ข้อมูลนี้สำคัญ เป็น Anomalies data หรือแค่ Outlier

เมื่อเราได้ชุดข้อมูลที่น่าสนใจมาเพื่อทำการวิเคราะห์การตลาดในหัวข้อใดๆ ก็ตาม ขั้นตอนหนึ่งที่ถือว่าใช้เวลานานที่สุดคือส่วนของการเตรียมข้อมูล โดยในขั้นตอนนี้มักจะมีข้อมูลที่ไม่เข้าพวก หรือเป็นแกะดำกระโดดออกมาด้วยเสมอๆ คำถามที่น่าสนใจคือ => แล้วแกะดำพวกนี้มีความสำคัญ เป็น Anomailes data ที่ควร focus หรือเป็นแค่ Outlier Anomaly ของชุดข้อมูลที่ต้องทำการตัดออกเท่านั้น
โดยก่อนที่เราจะมามองหาบรรดาเหล่าแกะดำทั้งหลาย สิ่งที่จะต้องทำก็คือการจัดกลุ่มข้อมูล เพื่อดูลักษณะการกระจายตัวของข้อมูล (หรือการแจกแจงของข้อมูล) ก่อนการเขียนกฎเพื่อแยกแยะแกะดำออกจากพวกค่ะ

การกระจายตัวของข้อมูล
การกระจายตัวของข้อมูล (Data Distribution) หรือการแจกแจงข้อมูล (คำศัพท์เชิงสถิติ) มีอยู่หลายรูปแบบตัวด้วยกัน แต่รูปแบบที่เจอเป็นปกติตามธรรมชาติของชุดข้อมูลใดๆ มักจะมีหน้าตาคล้ายๆ กับรูประฆังคว่ำ (Bell-Shape) ที่ถูกเรียกว่าการกระจายตัวแบบปกติ หรือ Normal Distribution หรืออีกชื่อคือ Guassian Distribution ค่ะ
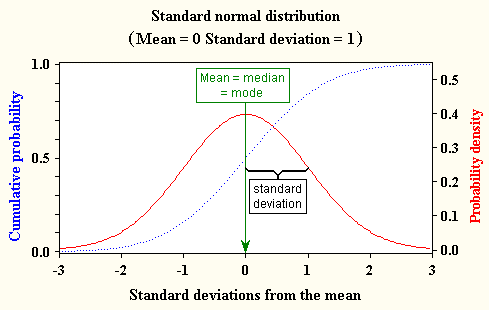
หลังจากที่เราได้กราฟการกระจายตัวของข้อมูลออกมาแล้ว และทำการจัดกลุ่มข้อมูลเพื่อมองหาความน่าจะเป็นที่เกิดขึ้นของข้อมูลแต่ละตัวจะเข้าสู่การพิจารณาค่ะว่า ข้อมูลแกะดำนั้น เป็น Outlier ที่ต้องตัดออก หรือเป็น Anomalies data ที่ต้องมาหา Insight เพิ่ม 😃😊
Anomalies และ Anomaly Detection
Anomalies data คือ”ชุดข้อมูล”ที่มีตำแหน่งของข้อมูล (เมื่อนำมาพล็อตกราฟ) อยู่นอกเหนือจากกลุ่มที่ควรจะเป็นเมื่อเทียบกับข้อมูลอื่นๆ นอกจากนี้ยังมีการกระจายตัวของข้อมูลที่แปลกออกมาจากการกระจายตัวปกติ โดยความแปลกนั้นเป็นสิ่งที่มีนัยสำคัญ และเป็นจุดที่ต้องทำการ Focus หรือพูดง่ายๆ ว่าคือเด็กพิเศษที่เราต้องสนใจและจัดการค่ะ^^
🐑 ซึ่งปกติแล้วลักษณะของข้อมูลแบบ Anomaly มักจะเกิดเมื่อชุดข้อมูลนั้นมีกลุ่มของการกระจายตัวของข้อมูลมากกว่า 1 กลุ่ม โดยกลุ่มที่มีความผิดปกติจากกลุ่มอื่นคือชุดของข้อมูลที่เป็นแกะดำ หรือ Anomalies ดังภาพด้านล่าง
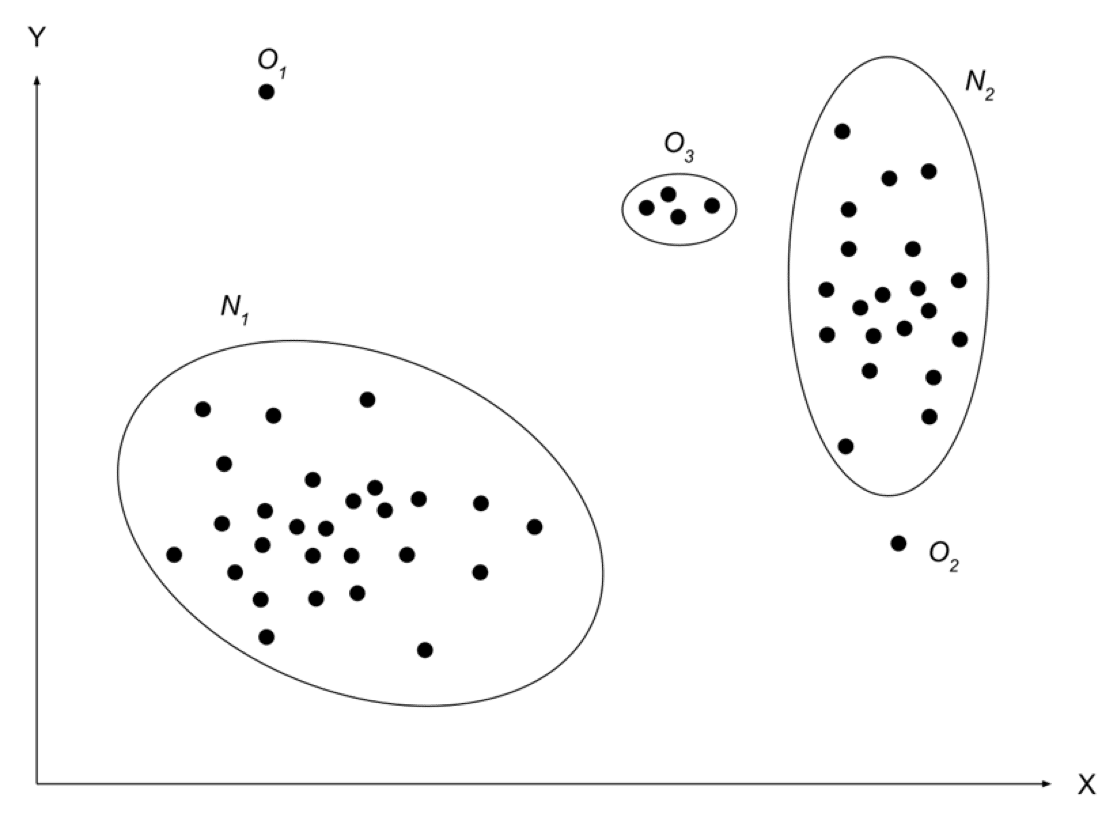
🐑 โดยน้องแกะดำของเราเป็นข้อมูลที่สามารถหาที่มาที่ไปได้ค่ะ ว่าทำไมแกะเหล่านั้นถึงมีความไม่ปกติ เช่นเป็นลักษณะของการละเมิดใช้บัตรเครดิต (Credit card fraud), การที่ลูกค้าใช้บัญชีอื่นสั่งสินค้า, การเปลี่ยนแปลงพฤติกรรมการซื้อที่มีสาเหตุมาจากปัจจัยที่เปลี่ยนไปอย่างทันทีทันใด เช่นการย้ายบ้าน หรือการตั้งครรภ์ หรือเจ็บป่วยฉุกเฉิน หรืออาจเกิดขึ้นได้จากกรณีที่เรามีการจัดโปรโมชั่นของสินค้าบางอย่างในร้านค่ะ
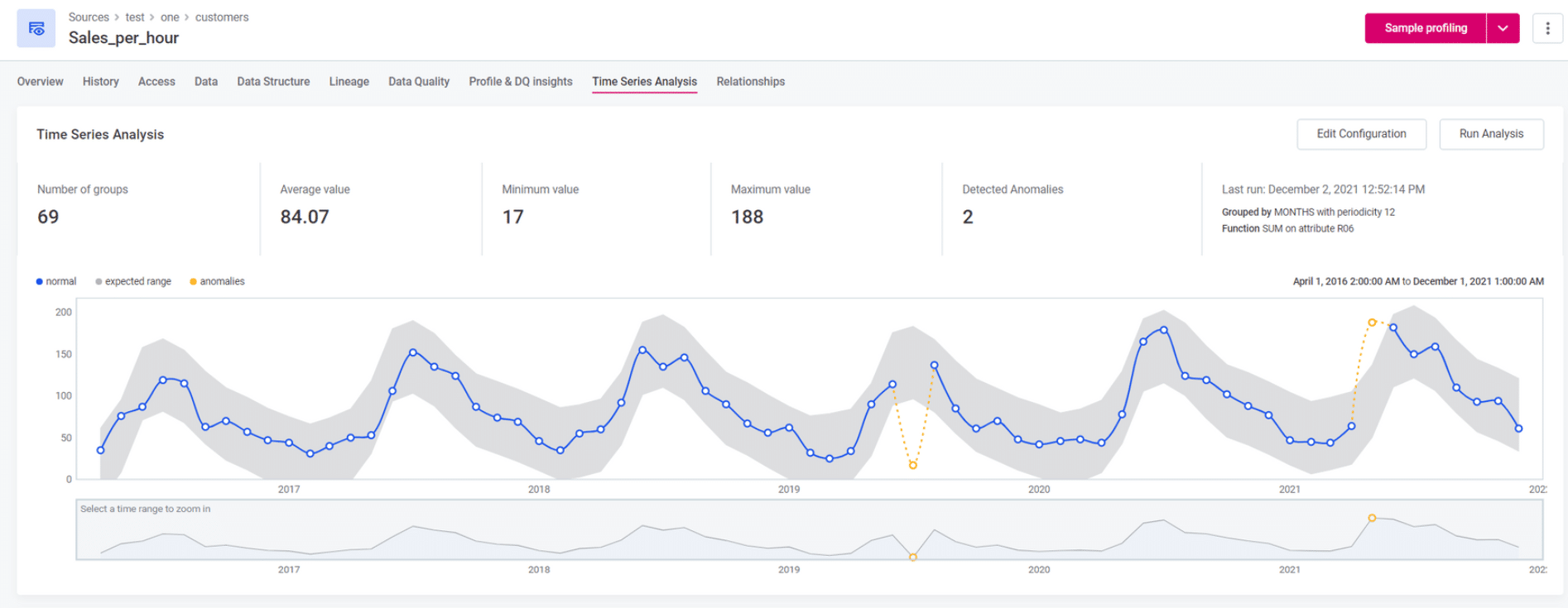
ยกตัวอย่างจากภาพด้านล่างที่มีการเก็บข้อมูลขอดขายรายชั่วโมงของทุกวัน ซึ่งข้อมูลประเภทนี้ถูกเรียกว่า Time series data ที่มักจะมีรูปแบบในแต่ละวัน/แต่ละช่วงเวลาเป็น Pattern ที่ค่อนข้างชัดเจน เช่นเราอาจจะเจอว่ายอดขายของวันจันทร์ ต่างจากยอดขายวันอังคาร หรือยอดขายวันศุกร์มีค่ามากกว่าวันอื่นๆ เป็นต้น แต่ในความเป็น Pattern ของยอดขาย กับมีบางช่วงเวลาที่มียอดขายผิดปกติไป (จุดสีเหลืองตามภาพด้านล่างค่ะ^^) ทั้งลดลงแบบผิดปกติ และเพิ่มขึ้นแบบผิดปกติ ซึ่งพบว่าเกิดจากการทำโปรโมชั่น และเหตุการณ์บางอย่างที่กระทบยอดขายค่ะ
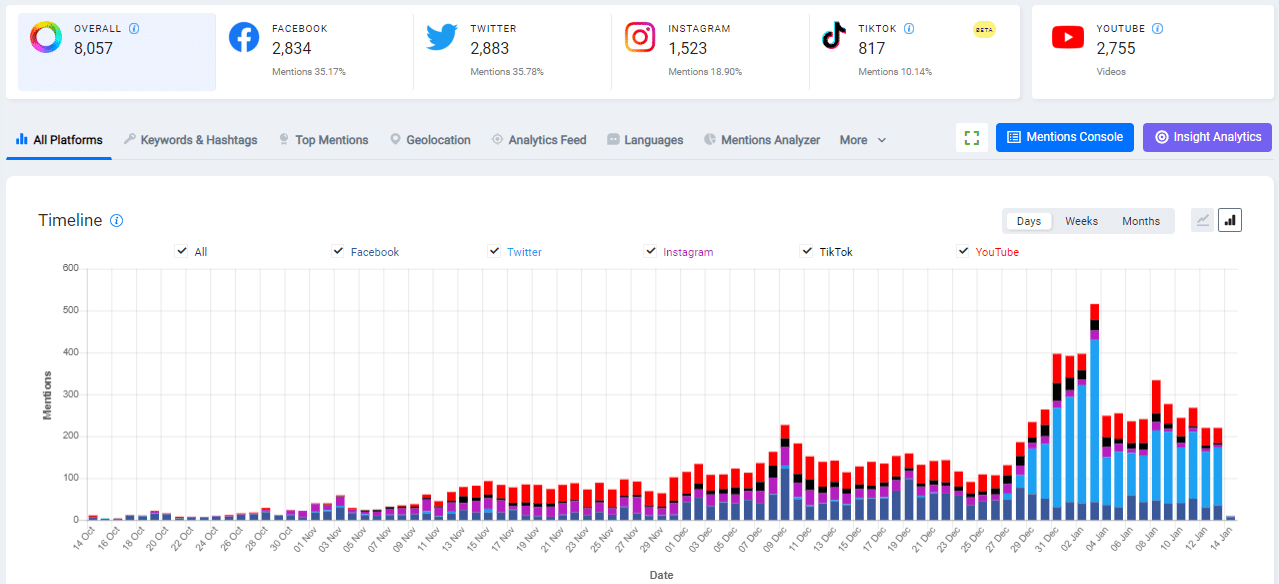
หรือในกรณีที่เราทำ Social Listening ส่วนของ Anomalies (นอกเหนือจากการวิเคราะห์ตาม Season แบบ Time sereis data นะคะ) หลายเหตุการณ์เกิดจากการถูกกล่าวถึงโดย Influencer ในช่วงเวลานั้นๆ ซึ่งทำให้มีจำนวน Mentions และ Engagement ที่สูงขึ้นตามไปด้วยค่ะ
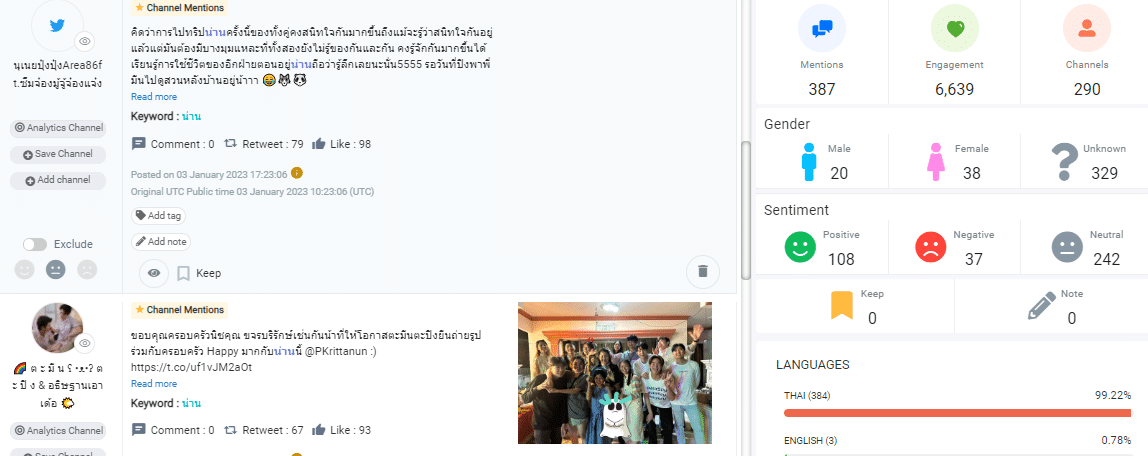
ทำให้ข้อมูลที่เป็น Anomalies คือข้อมูลที่ต้องนำมาวิเคราะห์หาสาเหตุ และปัจจัยเชื่อมโยง แทนที่จะตัดข้อมูลชุดนั้นออก เนื่องจากการละเลยไม่พิจารณาข้อมูลที่เป็น Anomalies อาจก่อให้เกิดความเสียหายกับลูกค้าได้ (กรณีมาจากการละเมิดใช้บัตรเครดิต) หรือ Anomalies กลุ่มนั้นอาจสามารถเป็นกลุ่มเป้าหมายในการทำการตลาดให้ใหม่ (กรณีมีการย้ายบ้าน เปลี่ยนงาน ตั้งครรภ์หรือเจ็บป่วยฉุกเฉิน) ซึ่งเทคนิคการตามหาแกะดำกลุ่มนี้ถูกเรียกว่าการทำ Anomaly Detection ที่สามารถทำได้หลายวิธีด้วยกัน เช่นการใช้ KNN เป็นต้น
Outlier Anomaly
Outlier คือข้อมูลที่มีความผิดปกติไปจากลุ่มข้อมูล ซึ่งมักจะเกิดจากความผิดพลาดจากการเก็บข้อมูลเอง (สามารถมองเป็น error ของข้อมูลได้) หรือเกิดจากเหตุการณ์ที่ไม่ปกติ เช่นข้อมูลยอดขายที่พุ่งสูงขึ้นเกินไปจากการคีย์ข้อมูลผิด หรือลูกค้าที่มาซื้อครั้งเดียวแล้วหายไปเลย หรือข้อมูลที่ไม่เกี่ยวข้องแต่กลับมีจำนวน Mentions และ Engagement สูงในการทำ Social Listening ของเราจากประเด็นข่าวต่างๆ ค่ะ
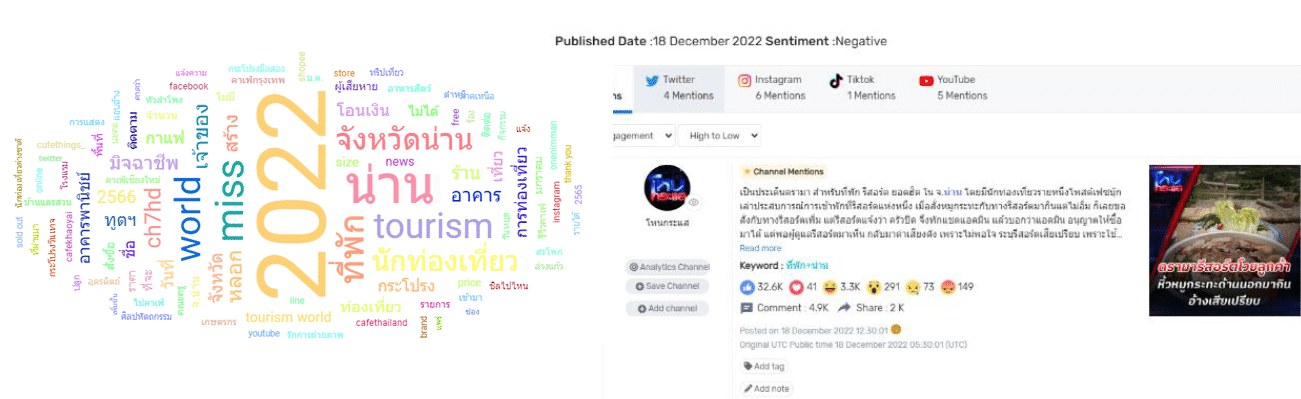
ซึ่งตัวเลขของข้อมูลเหล่านี้มักจะมีค่ามากกว่า หรือน้อยกว่าค่าของกลุ่มข้อมูลปกติมาก หรือมีความน่าจะเป็นที่จะเกิดขึ้นได้น้อยที่สุด โดยถ้าเรามองตามกราฟการกระจายตัวของข้อมูลแบบปกติมาตรฐาน ก็คือส่วนที่เป็นปลายของกราฟ ทั้งด้านหน้าและด้านหลังนั่นเองค่ะ
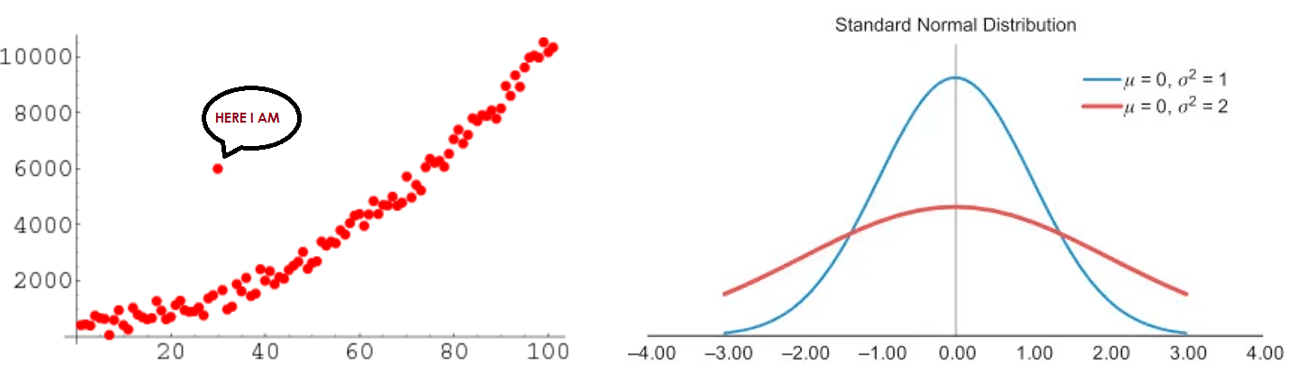
*Technical Term: การกระจายตัวของข้อมูลแบบปกติ (ที่เป็นรูประฆังคว่ำ) เป็นเพียงการแจกแจงแบบปกติ แต่ไม่ได้เป็น Standard Normal Distribution (การกระจายตัวแบบปกติมาตรฐาน) ในทุกชุดข้อมูล แต่จะเป็น Standard Normal Distribution ก็ต่อเมื่อมีค่าเฉลี่ยเลขคณิตเท่ากับค่ากึ่งกลางข้อมูลเท่ากับค่ามัธยฐานและมีค่าเป็น 0 และมีส่วนเบี่ยงเบนมาตรฐานเท่ากับ 1 เท่านั้น และเพื่อให้เห็นภาพชัดเจนมากขึ้น เราลองมาดูกราฟด้านบนนี้ไปพร้อมๆ กันค่ะ (ไม่ต้องซีเรียสเรื่องสัญลักษณ์ทางคณิตศาสตร์ที่อยู่ในภาพนะคะ) จะเห็นว่าเส้นสีแดงมีการกระจายตัวของข้อมูลมากกว่าเส้นสีน้ำเงิน (ค่าส่วนเบี่ยงเบนมาตรฐานของเส้นสีแดงมีค่าเท่ากับ 2) =>ใช่แล้วค่ะเส้นสีแดงมีไม่ถือเป็นข้อมูลที่เป็นการแจกแจงปกติมาตรฐาน แต่เป็นเพียงข้อมูลที่มีการแจกแจงแบบปกติเฉยๆ
นอกจากนี้เรายังสามารถใช้การสร้าง Box plot ในการพิจารณาข้อมูลที่หลุดออกมาเป็น Outlier อย่างชัดเจนจากกราฟการกระจายตัวของข้อมูลได้ด้วยค่ะ โดยส่วนที่เป็น Outlier คือส่วนที่เป็นจุดๆ นอกเหนือจากส่วน Box ของกราฟนั่นเอง
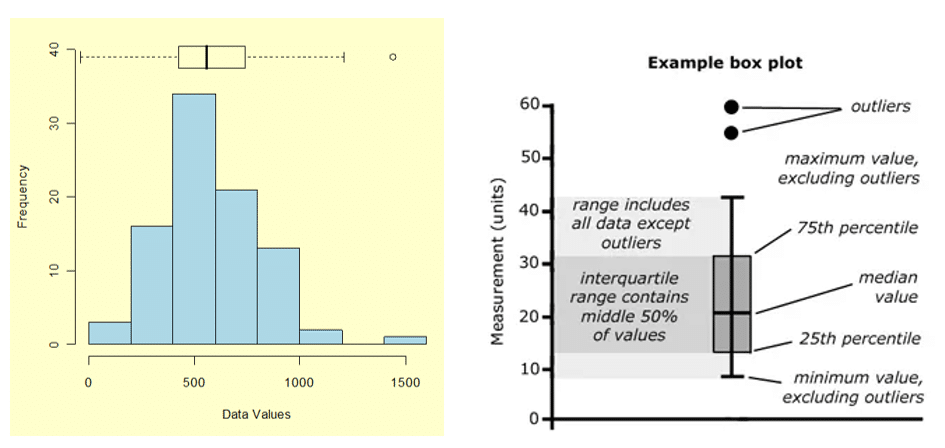
โดย Outlier ของข้อมูลถือเป็นหนึ่งในปัญหาที่จะเกิดขึ้นในขั้นตอนการทำ Data Preparation ที่หากพิจารณาแล้วไม่พบว่ามีนัยสำคัญ จะต้องทำการตัดเอาข้อมูลในส่วนนี้ออก เนื่องจากเป็นส่วนหนึ่งที่ทำให้มีการวิเคราะห์ผิดพลาด หรือถ้าจะนำไปสร้าง ML model ก็จะทำให้โมเดลที่ได้มามีความผิดเพี้ยน (Bias) ได้ ซึ่งยิ่งมีข้อมูลประเภทนี้ถูกนำมาใช้มากเท่าใด ก็จะส่งผลให้ตัวโมเดลหรือการนำข้อมูลไปวิเคราะห์ Insight ต่อ มีความคลาดเคลื่อนมากเท่านั้นค่ะ

Last but not Least…
Anomalies data คือข้อมูลที่มีความไม่ธรรมดาอย่างมีนัยสำคัญ เป็นแกะดำที่เราต้องเฝ้าดูอย่างพิเศษ เพราะสามารถหาความสัมพันธ์ของการเกิดเหตุการณ์หรือพฤติกรรมการซื้อแปลกๆ เหล่านั้น เพื่อหาโอกาสในการเข้าถึงลูกค้าได้ดีขึ้น/ทำ Campaign ที่ตอบโจทย์ขึ้น หรือป้องกันความเสียหายจากการละเมิด เป็นข้อมูลที่ไม่ควรตัดออก แต่ต้องเฝ้าดู
Outlier คือข้อมูลที่มีความน่าจะเป็นที่จะเกิดขึ้นได้น้อยที่สุด สืบเนื่องจาก Error ในการเก็บข้อมูล หรือเหตุการณ์ที่เกี่ยวข้องกับสิ่งที่เราต้องการวิเคราะห์ แต่ไม่ได้เกี่ยวเนื่องกันอย่างมีนัยสำคัญ หากนำมาวิเคราะห์ร่วมกับชุดข้อมูลหลัก อาจทำให้เกิดความคลาดเคลื่อนของการวิเคราะห์ เป็นข้อมูลที่จะต้องทำการตัดออก ในขั้นตอนของการทำ Data preparation ค่ะ^^
ปูลู: สำหรับการประยุกต์ใช้ของนักการตลาดที่ต้องทำการวิเคราะห์กลุ่มลูกค้าหลังจากทำ Data preparation ตัด Outlier ออกเรียบร้อยแล้ว สามารถลองนำข้อมูลที่ Clean เสร็จมาทำ Clustering หรือ Segmentation ได้ตามบทความต่อไปนี้เลยค่ะ 🐑🐑
คลาสเรียนออนไลน์ Social Listening Analytics รุ่นที่ 20 วันศุกร์ที่ 19 พฤษภาคม 2023 ค่าเรียนคนละ 9,900 รับจำกัด 20 คน อ่านรายละเอียดและลงทะเบียนได้ที่ลิงก์นี้ค่ะ https://bit.ly/sociallistening20




{kind=link}