงเวลาที่เรารอคอย หลังจากที่เราเลือกได้ว่าเราจะใช้โมเดลอะไรกับกลุ่มลูกค้าของเรา ได้เวลามาลองทำ Customer Segmentation กัน โดยในส่วนของบทความนี้จะขอเริ่มจาก RFM Model (พาร์ทของ K-means ขอแยกย่อยไปอีกหนึ่งบทความนะคะ^^)
Let’s go!! เมื่อเราได้ค่า RF และ M score ของลูกค้าทุกรายออกมาจากพาร์ทก่อนหน้า เราจะมาให้คะแนนในแต่ละด้าน และทำการจัดเรียงลำดับข้อมูลตามค่า R F และ M ใหม่ ดังนี้
[Recency] เรียงจากน้อยไปมาก [Frequency และ Monetary] เรียงจากมากไปน้อย
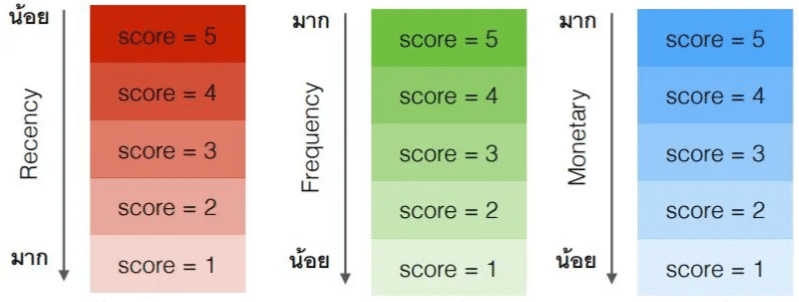
เมื่อเราเรียงชุดข้อมูลเสร็จ ก็เข้าสู่การคำนวณค่าคะแนน RFM ของแต่ละกลุ่ม โดยการแบ่งข้อมูลที่ทำการเรียงแล้วเป็นส่วนๆ (ส่วนละเท่ากัน) ซึ่งตรงนี้เองอาจจะให้คะแนนเป็น 1–3, 1–4 หรือ 1–5 ก็ได้ (แล้วแต่ค่าย) โดยลูกค้าที่ถูกจัดเรียงใหม่ตามหลักเกณฑ์ดังกล่าว จะมีค่าคะแนนของ RFM ตามกลุ่มที่ลูกค้าอยู่ค่ะ^^
� � ป.ล. ในบทความนี้จะใช้การแบ่งข้อมูลออกเป็น 5 ส่วนเท่าๆ กัน (Quintile)
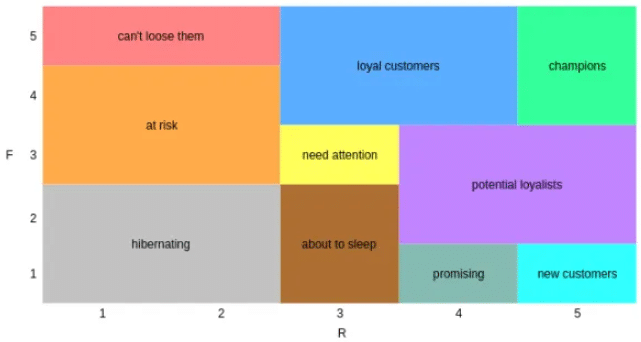
Customer Segmentation: แบ่งลูกค้าเป็น 11 กลุ่ม ด้วย RFM score🧬🧬
โดยการทำ Customer Segment นั้นสามารถทำได้หลากหลายแบบมากๆ เช่น สามารถแบ่งกลุ่มเป็น Champions, Loyal Customer, New Customers, etc. ซึ่งก็สามารถเลือกได้ตามความเหมาะสมของประเภทสินค้า หรือบริการของตนเองได้เลย
ซึ่งไม่ว่าจะใช้ลักษณะการแบ่งกลุ่มลูกค้าแบบใดก็ตาม ต่างก็มีหลักการคิดคล้ายๆ กัน เช่น
- ลูกค้ากลุ่ม RFM = 555 เป็นกลุ่มลูกค้าที่มีค่ามากที่สุด (มักถูกเรียกว่า Champions)
- ลูกค้ากลุ่ม 551 เป็นลูกค้าที่มีการซื้อบ่อย แต่ซื้อในปริมาณไม่มาก (บางค่ายเรียกลูกค้ากลุ่มนี้ว่า Loyal Customer) ซึ่งควรออก Campaign ที่เหมาะสมเพื่อกระตุ้นการซื้อ ให้ลูกค้ากลุ่มนี้ซื้อสินค้าที่มีราคาสูงขึ้น
- ลูกค้ากลุ่ม 115 เป็นกลุ่มลูกค้าที่ซื้อสินค้าที่มีราคาสูง แต่นานๆ ทีถึงจะซึ้อหนึ่งครั้ง ซึ่งสามารถออก Campaign ให้ซื้อสินค้าบ่อยขึ้นได้
ซึ่งจากข้อมูลของ https://www.kaggle.com/datasets/kyanyoga/sample-sales-data ที่เราลองนำมาวิเคราะห์กัน ก็ได้ข้อสรุปของตัวเลขเชิงสถิติ ดังนี้
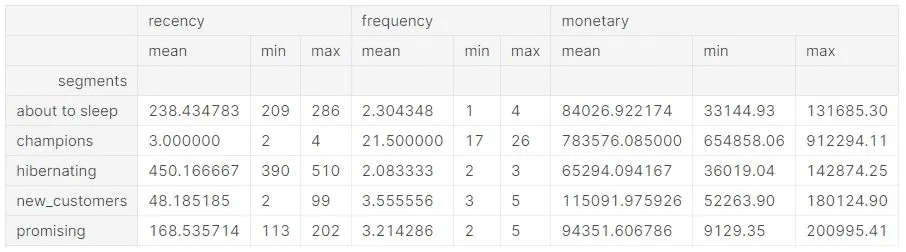
เลือกกิจกรรม CRM ให้เหมาะกับกลุ่มลูกค้า
คำถามที่น่าสนใจที่สุดหลังจากการทำ Customer Segmentation สำเร็จแล้ว คือ แล้วการทำ CRM (Customer Relationship Management) แบบไหนล่ะ ที่จะเหมาะกับกลุ่มลูกค้าที่เราแบ่งออกมาแต่ละประเภท เพื่อเพิ่มยอดขาย ถึงจะถือว่าเป็นการ(เกือบ)จบกระบวนการของการทำ Customer Segmentation—คหสต. นิกคิดว่าควรมีการเก็บ Feedback หลังจากทำกิจกรรม CRM ด้วย เพื่อทั้งวิเคราะห์ว่า Segments ของลูกค้าที่เราแบ่งมา และกิจกรรมส่งเสริมการขายที่เรา provide ให้ลูกค้ามีความเหมาะสมสอดคล้องกันหรือไม่ค่ะ
โดยในบทความนี้จะขอยกตัวอย่างการทำ CRM แบ่งตามประเภทลูกค้าออกเป็น 11 กลุ่มหลัก และ CRM ที่เหมาะสมกับแต่ละกลุ่ม ดังนี้ 😏😏
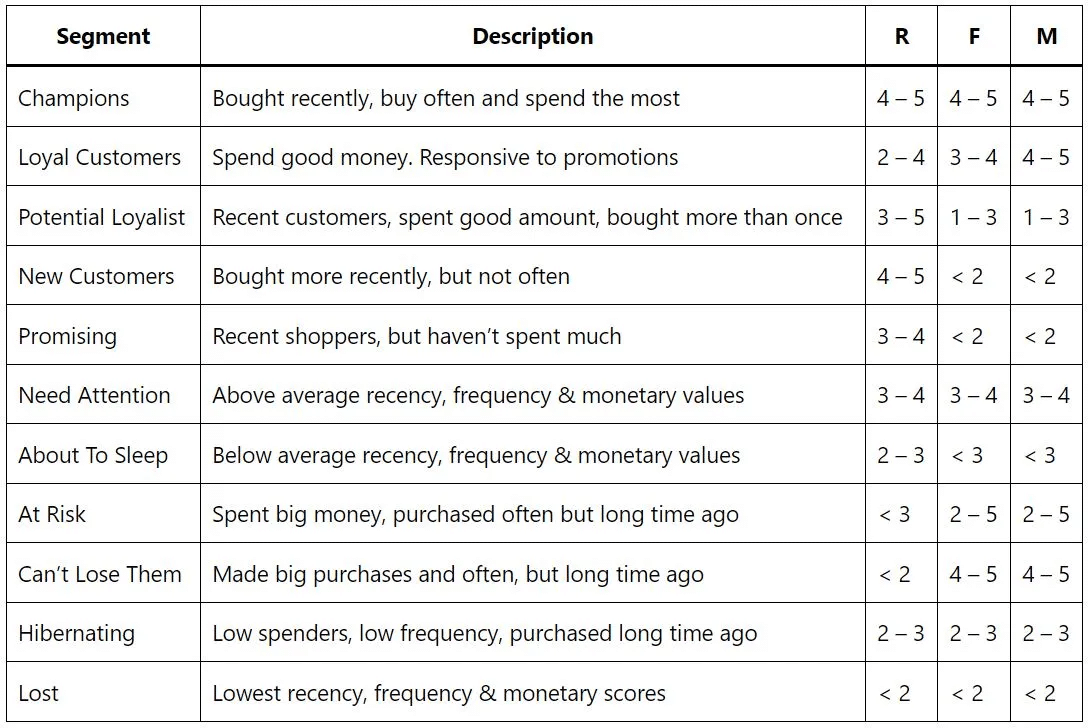
- Champions: สุดยอดลูกค้า ดีสุดในทุกด้าน ถือเป็นกลุ่มลูกค้าที่เราควรรักษาไว้ให้ได้ โดยการออก Campaigns พิเศษ และการทำการตลาดแบบเฉพาะกลุ่มบุคคล (Personalize)
- Loyal Customers: เคยสุดยอด แต่ไม่ซื้อนานแล้ว ทำให้เราควรเน้น Promotions ที่กระตุ้นการซื้อให้เพิ่มขึ้น หรือให้สินค้าทดลองเพื่อให้ซื้อสินค้าที่ดีขึ้น หรือมีราคามากขึ้น
- Potential Loyalist: ลูกค้าค่อนข้างใหม่ จ่ายเยอะ ซื้อมากกว่า 1 ครั้ง กลุ่มนี้หลังจากที่มีการซื้อสินค้า ให้รีบทำการติดต่อกลับทันที เพื่อให้ความสำคัญ และเก็บข้อมูลเพื่อเสนอขายสินค้าที่ตรงกับความต้องการเพื่อกระตุ้นการซื้อได้
- New Customers: ลูกค้าใหม่ เพิ่งมาซื้อ จ่ายน้อย ให้ติดต่อกลับไปเพื่อให้บริการหลังการขาย หรือส่งข้อมูลที่เป็นประโยชน์ต่อการใช้สินค้าได้อย่างเหมาะสมมากยิ่งขึ้น
- Promising: ลูกค้านานๆ มาที แต่กลับมาอยู่นะ ซื้อจางๆ ต้องกระตุ้นด้วยการทำระบบสมาชิก เพื่อดึงมาเป็น Loyal Customers
- Need Attention: นานๆ มาที แต่กลับมาแล้ว มาแล้วมาถี่ จ่ายเยอะ ซึ่งเราสามารถส่งข้อมูลผ่านช่องทางติดต่อที่ลูกค้ากลุ่มนี้ให้ไว้เพื่อดึงให้กลับมาซื้อ โดยส่งข้อมูลของสินค้าที่ลูกค้าเคยซื้อ หรือสินค้าใกล้เคียง เพื่อแสดงความใส่ใจ หรือเสนอส่วนลดแบบมีกรอบเวลา เพื่อให้กลับมาในช่วงเวลาที่ตั้งกรอบไว้
- About to Sleep: หายไปนานแล้ว แต่เคยซื้อบ่อยด้วย เยอะด้วย ให้ติดต่อกลับไปบ้างเพื่อเสนอโปรโมชั่น และสินค้าใหม่
- At Risk: เคยซื้อเยอะ แต่หายไปนานมากกกแล้ว รายนี้ต้อง Contact ด่วนๆ เลย ไม่งั้นหายไปเลยแน่ โดยอาจจะส่งข้อมูลสินค้าที่เป็นที่นิยมในปัจจุบัน พร้อมโปรโมชั่น เผื่อเขาจะกลับมา
- Can’t Lose Them: เคยซื้อเยอะบ่อยๆ แต่ไม่ซื้อนานแล้ว ควรติดต่อไปโดยตรงเพื่อให้ความสำคัญ พร้อมกับส่ง Promotions พิเศษไปให้
- Hibernating: ซึ่งน้อย ไม่บ่อย ไม่ซื้อนานแล้ว
- Lost: น้อยทุกด้าน
โดยลูกค้า 2 กลุ่มท้ายอาจจะต้องวัดใจ ให้ Promotion แรงๆ เพื่อกระตุ้นให้เขากลับมาซื้อ แต่ถ้าเขาไม่กลับมาก็คงต้องทำใจ และสำรวจข้อบกพร่องของผลิตภัณฑ์ หรือคู่แข่ง
Last but not Least
ทั้งนี้การทำ RFM Model เป็นอีกหนึ่งในกระบวนการการทำ Customer Segmentation ในการทำ CRM ที่ค่อนข้างมีประสิทธิภาพ โดยทั้ง RFM segmentation และ K-means clustering สามารถประยุกต์ใช้ร่วมกันโดยการ นำค่า R F M และ Basket Size มาเป็นตัวแปร (Features) ในการสร้าง Model เพื่อวิเคราะห์แบบ Macro Cross Segmentation ต่อไปได้^^
และสามารถติดตามอ่านบทความที่เกี่ยวข้องกับ RFM Customer Segmetation ได้ดังนี้ค่ะ>



%20หรือ%20RFM:%20Customer%20Segmentation%20ข้อมูลนี้ใช้โมเดลอะไรดี?){kind=link}