ทำความรู้จัก LLMs: แบบจำลองภาษาขนาดใหญ่ เทคโนโลยีเบื้องหลัง AI ChatGPT

ในบทความนี้เราจะไปทำความรู้จักกับ Large Language Models หรือ LLMs ซึ่งถือเป็น Algoritms สำคัญเบื้องหลังแพลตฟอร์ม AI สุดฮอตในช่วงนี้อย่าง ChatGPT, Microsoft’s Bing และ Google’s Bard พร้อมสำรวจว่าในตอนนี้มีแบบจำลองภาษา หรือ Language Models ไหนบ้างเป็นผู้นำแห่งยุคที่เราควรรู้เพื่อความเพิ่มความเข้าใจ และเพิ่มประสิทธิภาพในการใช้งาน platform ล้ำๆ ที่มีอยู่ในปัจจุบันค่ะ (*/ω\*)
ป.ล. บทความอาจมีหลายพาร์ทนะคะ เนื่องจาก details เรื่องนี้ยุบยับแบบจริงจัง^^
LLMs คืออะไร?
Large Language Models ที่มีชื่อเล่นสั้นๆ ว่า LLMs เป็นโมเดล baesd-on โครงสร้างแบบ Nueral network ที่มีองค์ประกอบสำคัญชื่อว่า “Transformer” โดยตัว Transformer เนี่ยเป็นเทคนิคที่ถูกพัฒนาขึ้นมาโดย Google ในปี 2017 เพื่อใช้ในการแปลความหมายของข้อความจากฝั่ง Source ไปเป็นข้อความในฝั่ง Target ผ่านโมเดล 2 โมเดลคือ Encoder และ Decoder
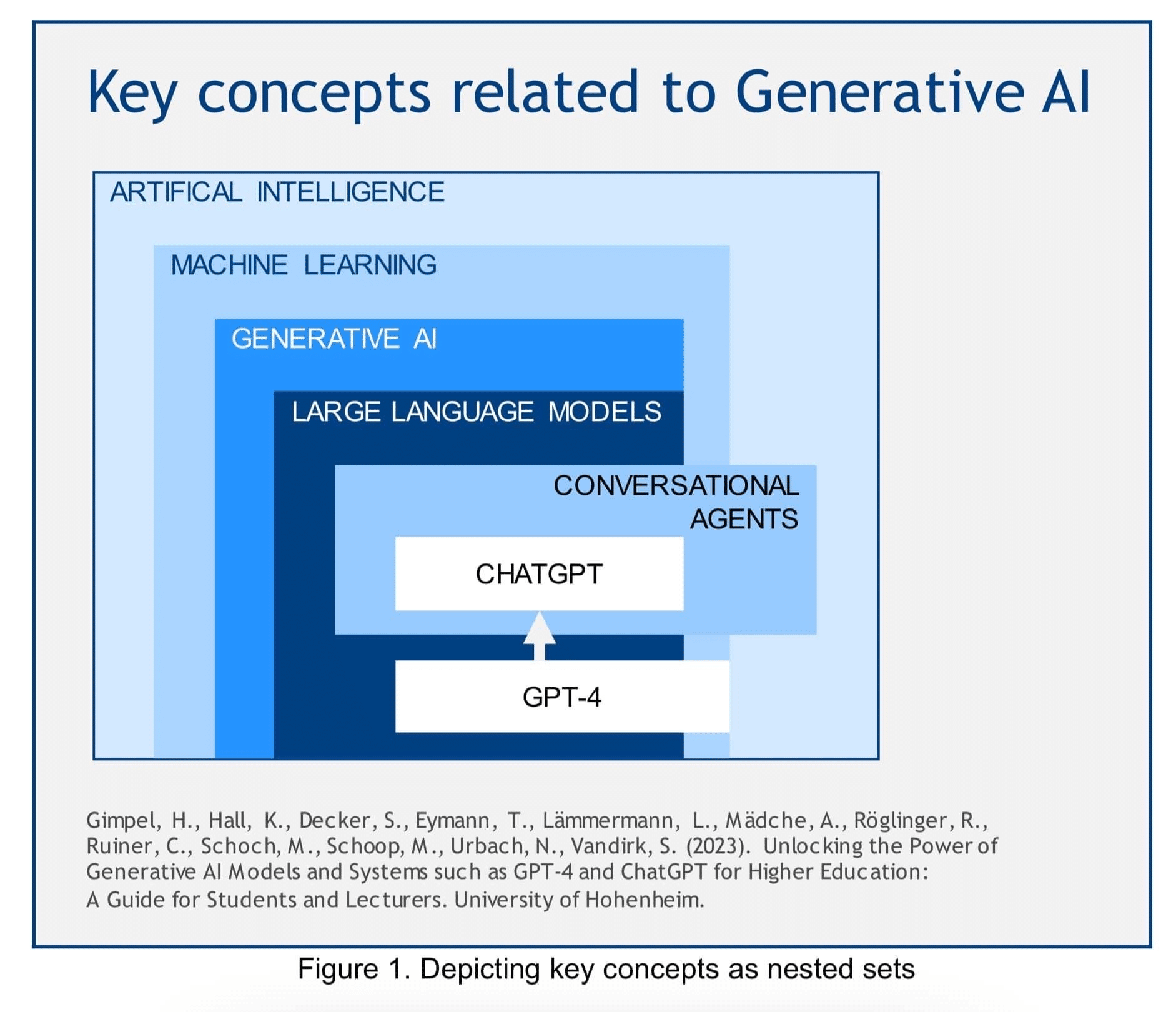
โดยหากพิจารณาจากภาพด้านบนจะเห็นว่า LLMs ถือเป็น Generative AI ประเภทหนึ่ง (link บทความเรื่อง Generative AI นิกจะแปะไว้ด้านล่างนะคะ^^) ซึ่งเป็นสับเซตของ Machine Learing โดยทั้งหมดทั้งมวลก็คือ AI หรือปัญญาประดิษฐ์ที่มนุษย์สร้างขึ้นเพื่อให้คอมพิวเตอร์หรือเครื่องจักรสามารถทำงาน ประมวลผลสิ่งต่างๆ ได้ใกล้เคียงกับมนุษย์ค่ะ
แล้วอะไรคือที่มาของคำว่า “Large” ต้องแบบไหนถึงจะเรียกว่าใหญ่?
=> กลับมาที่เรื่องของ Transformer Model ซึ่งเป็นองค์ประกอบหลักของ LLMs กันค่ะ โดยเจ้าตัว Transformer เนี่ยที่แท้จริงแล้วคือกระบวนการแปลภาษาโดยใช้คอมพิวเตอร์ (Machine Translation) ที่มีหัวใจสำคัญของกระบวนการคือการ เปลี่ยนประโยคภาษาอะไรก็ตามที่รับเข้ามา (source) จากภาษาหนึ่งไปยังอีกภาษาหนึ่งที่เราต้องการ (target) ให้มีความหมายไม่เปลี่ยนแปลงไปจากเดิม ซึ่งใช้หลักการของ sequence-to-sequence model (หรือมีอีกชื่อว่า encoder-decoder model) ซึ่งสิ่งที่ Transformer ทำก็คือการมองหา 2 อย่างได้แก่ การเกิดขึ้นคู่กันของคำ (word collocations) และโครงสร้างของประโยค (phase structer) โดยตัว Transformer model แบบ sequence-to-sequence จะประกอบไปด้วย 2 โมเดลย่อยคือ
- Encoder: ใช้ในการแปลงประโยค source ไปเป็นรหัสระหว่างกลางหรือรหัสชั่วคราว (intermediate representation) โดยการเข้ารหัสทั้งประโยคในเชิง phase structer และเชิงความคล้ายคลึงของคำ (samantic similarity) => ซึ่งถึงตรงนี้เราจะได้ตัวเลขที่น่ารักน่าเอ็นดู(มั้ย)ออกมาค่ะ
- Decoder: ใช้แปลงรหัสชั่วคราวที่ได้รับจาก encoder ให้คืนค่าเป็นประโยคในภาษาที่เป็น target ╰(*°▽°*)╯
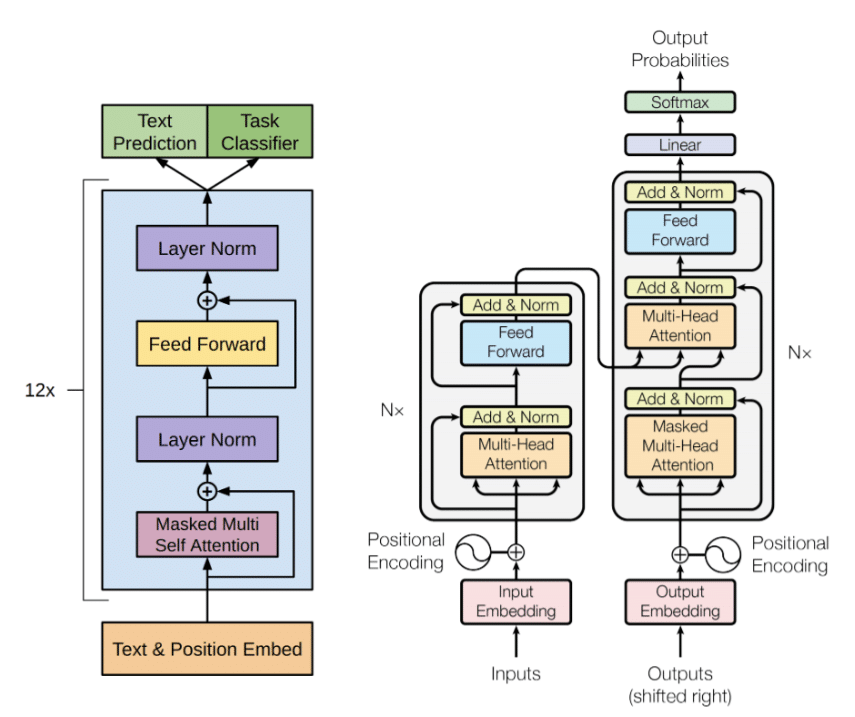
ซึ่ง AI ที่อยู่เบื้องหลังทั้ง Encoder และ Decoder model ก็คือ Deep Learning Nueral Network ซึ่งความใหญ่ที่ว่านี้ คือความเยอะของจำนวน nuerouns ที่อยู่ในแต่ละชั้น (layers) ของตัวโมเดล ซึ่งในแต่ละ nueron ก็จะประกอบไปด้วยสมการทางคณิตศาสตร์ ที่จะสร้าง weight เพื่อส่งให้กับ nuerons อื่นซึ่งก็คือ parameters ค่ะ โดยความ “Large” ของ ChatGPT (gpt-3.5-turbo) คือมีจำนวน parameters เท่ากับ 175 พันล้าน parameters (แต่เยอะขนาดนี้ก็ยังไม่เท่าสมองของมนุษย์อยู่ดีนะคะ😏😁 )
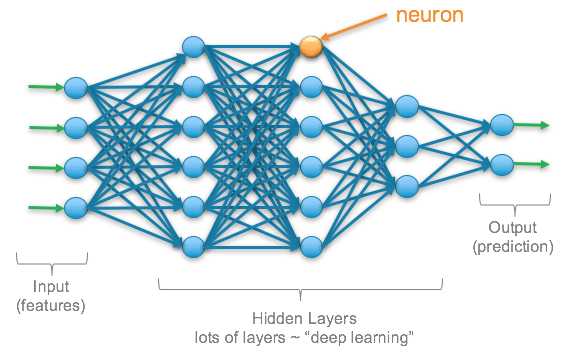
ซึ่งข้างในยังมี Algorithms ต่างๆ เช่น Self-Attention ที่จะเลือกแปลคำแต่ละคำ โดยเป็นการวัดค่าความคล้ายคลึงกันของคำ (related context) และมีความสำคัญ (มีค่า weight เยอะ) เป็นต้น =>และในส่วนของรายละเอียดยุบยับต่างๆ นิกขออนุญาตตัดตอนไปเขียนไปบทความต่อไปนะคะ (^///^)
เพราะในส่วนต่อไปของบทความนิกขอเกริ่นให้ทุกท่านรู้จักกับ Language Models 10 โมเดลเทพๆ ที่อยู่เบื้องหลังแบบจำลองภาษาทั้งหลายค่ะ^^
10 Language Models ทรงพลังที่ควรทำความรู้จัก 😎
LLMs เป็นงานวิจัยที่มีการพัฒนามาอย่างต่อเนื่อง ทำให้มีโมเดลใหม่ๆ ที่มีประสิทธิภาพสูงขึ้นถูกปล่อยออกมาอย่างต่อเนื่องซึ่งทาง topbots.com ได้ทำการคัดเลือกออกมา 10 โมเดลที่น่าจะทำความรู้จักกันดังนี้ค่ะ
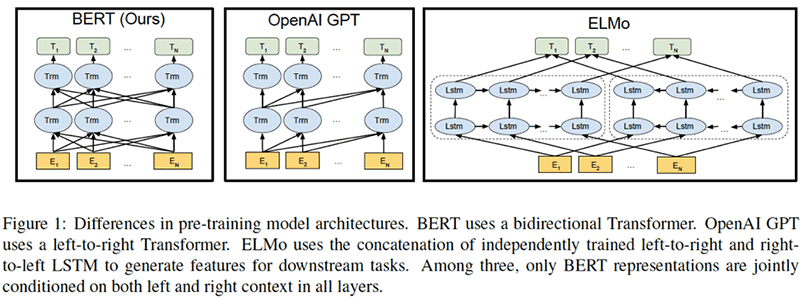
- BERT: เป็นโมเดลแปลภาษาแบบ Pre-training โมเดลที่ใช้โครงสร้าง Transformer แบบ Bidirectional
- GPT2: เป็น Language Models แบบ Unsupervised Multitask Learners
- XLNet: เป็น autoregrissive model สำหรับ language modeling ที่จะสร้างลำดับการ predict ขึ้นมาใหม่ แทนที่จะเรียงลำดับการพิจาณาคำ (token) จากลำดับ 1-2-3-4
- RoBERTa: ถูกสร้างขึ้นมาเพื่อให้ BERT สามารถทายคำต่อไปได้เทพขึ้นเรื่อยๆ
- ALBERT: ALBERT (ตระกูล BERT ล่าสุด) จาก Google ที่มีขนาดเล็กกว่า BERT เกือบสิบเท่า แต่มีประสิทธิภาพใกล้เคียงกัน
- T5: เป็นกลุ่ม Transformer แบบ sequence-to-sequence เช่นเดียวกับ BERT แต่จะเป็น Unified Text-to-Text Transformer ที่ถูกเทรนมาแล้ว
- GPT3: โมเดล GPT-2 ที่ใหญ่ขึ้นไปอีกซึ่งสามารถทำงานได้หลายอย่างโดยไม่ต้องการการ fine-tune หรือที่เรียกว่า Few-Shot Learners
- ELECTRA: เป็น BERT จากทีม Google ที่ออกแบบวิธีการ pre-training ให้พัฒนาจาก BERT ซึ่งตัว text encoders จะทำหน้าที่เป็น discriminators มากกกว่า generators
- DeBERTa: พัฒนาการ decoding ของ BERT ด้วยการทำ Disentangled Attention
- PaLM: เป็น Pathways สำหรับ LLMs เพื่อให้ใช้กับอุตสาหกรรมและเทคโนโลยีอื่นได้
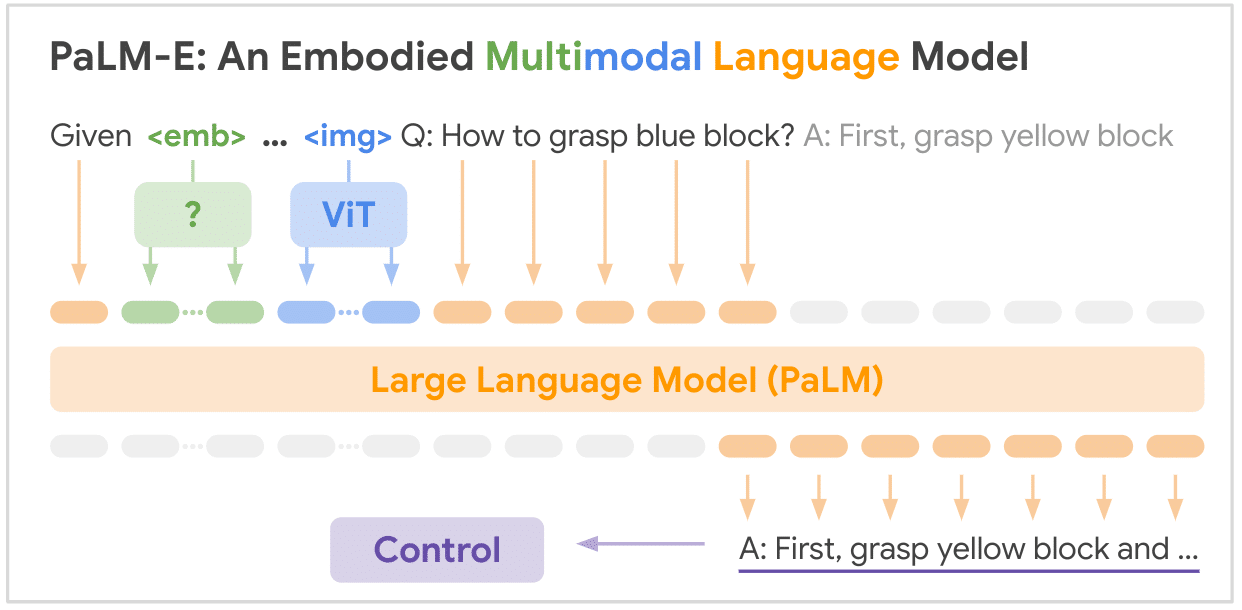

Last but not Least,,,
สรุปว่า….ในบทความนี้เพื่อนๆ ชาวการตลาดวันละตอนจะได้ทำความรู้จักในเบื้องต้นกับ LLMs ซึ่งมีกระบวนการข้างในยิบย่อย ยุบยับ เพื่อที่จะสามารถสร้างความเข้าใจและทราบ Keywords ตลอดจนหลักการทำงานของโมเดลรูปแบบต่างๆ โดยเฉพาะ Chatbot สุดฮอตแห่งยุคอย่าง ChatGPT (ซึ่งเกิดจากการสอนให้ BERT รู้จักสร้างคำออกมา) ซึ่งรายละเอียดต่างๆ เพิ่มเติมของแต่ละโมเดล สามารถติดตามได้ในบทความ part ต่อไปนะคะ
ป.ล. แอบกระซิบว่าสำหรับบทความต่อไปจะมีในส่วนของการพาทุกคนสร้าง Linebot ที่มีการนำเอา ChatGPT ไปช่วยตอบคำถามให้ลูกค้าของเราค่ะ^^
คลาสเรียนออนไลน์ Social Listening Analytics รุ่นที่ 20 วันศุกร์ที่ 19 พฤษภาคม 2023 ค่าเรียนคนละ 9,900 รับจำกัด 20 คน อ่านรายละเอียดและลงทะเบียนได้ที่ลิงก์นี้ค่ะ https://bit.ly/sociallistening20




{kind=link}